1.re正则
import re
print(re.findall("\w","内容"))
findall 返回的是列表
\w 匹配字母,数字,下划线,中文
\W 匹配不是字母,数字,下划线,中文
\d 匹配数字
\D 匹配非数字
^(\A) 匹配以什么开头
$ (\Z) 匹配以什么结尾
.(点) 匹配任意一个字符串(一个点只能匹配一个)(\n除外)
print(re.findall("a.c","abc,aec,a\nc,a,c",re.DOTALL)) 可以匹配包括\n在内的任意一个字符串
[...] 匹配字符组中的字符
print(re.findall('[0-9]',"alex123,日魔dsb,小黄人_229")) 可以匹配0-9以内的数字(包括0和9)
print(re.findall('[a-z]',"alex123,日魔DSB,小黄人_229")) 可以匹配所有的小写字母
print(re.findall('[A-Z]',"alex123,日魔DSB,小黄人_229")) 可以匹配所有的大写字母
[^0-9] 取非 0-9之间的数字
print(re.findall("[^0-9a-z]","123alex456")) 匹配非0-9之间的数字和小写字母
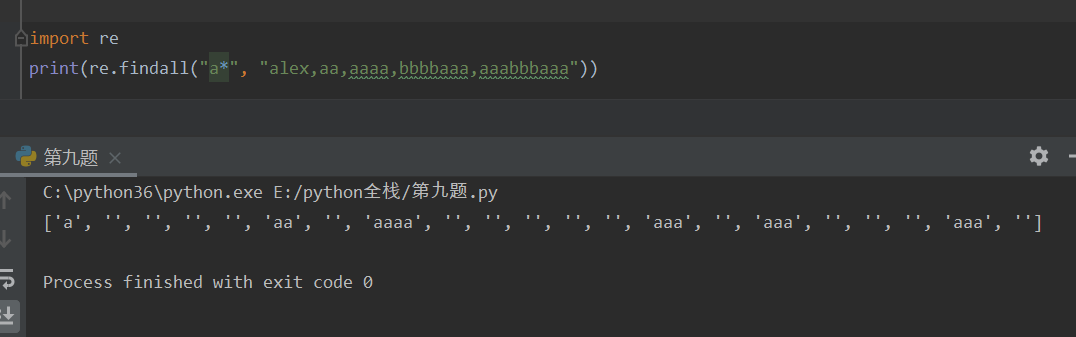
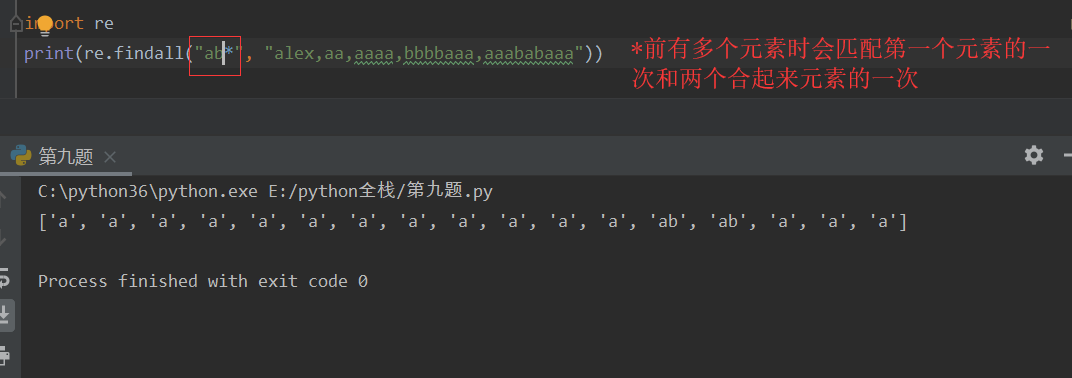
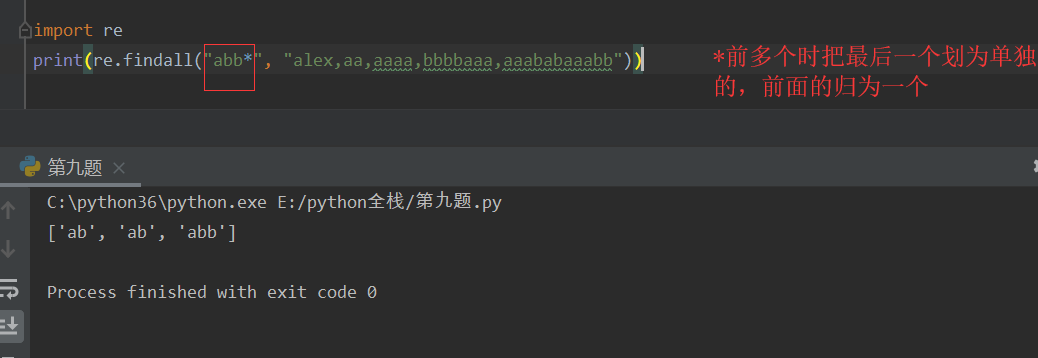
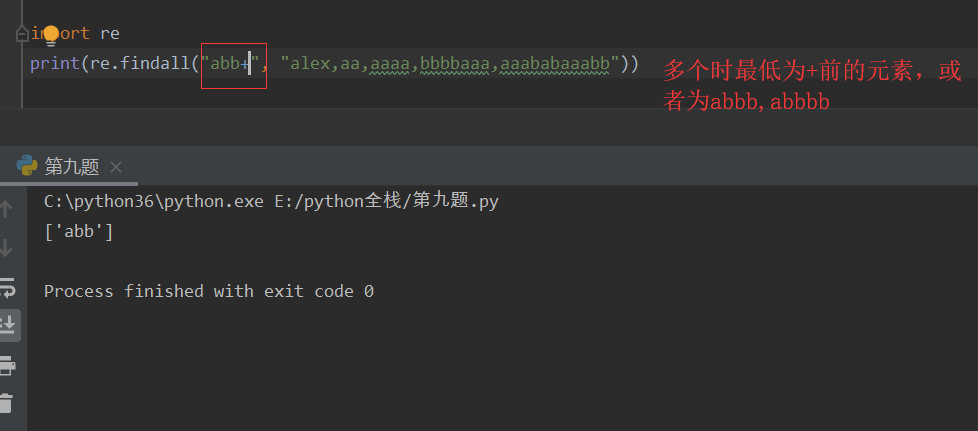
*(星) 匹配 *左侧字符串0次或多次,贪婪匹配
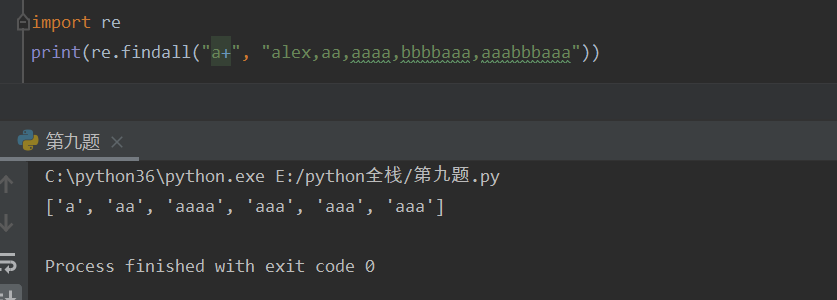
+(加号) 匹配+左侧字符串一次或多次,贪婪匹配
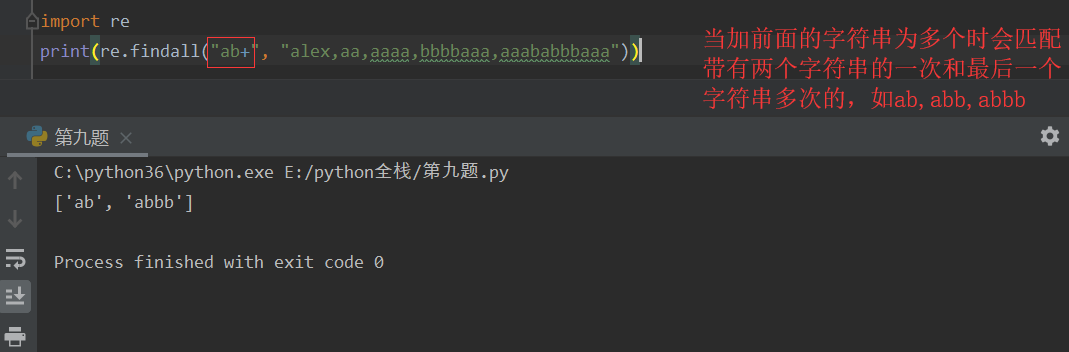
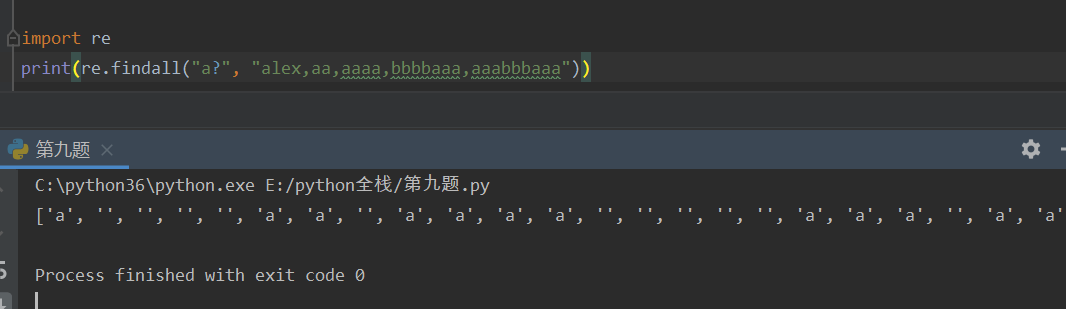
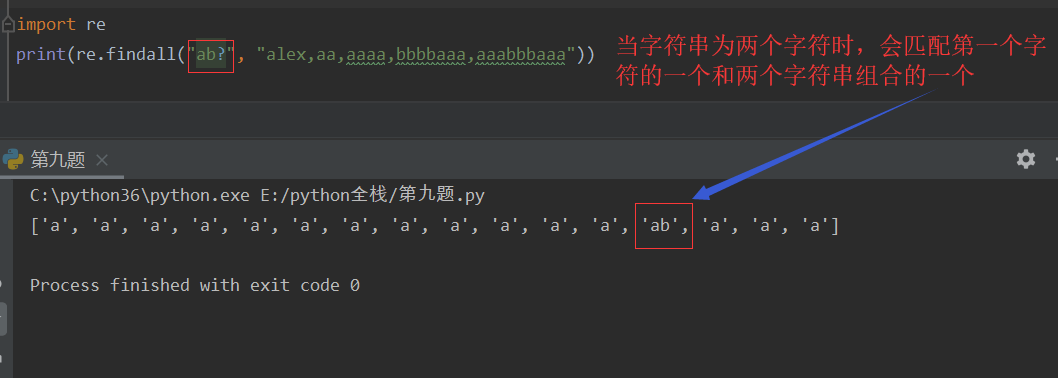
? 匹配?左侧0或1个字符串 非贪婪匹配
