说明:elasticsearch查询结果是根据什么排序的呢?答案是根据相关性得分的高低来排序,本篇着重说明elasticsearch打分机制背后的理论。
主要是翻译自elasticsearch官方文档,官方文档地址如下:
相关性打分背后的理论:https://www.elastic.co/guide/en/elasticsearch/guide/current/scoring-theory.html
相关性打分权重修正图解:https://www.elastic.co/guide/en/elasticsearch/guide/current/boosting-by-popularity.html
以上是选取了2个章节的链接,感兴趣的话,可以点进去选择其他相关性打分章节翻看,这里不一一列出了。
布尔模型简单的在查询中运用“and”、“or”、“not”表达条件去找到所有匹配的文档。
这个过程简单快捷。它用于排除任何可能与查询不匹配的文档。一个文档是否可以查询到,就是根据布尔模型判断的。
1、词频计算
一个词有多频繁?我们希望更频繁的词有跟高的权重,一个字段中出现5词肯定比1次更有多的相关性,词频的计算公式如下:
tf(t in d) = √frequency
公式解释:在文档中词t的词频是文档中出现次数的数值得平方根。
如果不想关注一个词在字段中出现的频率,只是想关注这个词是否是存在的,那么可以在字段的映射中可以禁用。禁用词频将会禁用词频和词的位置,不能统计一个词在字段中出现的次数,不能做短语和邻近性查询。设置为not_analyzed的字符串字段默认是这个设置。
2、反向文档频率计算
在集合所有的文档中出现的越频繁权重越低,比如常见的词“和”、“那”,“的”等,应该有更小的相关性,因为他们出现在几乎许多的文档当中,而不太常见的词,如“青蒿素”,“比例”可以帮助我们放大我们感兴趣文档的权重。反向文档词频计算公司如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
解释:反向文档的词频是索引中文档的数量除以包含词的文档数的对数再加1。
3、字段文本长度范数计算
字段文本更短的长度有更高的权重,假如一个词出现在一个短文本的字段,比如title,那么更有可能是词与该字段内容有关,而不是一个更大的body字段。
norm(d) = 1 / √numTerms
字段长度范数是在字段中词的个数的平方根的相反数。
对于全文搜索来讲字段长度范数是重要的,但是对于许多其他字段是不需要的。无论文档中是否包含该字段,索引中每个文档的每个字符串类型字段范数将消耗大约1个字节。not_analyzed设置的字符串字段默认范数是禁用的,在设置analyzed的字段也可以设置禁用范数。被禁用范数的字段,将不会让字段长度范数参与计算,一个长文本的字段和一个短文本的字段被打分,就像他们长度是相同的一样。比如日志类型,范数是没有用的,所关注的是 是否包含一个精确的错误码或者一个精确的浏览标记,字段的长度不会影响到结果。禁用规范可以节省大量内存。
4、以上条件结合
三个因子——词频、反向文档词频、字段长度范数——在索引时被用来计算和打分,它们用于计算特定文档中单个词的权重。在上面的公司中,我们涉及的文档实际谈论的是文档中一个字段。每个字段有它自己的倒排索引,因此对于IF/IDF作用来讲文档的值就是字段的值。当我们使用一个简单的词查询时,您将看到,计算分数所涉及的唯一因素是前面几节所解释的因素:
PUT /my_index/doc/1
{
"text" : "quick brown fox"
}
GET /my_index/doc/_search?explain
