Here is a program that reads a file and builds a histogram of the words in the file:

process_file loops through the lines of the file, passing them one at a time to process_line. The histogram h is being used as an accumulator. process_line uses the string method replace to replace hyphens with spaces before using split to break the line into a list of strings. It traverses the list of words and uses strip and lower to remove punctuation and convert to lower case. (It is a shorthand to say that strings are ‘converted;’ remember that string are immutable, so methods like strip and lower return new strings.)
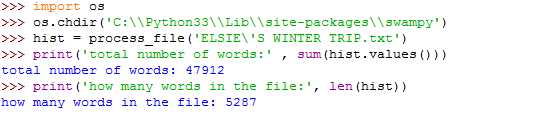
Finally, process_line updates the histogram by creating a new item incrementing an existing one. To count the total number of words in the file, we can add up the frequencies in the histogram:
from Thinking in Python
原文:http://www.cnblogs.com/ryansunyu/p/3917789.html