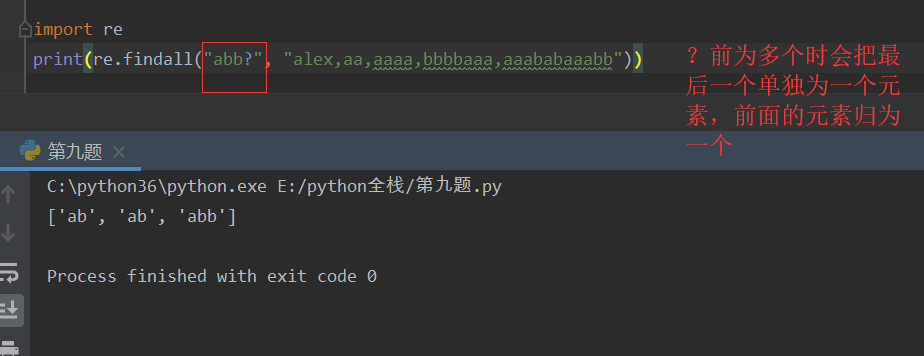
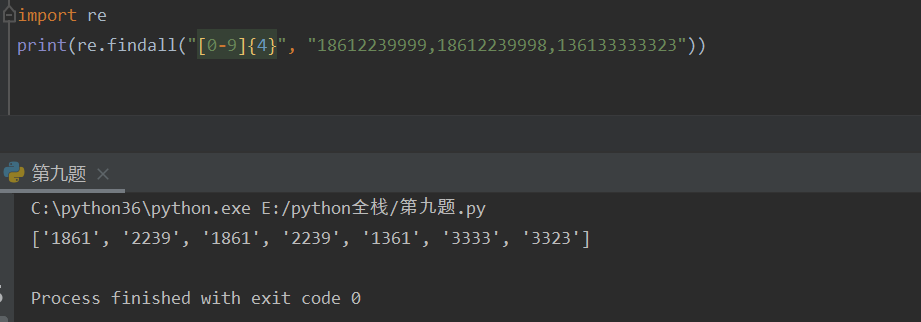
{n} 指定匹配元素的个数
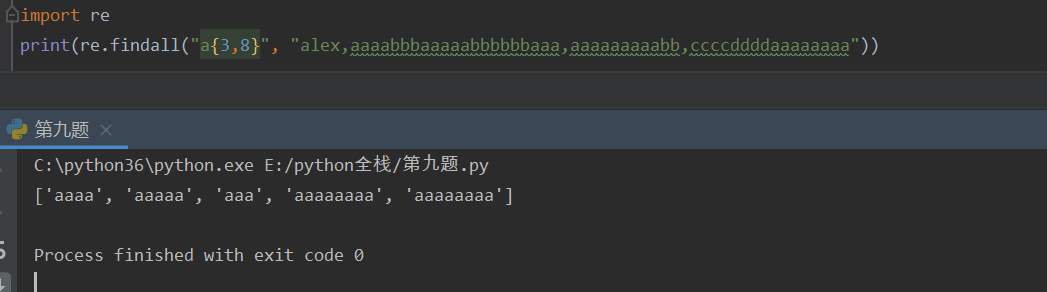
{n,m} 指定匹配元素个数为n-m(包括n和m)区间
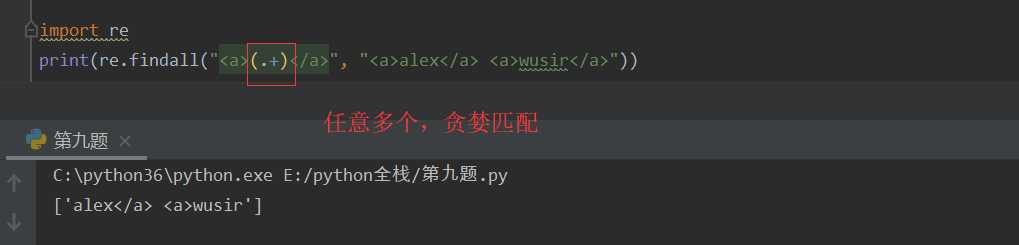
() 分组,匹配括号内的表达式
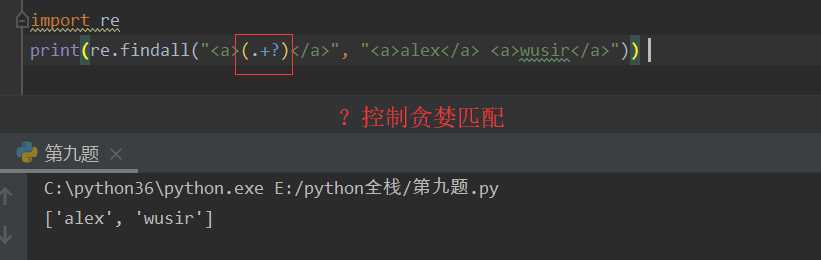
?: 可以把()外面的一块匹配
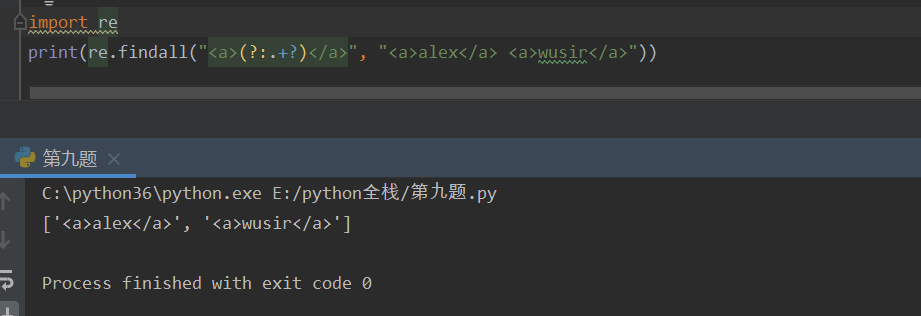
可以直接匹配字符串

\s 匹配任意空白符

\S 匹配任意非空白符
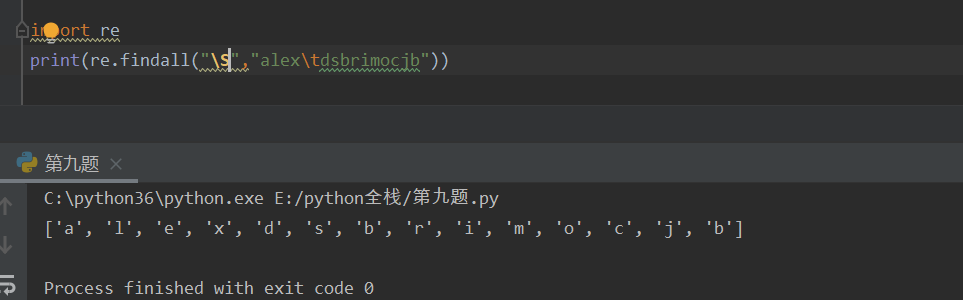
把-(负号)放在前面可以匹配到-(负号)
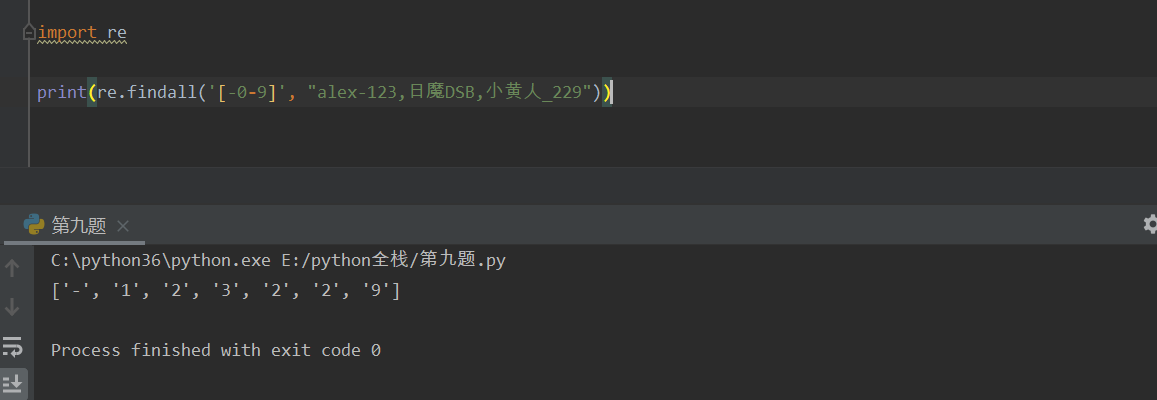
a|b 匹配a或者b
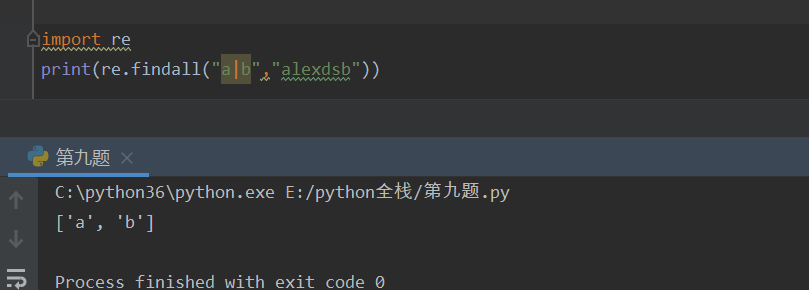