{
"query": {
"term": {
"text": "fox"
}
}
}
前面请求得分的简短解释如下:
eight(text:fox in 0) [PerFieldSimilarity]: 0.153426411
result of:
fieldWeight in 0 0.15342641
product of: tf(freq=1.0), with freq of 1: 1.02
idf(docFreq=1, maxDocs=1): 0.306852823
fieldNorm(doc=0): 0.54
1——在这个文档的text字段中词“fox”的最终得分
2——在这个文档的text字段中词“fox”出现一次
3——在这个索引的所有文档的text字段的反向文档词频,这里强调下对数的底数是自然数e
4——这个字段的字段长度归一化因子。这里索引中词只有3个,按照计算公式应该有4个,还有一个应该是范数在字段中占用了一个字节
通常查询是包含多个词的,因此我们需要一种将多个词的权重结合起来的方法,为此我们转向向量空间模型
5、向量空间模型
向量空间模型提供了一种将多词查询与文档进行比较的方法。输出是一个得分,表示文档与查询的匹配程度。为了做到这一点,模型将文档和查询表示为向量。一个向量实际只是一个包含数字的一维数组,例如:
[1,2,5,22,3,8]
在向量空间模型中,在向量中的每一个数字是一个词的权重。对于向量空间模型,TF/IDF是计算词权重的默认方式,这个不是仅有的方式,在elasticsearch中存在其他的模型如Okapi-BM25。TF/IDF是默认的,因为它是一种简单、高效的算法,能够产生高质量的搜索结果,并且经得起时间的考验。想象一下,我们有一个关于“happy hippopotamus”的查询。像““happy”这样的普通词会有较低的权重,而像“hippopotamus”这样不常见的词则会有更高的权重。让我们假设“happy”的权重是2,“hippopotamus”的权重是5。我们可以把这个简单的二维向量[2,5]画成一条从点(0,0)开始,以点(2,5)结束的线。如图所示:
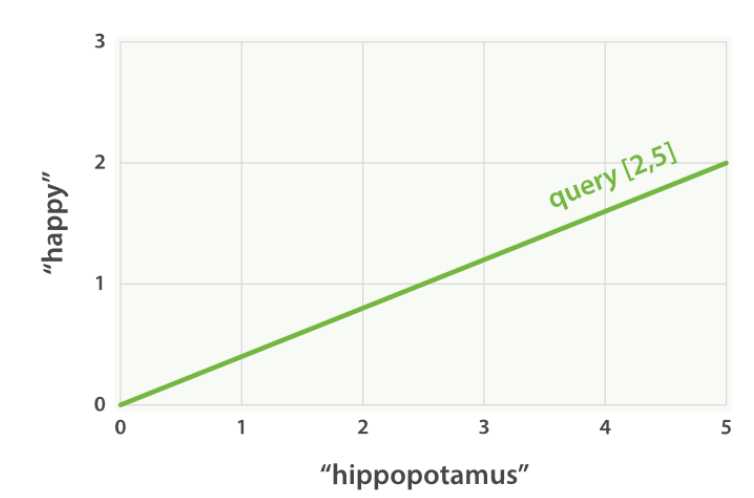
现在,想象一下我们有三份文件:
1/I am happy in summer.
2/After Christmas I’m a hippopotamus.
3/The happy hippopotamus helped Harry.
我们可以为每个文档创建一个类似的向量,包括每个出现在文档中查询词(happy和hippopotamus)的权重 ,并在相同的图上绘制这些向量,如图所示:
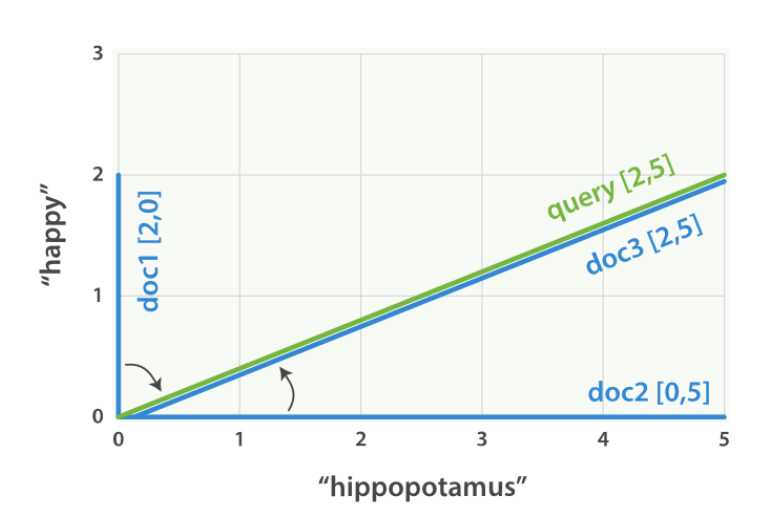
矢量的好处是它们可以被比较。通过测量查询向量和文档向量之间的角度,可以为每个文档分配一个相关性评分。文档1和查询之间的角度很大,所以相关性很低。文档2更接近查询,这意味着它是合理相关的,而文档3是一个完美的匹配。实际上,只有二维向量(带有两个词的查询)才能很容易地在图上绘制。幸运的是,线性代数-处理向量的数学分支-提供了比较多维向量之间角度的工具,这意味着我们可以将上面解释的相同原理应用于包含多个词的查询。
对于多词查询,Lucene采用布尔模型、TF/IDF和向量空间模型,并将它们合并到一个有效的包中,该包收集匹配的文档,并在执行过程中对它们进行评分。先会对查询条件进行分词拆分,然后用布尔模型查找符合条件的文档。文档一旦匹配查询,Lucene就会计算该查询的分数,并将每个匹配词的分数结合起来。
