搬运自速学堂:https://www.sxt.cn/Java_jQuery_in_action/ten-iqtechnology.html
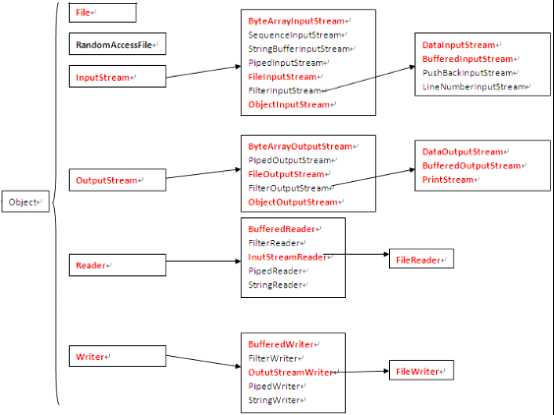
·InputStream
此抽象类是表示字节输入流的所有类的父类。InputSteam是一个抽象类,它不可以实例化。 数据的读取需要由它的子类来实现。根据节点的不同,它派生了不同的节点流子类 。
继承自InputSteam的流都是用于向程序中输入数据,且数据的单位为字节(8 bit)。
常用方法:
int read():读取一个字节的数据,并将字节的值作为int类型返回(0-255之间的一个值)。如果未读出字节则返回-1(返回值为-1表示读取结束)。
void close():关闭输入流对象,释放相关系统资源。
· OutputStream
此抽象类是表示字节输出流的所有类的父类。输出流接收输出字节并将这些字节发送到某个目的地。
常用方法:
void write(int n):向目的地中写入一个字节。
void close():关闭输出流对象,释放相关系统资源。
· Reader
Reader用于读取的字符流抽象类,数据单位为字符。
int read(): 读取一个字符的数据,并将字符的值作为int类型返回(0-65535之间的一个值,即Unicode值)。如果未读出字符则返回-1(返回值为-1表示读取结束)。
void close() : 关闭流对象,释放相关系统资源。
· Writer
Writer用于写入的字符流抽象类,数据单位为字符。
void write(int n): 向输出流中写入一个字符。
void close() : 关闭输出流对象,释放相关系统资源
FileInputStream通过字节的方式读取文件,适合读取所有类型的文件(图像、视频、文本文件等)。Java也提供了FileReader专门读取文本文件。
FileOutputStream 通过字节的方式写数据到文件中,适合所有类型的文件。Java也提供了FileWriter专门写入文本文件。
import java.io.*; public class TestIO2 { public static void main(String[] args) { FileInputStream fis = null; try { fis = new FileInputStream("d:/a.txt"); // 内容是:abc StringBuilder sb = new StringBuilder(); int temp = 0; //当temp等于-1时,表示已经到了文件结尾,停止读取 while ((temp = fis.read()) != -1) { sb.append((char) temp); } System.out.println(sb); } catch (Exception e) { e.printStackTrace(); } finally { try { //这种写法,保证了即使遇到异常情况,也会关闭流对象。 if (fis != null) { fis.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
import java.io.FileOutputStream; import java.io.IOException; public class TestFileOutputStream { public static void main(String[] args) { FileOutputStream fos = null; String string = "北京尚学堂欢迎您!"; try { // true表示内容会追加到文件末尾;false表示重写整个文件内容。 fos = new FileOutputStream("d:/a.txt", true); //该方法是直接将一个字节数组写入文件中; 而write(int n)是写入一个字节 fos.write(string.getBytes()); } catch (Exception e) { e.printStackTrace(); } finally { try { if (fos != null) { fos.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
void write(byte[ ] b),该方法不再一个字节一个字节地写入,而是直接写入一个字节数组;另外其还有一个重载的方法:void write(byte[ ] b, int off, int length),这个方法也是写入一个字节数组,但是我们程序员可以指定从字节数组的哪个位置开始写入,写入的长度是多少。
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class TestFileCopy { public static void main(String[] args) { //将a.txt内容拷贝到b.txt copyFile("d:/a.txt", "d:/b.txt"); } /** * 将src文件的内容拷贝到dec文件 * @param src 源文件 * @param dec 目标文件 */ static void copyFile(String src, String dec) { FileInputStream fis = null; FileOutputStream fos = null; //为了提高效率,设置缓存数组!(读取的字节数据会暂存放到该字节数组中) byte[] buffer = new byte[1024]; int temp = 0; try { fis = new FileInputStream(src); fos = new FileOutputStream(dec); //边读边写 //temp指的是本次读取的真实长度,temp等于-1时表示读取结束 while ((temp = fis.read(buffer)) != -1) { /*将缓存数组中的数据写入文件中,注意:写入的是读取的真实长度; *如果使用fos.write(buffer)方法,那么写入的长度将会是1024,即缓存 *数组的长度*/ fos.write(buffer, 0, temp); } } catch (Exception e) { e.printStackTrace(); } finally { //两个流需要分别关闭 try { if (fos != null) { fos.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fis != null) { fis.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
注意
在使用文件字节流时,我们需要注意以下两点:
1. 为了减少对硬盘的读写次数,提高效率,通常设置缓存数组。相应地,读取时使用的方法为:read(byte[] b);写入时的方法为:write(byte[ ] b, int off, int length)。
2. 程序中如果遇到多个流,每个流都要单独关闭,防止其中一个流出现异常后导致其他流无法关闭的情况。
前面介绍的文件字节流可以处理所有的文件,但是字节流不能很好的处理Unicode字符,经常会出现“乱码”现象。所以,我们处理文本文件,一般可以使用文件字符流,它以字符为单位进行操作。
import java.io.FileNotFoundException; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class TestFileCopy2 { public static void main(String[] args) { // 写法和使用Stream基本一样。只不过,读取时是读取的字符。 FileReader fr = null; FileWriter fw = null; int len = 0; try { fr = new FileReader("d:/a.txt"); fw = new FileWriter("d:/d.txt"); //为了提高效率,创建缓冲用的字符数组 char[] buffer = new char[1024]; //边读边写 while ((len = fr.read(buffer)) != -1) { fw.write(buffer, 0, len); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { if (fw != null) { fw.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fr != null) { fr.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