search 和 match 区别
search 从任意位置开始查找
match 从头开始查看,如果不符合就不继续查找了
返回的是一个对象
group()进行查看
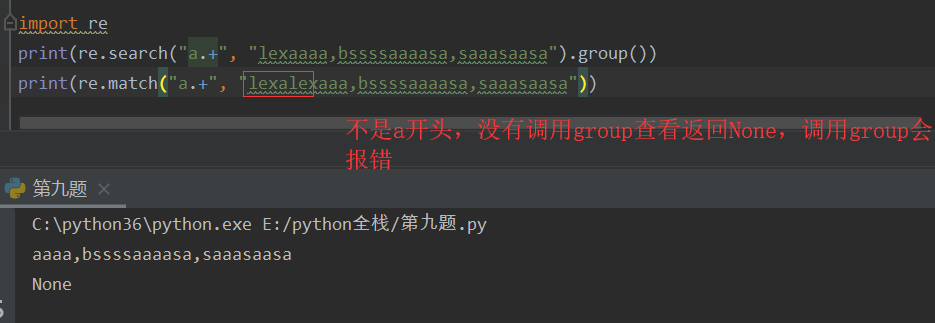
split 分割
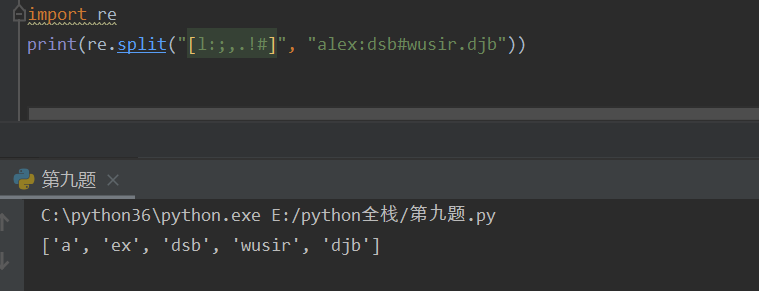
sub 替换
compile 定义匹配规则
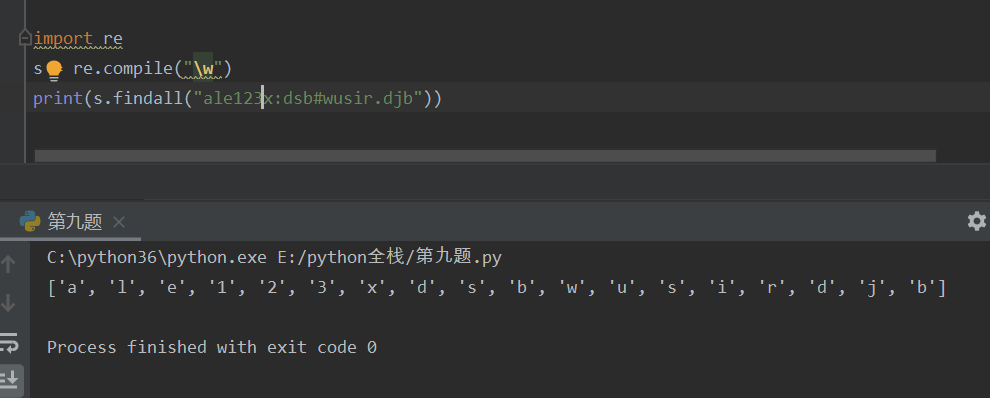
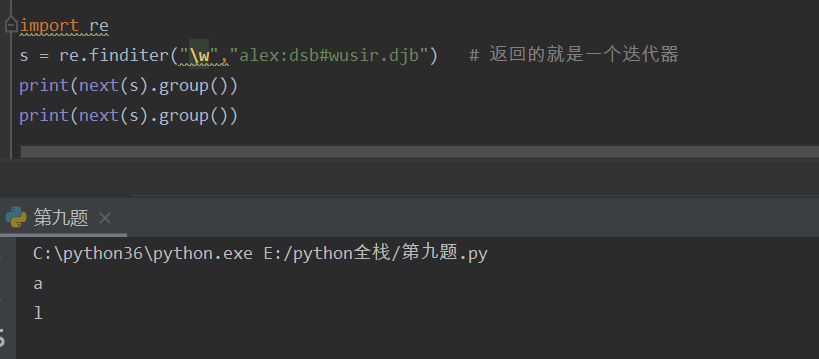
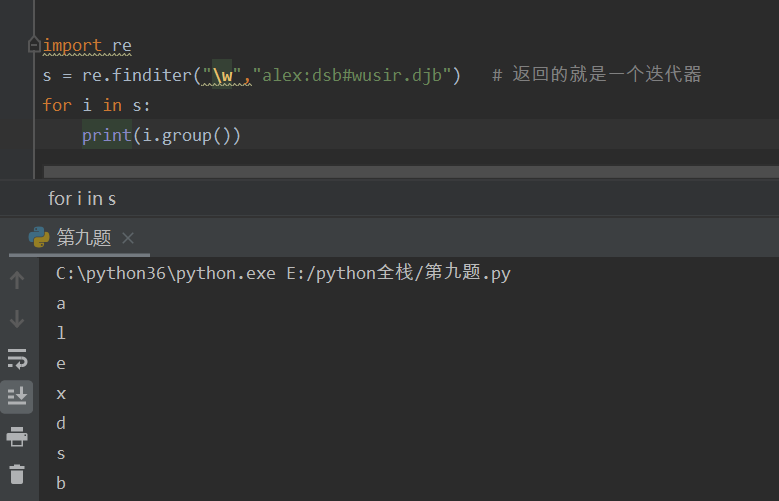
finditer 返回一个迭代器
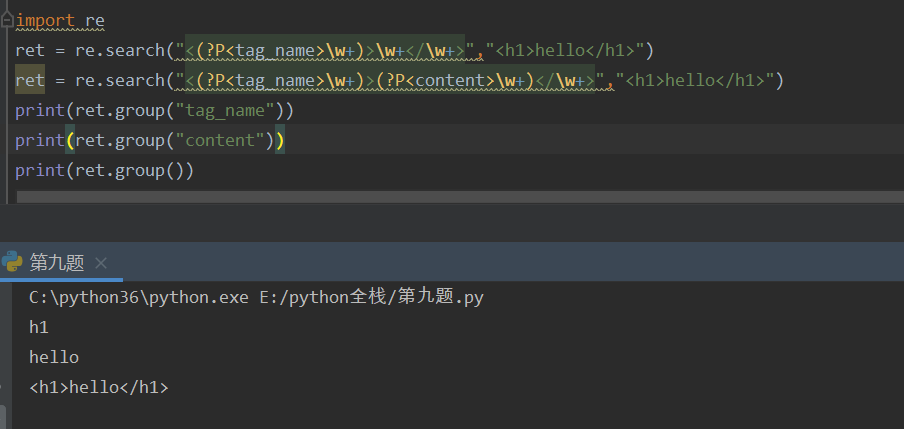
给分组命名(?P 给分组命名)
\. 转义成真正的.
扩展:[\u4e00-\u9fa5]+ unicode中中文的开始和结束,可以只匹配中文2.包
作用:管理模块(文件化)