实用打分函数如下:
score(q,d) =1
queryNorm(q)2
· coord(q,d)3
· ∑ (4
tf(t in d)5
· idf(t)²6
· t.getBoost()7
· norm(t,d)8
) (t in q)9
1——对于查询文档的相关性得分
2——查询归一化因子
3——协调因子
4, 9——在查询文档中每个词t的权重之和
5——文档中的词频
6——词的反向文档词频
7——应用于查询的权重提升参数boost
8——时间长度范数,如果有的话,结合索引时字段等级的boost提升权重。
1、查询归一化因子计算
查询归一化因子(QueryNorm)是对查询进行标准化的尝试,以便将一个查询的结果与另一个查询的结果进行比较。查询规范的目的是使不同查询的结果具有可比性。相关性打分的唯一目的是按照正确的顺序对当前查询的结果进行排序。您不应该尝试比较来自不同查询的相关性分数。
此因子是在查询开始时计算的。实际计算取决于所涉及的查询,但典型的实现如下:
queryNorm = 1 / √sumOfSquaredWeights
sumOfSquaredWeights是在查询中每个词的IDF的平方被加在一起。
2、协调因子
协调因子是用于奖励包含查询词更高百分比的文档的。文档中出现的查询词越多,文档与查询的良好匹配可能性就越大。
想象以下我们有个查询“quick brown fox”,每个词的权重是1.5,在不考虑协调因子的情况下,在文档中得分将仅仅是每个词的权重之和,比如:
文档有 fox → score: 1.5
文档有 quick fox → score: 3.0
文档有 quick brown fox → score: 4.5
协调因子将得分乘以文档中的匹配词数,再除以查询中的词的总数。就协调因素而言,得分如下:
文档有 fox → score: 1.5 * 1 / 3 = 0.5
文档有 quick fox → score: 3.0 * 2 / 3 = 2.0
文档有 quick brown fox → score: 4.5 * 3 / 3 = 4.5
协调因子导致包含所有三个词的文档比只包含其中两个词的文档更相关。
布尔查询默认情况下对所有应子句使用查询协调。但它允许您禁用协调。为什么要这样做?通常答案是,你不用这么做。查询协调通常是件好事。当您使用bool查询去包含多个高级查询(如匹配查询)时,弃用协调激活也是有意义的。匹配的子句越多,搜索请求与返回的文档之间的重叠程度就越高。无论如何,在某些高级用例中,禁用协调可能是有意义的。想象一下,你正在寻找同义词jump, leap, 和 hop。您不关心这些同义词中有多少存在,因为它们都代表相同的概念。事实上,只有一个同义词可能存在。这将是禁用协调因素的好情况:
3、索引时字段等级提升
我们将讨论如何提升一个字段权重-使其比其他字段更重要,在查询时间提升。还可以在索引时对字段应用Boost。实际上,这种提升权重适用于字段中的每一个词,而不是字段本身。在索引中存储这个Boost值不需要占用更多的空间,这个字段等级在索引时Boost与字段长度范数组合在一起,并作为一个字节存储在索引中。这是由上一公式中的norm(t,d)返回的值。
注意:出于以下几个原因,我们强烈建议不要使用字段级权重索引时增强。
1)将Boost与字段长度范数结合起来,并将其存储在一个字节中,就意味着字段长度范数失去了精度。结果是ElasticSearch无法区分包含三个单词的字段和包含五个单词的字段。
2)若要更改索引时提升的权重,必须重新编制所有文档的索引。另一方面,查询时的提升权重可以随每个查询而改变.
