整个启动流程会启动前端cql server用来接收客户端cql请求,启动node互相通信用的MessageService。这个都是常规操作,就不花费篇幅赘述了。cassandra启动过程对于新节点加入还是正常启动还是有区分的,新节点会造成数据重分布,所以需要先执行bootstrap。
先看下cassandra cluster的分区概念。下面这个例子中表示,token组成了一个环,由这4台节点划分,每个server管理一段。所有key值都通过murmur3算法算出token,映射在hash环上,从而找到所属server

当有新节点加入集群后,新节点会新分配token,会管理新增部分tokenRange,相当于从老节点分割了token,从而引起了数据迁移
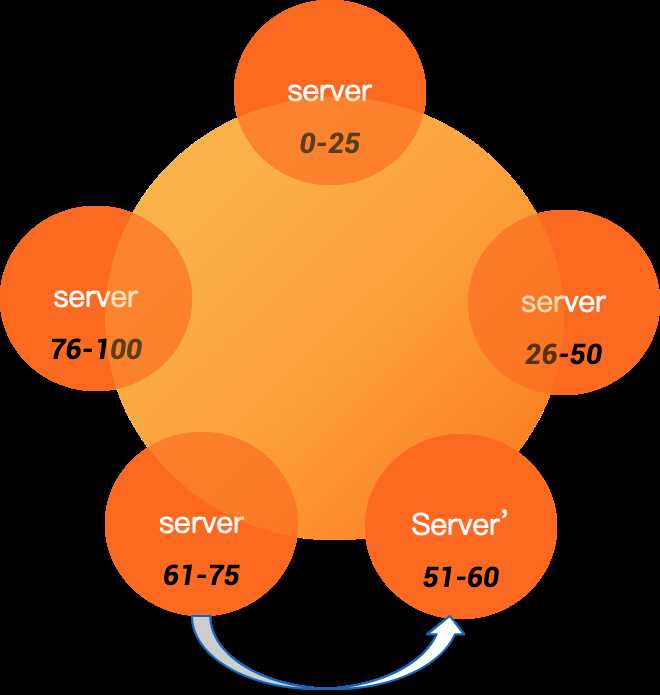
上图中server‘新加入集群,负责了token范围(51-60),原来管理的server管理token的范围为(51-75),server‘在加入集群前,需要先把数据拷贝过来,防止加入后,读数据失败。这其实就是bootstrap过程,原理很简单,但实际因为虚拟节点vnode存在,实现要比这复杂的多。
下面是启动过程中比较重要的几个步骤
replay WAL
JoinRing
原文:https://www.cnblogs.com/baiwuya23/p/11425067.html