文件夹下具有__init__.py的就是一个包
bake(包)
api(包)
__init__.py
es.py
mt.py
__init__.py
指定功能导入
import 模式
import bake
bake.api.es 不能用
import bake.api.es
bake.api.es.func() 可以用
名字太长,可以通过as改名
import 后边可以用点操作 点前必须是包
from import 模式
from bake import api
api.es.func() 不能用
from bake.api import es
es.func()
from back.api.es import func
func() 可以用
from import -- import后面不能带点操作
(back,api都是包,es是模块)
导入模块中的全部
import 模式
在bake包下的__init__.py
from . import api (.是当前文件夹)
在api包下的__init__.py
from . import es
from . import mt
配置好包下的__init__后
import bake
bake.api.es.func()
bake.api.mt.foo() 可以使用
因为bake是一个文件夹不能进行任何操作,就让__init__.py代替它 去将api这包中的模块导入,api也是一个文件夹不能操作就需要让api下边的__init__.py去找api下边的两个模块
在es.py文件中,直接使用import导入mt时,可以导入,但在test里运行时会报错,需要在es.py里增加路径
import os
import sys
sys.path.insert(0,os.path.dirname(__file__)
from import 模式
在bake包下的__init__.py
from . import *
在api包下的__init__.py
__all__ = ["es","mt"]
或
from . import es
from . import mt
(推荐from)
在db包下的__init__.py
...