3)如果一个具有具有多个值的字段索引时Boost提升权重,则对每个值都会将该值乘以该字段本身,从而显着地增加了该字段的权重。
4、查询时提升权重
索引时提升权重是不建议的,查询时提升权重就更有用了。
查询时如果没有指定boost提升权重,那么默认因子是1。
查询提升权重参数被运用于Lucene的实用打分函数的t.getBoost()元素。
事实上,读取解释输出要稍微复杂一些。您将完全看不到解释中提到的Boost值或t.getBoost()。相反,Boost被滚动到适用于特定词的queryNorm中。虽然我们说过,每个词的queryNorm都是相同的,但是您将看到,对于一个提升权重的词,queryNorm要比对于一个未加权重提升的词的queryNorm要高。
5、通过人望提升权重
想象一下,我们有一个推送博客的网站,让用户可以投票支持他们喜欢的博客帖子。我们希望在结果列表中出现更多受欢迎的帖子,但仍将全文分数作为主要相关性驱动。通过存储每个博客帖子的投票次数,我们可以轻松地做到这一点。
在搜索时,我们可以使用function_Score查询和field_value_factor函数将票数与全文关联评分结合起来:
GET /blogposts/post/_search
{
"query": {
"function_score": {1
"query": {2
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {3
"field": "votes"4
}
}
}
}
1——function_score查询包含主查询和我们希望应用的函数
2——首先执行主查询。
3——field_value_factor函数应用于每个匹配主查询的文档
4——每个文档必须在votes字段中有一个数字才能使function_Score工作
在前面的示例中,每个文档的最终得分已更改如下:
new_score = old_score * number_of_votes
我们希望0票和1票之间的差额要比10票和11票之间的差额大很多,修正公式如下:
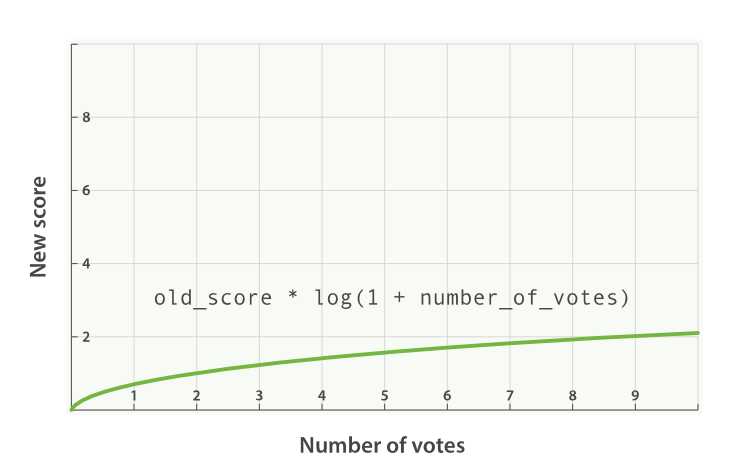
new_score = old_score * log(1 + number_of_votes)