Java缓冲流本身并不具有IO流的读取与写入功能,只是在别的流(节点流或其他处理流)上加上缓冲功能提高效率,就像是把别的流包装起来一样,因此缓冲流是一种处理流(包装流)。
当对文件或者其他数据源进行频繁的读写操作时,效率比较低,这时如果使用缓冲流就能够更高效的读写信息。因为缓冲流是先将数据缓存起来,然后当缓存区存满后或者手动刷新时再一次性的读取到程序或写入目的地。
因此,缓冲流还是很重要的,我们在IO操作时记得加上缓冲流来提升性能。
BufferedInputStream和BufferedOutputStream这两个流是缓冲字节流,通过内部缓存数组来提高操作流的效率。
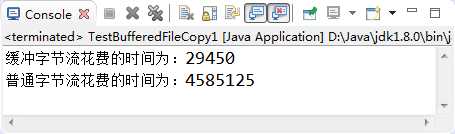
下面我们通过两种方式(普通文件字节流与缓冲文件字节流)实现一个视频文件的复制,来体会一下缓冲流的好处。
使用缓冲流实现文件的高效率复制
import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class TestBufferedFileCopy1 { public static void main(String[] args) { // 使用缓冲字节流实现复制 long time1 = System.currentTimeMillis(); copyFile1("D:/电影/华语/大陆/尚学堂传奇.mp4", "D:/电影/华语/大陆/尚学堂越 "+"来越传奇.mp4"); long time2 = System.currentTimeMillis(); System.out.println("缓冲字节流花费的时间为:" + (time2 - time1)); // 使用普通字节流实现复制 long time3 = System.currentTimeMillis(); copyFile2("D:/电影/华语/大陆/尚学堂传奇.mp4", "D:/电影/华语/大陆/尚学堂越 "+"来越传奇2.mp4"); long time4 = System.currentTimeMillis(); System.out.println("普通字节流花费的时间为:" + (time4 - time3)); } /**缓冲字节流实现的文件复制的方法*/ static void copyFile1(String src, String dec) { FileInputStream fis = null; BufferedInputStream bis = null; FileOutputStream fos = null; BufferedOutputStream bos = null; int temp = 0; try { fis = new FileInputStream(src); fos = new FileOutputStream(dec); //使用缓冲字节流包装文件字节流,增加缓冲功能,提高效率 //缓存区的大小(缓存数组的长度)默认是8192,也可以自己指定大小 bis = new BufferedInputStream(fis); bos = new BufferedOutputStream(fos); while ((temp = bis.read()) != -1) { bos.write(temp); } } catch (Exception e) { e.printStackTrace(); } finally { //注意:增加处理流后,注意流的关闭顺序!“后开的先关闭!” try { if (bos != null) { bos.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (bis != null) { bis.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fos != null) { fos.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fis != null) { fis.close(); } } catch (IOException e) { e.printStackTrace(); } } } /**普通节流实现的文件复制的方法*/ static void copyFile2(String src, String dec) { FileInputStream fis = null; FileOutputStream fos = null; int temp = 0; try { fis = new FileInputStream(src); fos = new FileOutputStream(dec); while ((temp = fis.read()) != -1) { fos.write(temp); } } catch (Exception e) { e.printStackTrace(); } finally { try { if (fos != null) { fos.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fis != null) { fis.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
执行结果如图:
注意
1. 在关闭流时,应该先关闭最外层的包装流,即“后开的先关闭”。
2. 缓存区的大小默认是8192字节,也可以使用其它的构造方法自己指定大小。
BufferedReader/BufferedWriter增加了缓存机制,大大提高了读写文本文件的效率,同时,提供了更方便的按行读取的方法:readLine(); 处理文本时,我们一般可以使用缓冲字符流。
使用BufferedReader与BufferedWriter实现文本文件的复制
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class TestBufferedFileCopy2 { public static void main(String[] args) { // 注:处理文本文件时,实际开发中可以用如下写法,简单高效!! FileReader fr = null; FileWriter fw = null; BufferedReader br = null; BufferedWriter bw = null; String tempString = ""; try { fr = new FileReader("d:/a.txt"); fw = new FileWriter("d:/d.txt"); //使用缓冲字符流进行包装 br = new BufferedReader(fr); bw = new BufferedWriter(fw); //BufferedReader提供了更方便的readLine()方法,直接按行读取文本 //br.readLine()方法的返回值是一个字符串对象,即文本中的一行内容 while ((tempString = br.readLine()) != null) { //将读取的一行字符串写入文件中 bw.write(tempString); //下次写入之前先换行,否则会在上一行后边继续追加,而不是另起一行 bw.newLine(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { if (bw != null) { bw.close(); } } catch (IOException e1) { e1.printStackTrace(); } try { if (br != null) { br.close(); } } catch (IOException e1) { e1.printStackTrace(); } try { if (fw != null) { fw.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fr != null) { fr.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
注意
1. readLine()方法是BufferedReader特有的方法,可以对文本文件进行更加方便的读取操作。
2. 写入一行后要记得使用newLine()方法换行。
原文:https://www.cnblogs.com/zhzhlong/p/11420084.html