路径: 绝对路径:从最外层(bake)包.查找的就是绝对路径 相对路径: .就是相对路径, ..是上一级目录
注意在使用相对路径的时候一定要在于bake同级的文件中测试3.logging日志
作用:
记录用户的信息
记录个人流水
记录软件的运行状态
记录程序员发出的指令
用于程序员代码调试
import logging
# 初始化一个空日志(创建了一个对象)
logger = logging.getLogger()
# 创建一个文件,用于记录日志信息
fh = logging.FileHandler('test.log',encoding='utf-8')
# 创建一个文件,用于记录日志信息
fh1 = logging.FileHandler('test1.log',encoding='utf-8')
# 创建一个可以在屏幕输出的东西
ch = logging.StreamHandler()
# 对要记录的信息定义格式
msg = logging.Formatter('%(asctime)s - [line:%(lineno)d] %(filename)s - %(levelname)s - %(message)s')
# 对要记录的信息定义格式
msg1 = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# 设置记录等级
logger.setLevel(10) or logger.setLevel(logging.DEBUG)
# 将咱们设置好的格式绑定到文件上
fh.setFormatter(msg)
fh1.setFormatter(msg)
# 将咱们设置好的格式绑定到屏幕上
ch.setFormatter(msg1)
# 将设置存储日志信息的文件绑定到logger日志上
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(fh1)
logger.addHandler(ch)
# 记录日志
logger.debug([1,2,3,4,])
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
等级对应表
'''
DEBUG - 10
INFO - 20
WARNING - 30
ERROR - 40
CRITICAL - 50
'''
默认从WARNING开始记录4.hashlib模块
加密
校验
加密方法:md5,sha1,sha256,sha512
md5,加密速度快,安全系数低
sha512 加密速度慢,安全系数高
密文越长安全系数越高
加密过程:明文 -- 字节 -- 密文
当要加密的内容相同时,你的密文一定是一样的
当你的明文不一样时,密文不一定一样
不可逆
md5加密
普通加密
import hashlib
md5 = hashlib.md5() # 初始化
md5.update("alex".encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
加固定盐
import hashlib
md5 = hashlib.md5("rimo_dsb".encode("utf-8")) # 初始化
md5.update("alex".encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
加动态盐
import hashlib
user = input("username:")
pwd = input("password:")
md5 = hashlib.md5(user.encode("utf-8")) 初始化
md5.update(pwd.encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
中文内容编码不同时密文是不一致,英文的密文都是一致的
校验Pyhton解释器的Md5值是否相同
import hashlib
def file_check(file_path):
with open(file_path,mode='rb') as f1:
sha256 = hashlib.md5()
while 1:
content = f1.read(1024)
if content:
sha256.update(content)
else:
return sha256.hexdigest()
print(file_check('python-3.6.6-amd64.exe'))5.collections
基于python自带的数据类型之上额外增的几个数据类型
命名元组:
namedtuple
from collections import namedtuple
limit = namedtuple("limit",["x","y"])
l = limit(1,2)
print(l.x)
print(l[0])
双端队列
deque
l = deque([1,2])
l.append(3)
l.appendleft(0)
l.pop()
l.popleft()
l.remove(2)
print(l)
队列: 先进先出 栈: 先进后出
有序字典
有序字典(python2版本) -- python3.6 默认是显示有序
OrderedDict
from collections import OrderedDict
dic = OrderedDict(k=1,v=11,k1=111)
print(dic)
print(dic.get("k"))
dic.move_to_end("k")
默认字典
defaultdict
from collections import defaultdict
dic = defaultdict(list)
