一.搜索、匹配与查找数据
现有的许多不同类型 的技术系统,如关系型数据库、键值存储、操作磁盘文件的map-reduce【映射-规约】引擎、图数据库等,都是为了帮助用户解决颇具挑战性的数据存储与检索问题而设计的。而搜索引擎,尤其是Solr,致力于解决一类特定的问题:搜索大量非结构化的文本数据,并返回最相关的搜索结果。
1.文档
Solr是一个文档存储与检索引擎。提交给solr处理的每一份数据都是一个文档。文档可以是一篇新闻报道、一份简历、社交用户信息,甚至是一本书。
每个文档包含一个或多个字段,每个字段被赋予具体的字段类型:字符串、标记化文本、布尔值、日期/时间、经纬度等。潜在的字段类型数量是无限的,因为一个字段类型是有若干个分析步骤组成的,这些步骤会决定数据如何在字段中被处理,以及如何映射到Solr索引中。每个字段在solr的schema文件中被指定特定的字段类型,并告知solr接收到此类内容的处理办法。
如下:
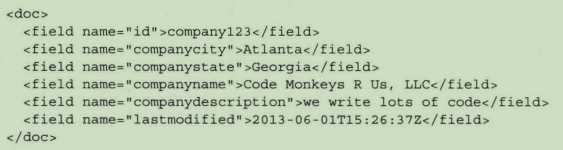
要在solr上执行一个查询,可以在文档上搜索一个或多个字段,即使字段未包含在该文档中。solr将返回哪些包含了与查询匹配的字段内容的文档。值得注意的是,虽然solr为每个文档提供了一个灵活的schema文件,但灵活并不代表无模式。在solr的schema文件中,所有的字段必须被定义,所有的字段名称【包括动态字段命名模式】必须被指定类型。这并不意味着每个文档必须包含所有字段,仅当所有可能的字段出现在一个文档中需要处理时,才会被全部映射到特定字段类型中。当首次接收到包含新字段的文档时,solr会自动猜测未知的新字段类型。通过检查字段中的数据类型,自动将字段增加到solr的schema中。如果输入的数据难以理解,solr可能会对字段类型识别失败,因此,更好的做法是预先定义好字段类型。
原文:https://www.cnblogs.com/yszd/p/11426305.html