log函数平滑选票字段的效果,如图所示:
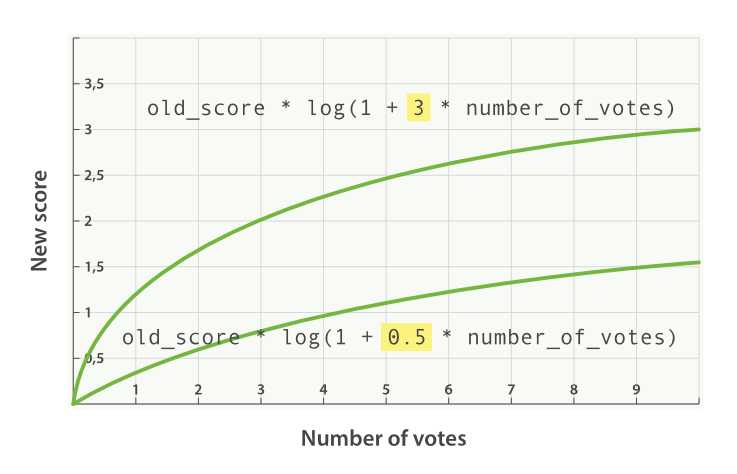
添加一个因子会将公式更改为
new_score = old_score * log(1 + factor * number_of_votes)
效果如下图所示:
权重提升模式(boost_mode)修改,boost_mode支持的模式有如下:
multiply ——这个是默认模式,相关性分数乘以函数修正分数
sum ——相关性分数与函数分数之和
min ——取相关性分数与函数分数更低的那个
max ——取相关性分数与函数分数更高的那个
replace ——函数分数替换相关性分数
如果设置为sum,则打分公式如下:
new_score = old_score + log(1 + 0.1 * number_of_votes)
如下图所示:
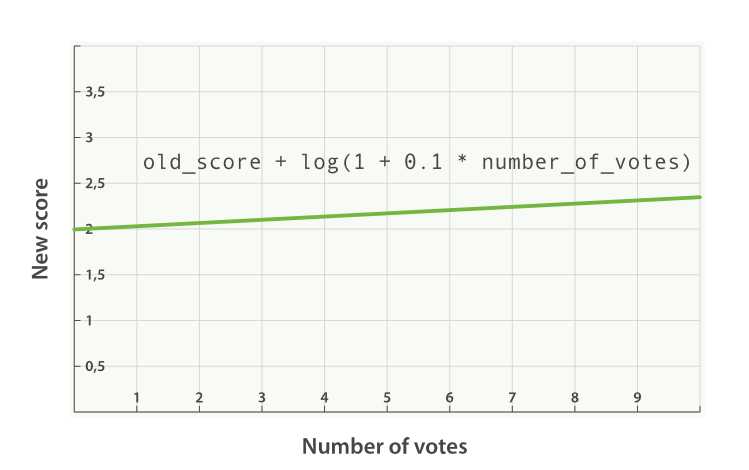
最后,我们可以通过使用max_boost参数来限制函数可以具有的最大效果,如果设置——"max_boost": 1.5, 无论Field_Value_Factor函数的结果如何,都将永远不大于1.5。
最相关的概念是要击中的模糊目标,不同的人对文档排序常常有不同的看法。在没有任何明显进展的情况下,容易陷入不断变化的循环中。
我们鼓励你避免这种(非常诱人)的行为,而不是适当地测量你的搜索结果。监视用户单击顶部结果、前10页和第一页的频率;他们在不首先选择结果的情况下执行辅助查询的频率;单击结果并立即返回搜索结果的频率等等。
我们鼓励你避免这种(非常诱人)的行为,而不是适当地测量你的搜索结果。监视用户单击顶部结果、前10页和第一页的频率;他们在不首先选择结果的情况下执行辅助查询的频率;单击结果并立即返回搜索结果的频率等等。
本章概述的工具只是:工具。您必须适当地使用它们来推动您的搜索结果进入优秀的类别,而唯一的方法就是对用户行为进行强有力的度量。
相关文章:使用logstash同步mysql数据到elasticsearch 、ik与拼音分词器,拓展热词/停止词库
技术合作:
qq:281414283
微信:so-so-life
原文:https://www.cnblogs.com/javato/p/11385362.html