dic[1]
print(dic)
计数
返回一个字典
Counter
from collections import Counter
lst = [1,2,112,312,312,31,1,1,1231,23,123,1,1,1,12,32]
d = Counter(lst)
print(list(d.elements()))
print(dict(d))6.面向对象初识
与面向过程相比,面向函数编程有两个特点:
减少重复代码
增强代码可读性
与面向函数编程相比,面向对象编程有两个优点:
结构清晰,可读性高
上帝思维
类:就是具有相同属性和功能的一类事物
对象:就是类的具体表现形式
代码中先有类后有对象,与现实相反
7.面向对象结构
class people:
mind = "有思想"
def eat(self):
print("吃饭")
class 是关键字,与def用法相同,定义一个类
class 类名(驼峰体)
mind 静态属性(类变量 ,静态字段)
def 方法(类方法,动态属性,动态字段)
8.类角度操作类
查看类中的所有内容:类名.__dict__
万能的点
增:
people.emotion = "有情感"
类名.变量名 = 内容
删:
del people.mind
类名.变量名(函数名)
改:
people.mind = "无脑"
类名.变量名
查:
print(people.mind) 单独查看一个
一般不用类名去操作方法(类方法除外)9.对象角度操作类
class people:
mind = "有思想"
def init(self):
print(111)
def eat(self):
print("吃饭")
p = people() -- 实例化对象
类名()就是创建对象
print(p.__dict__) 为空字典
p.mind = "内容" -- 给对象创了一个空间,把内容增加到对象空间中
实例化对象发生了三件事:
1.实例化对象,给对象开辟空间
2.自动执行类中的__init__方法
3.将对象地址以隐性传参的方式传给self
class people:
mind = "有思想" 静态属性
def __init__(self, name, age, sex): 初始化
self.name = name
self.age = age
self.sex = sex
def eat(self): 方法
print("吃饭")
p = people("alex", 19, "男" ) 实例化对象
print(p.__dict__)
不建议在类外部给对象创建属性
print(p.mind) -- 对象查看类中的属性
p.eat() -- 对象操作类中的方法
对象空间之间是独立的
对象空间中记录着产生这个对象的类地址
查找顺序:
1.先找对象
2.创建对象的类10.self 是什么
self
就是函数的位置参数
实例化对象的本身(p和self指向的同一个内存地址)
self可以进行改变但是不建议修改
一个类可以实例化多个对象
class people:
给对象或类进行封装属性
mind = "有思想"
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
使用对象空间或类空间的属性
def eat(self):
print(f"{self.name}在吃饭")
p = people("alex", 17, "男")
p1 = people("alex", 18, "男")
p2 = people("alex", 19, "男")
print(p2.__dict__)11.类空间
给对象空间添加属性
class A:
def __init__(self, name):
# 类里边给对象添加属性
self.name = name
def func(self, sex):
#类的方法中给对象添加属性
self.sex = sex
a = A("meet")
a.func("男")
# 类外边给对象添加属性
a.age = 18
print(a.__dict__)
可以在类的内部,类的外部,类中的方法给对象空间添加属性
给类空间添加属性
class A:
def __init__(self, name):
# 类内部给类空间添加属性
A.name = name
def func(self, age):
# 类中的方法给类空间添加属性
A.age = age
#类外部给类空间添加属性
A.name = "alex"
a = A('meet')
a.func(19)
print(A.__dict__)
对象查找属性的顺序:先从对象空间找 ------> 类空间找 ------> 父类空间找 ------->.....12.类关系
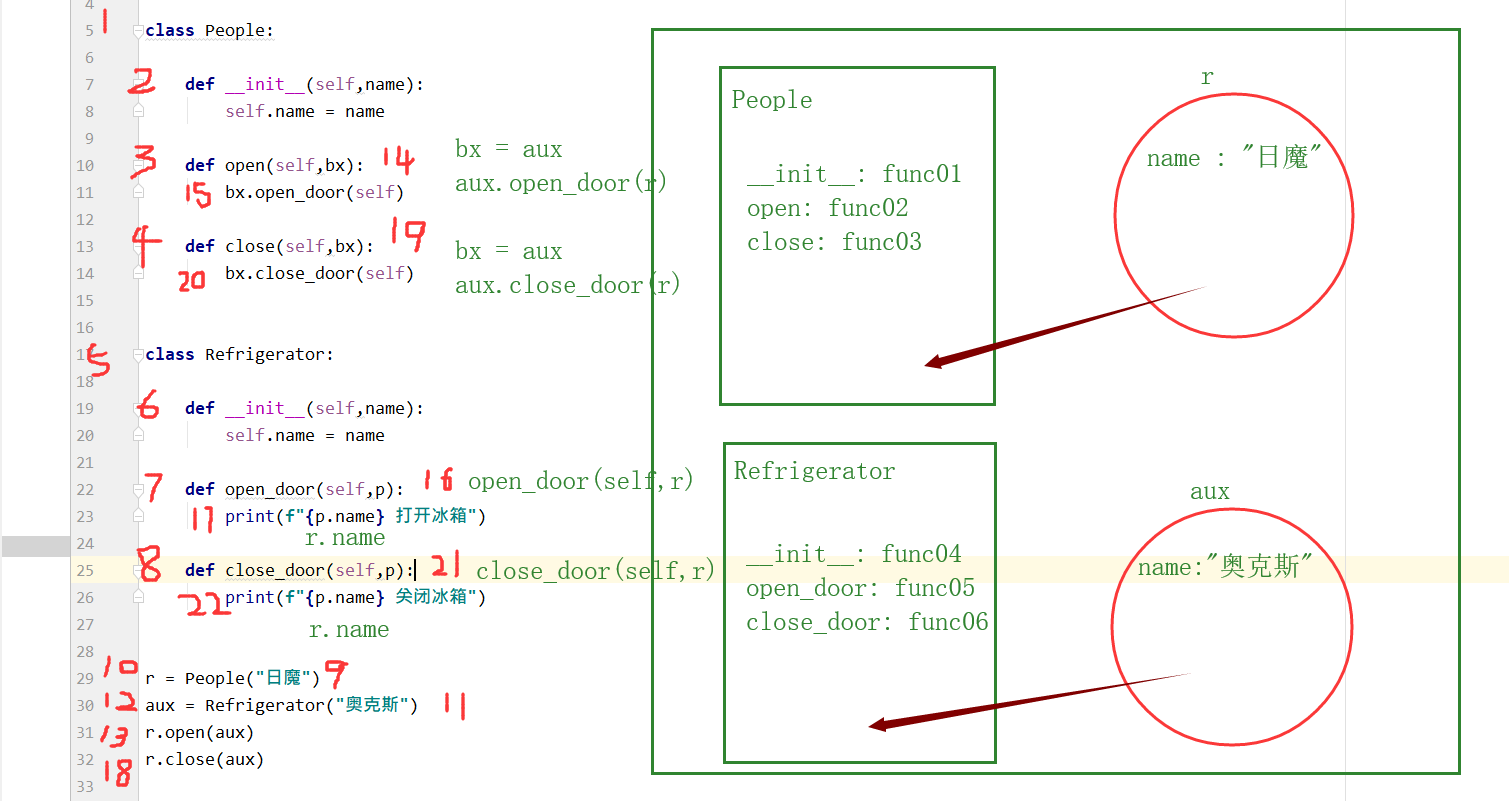
依赖关系
将一个类的对象当做参数传递给另一个类的方法中
class People:
def __init__(self,name):
self.name = name
def open(self,bx):
bx.open_door(self)
def close(self,bx):
bx.close_door(self)
class Refrigerator:
def __init__(self,name):
self.name = name
def open_door(self,p):
print(f"{p.name} 打开冰箱")
def close_door(self,p):
print(f"{p.name} 关闭冰箱")
r = People("日魔")
aux = Refrigerator("奥克斯")
r.open(aux)
r.close(aux)
组合关系
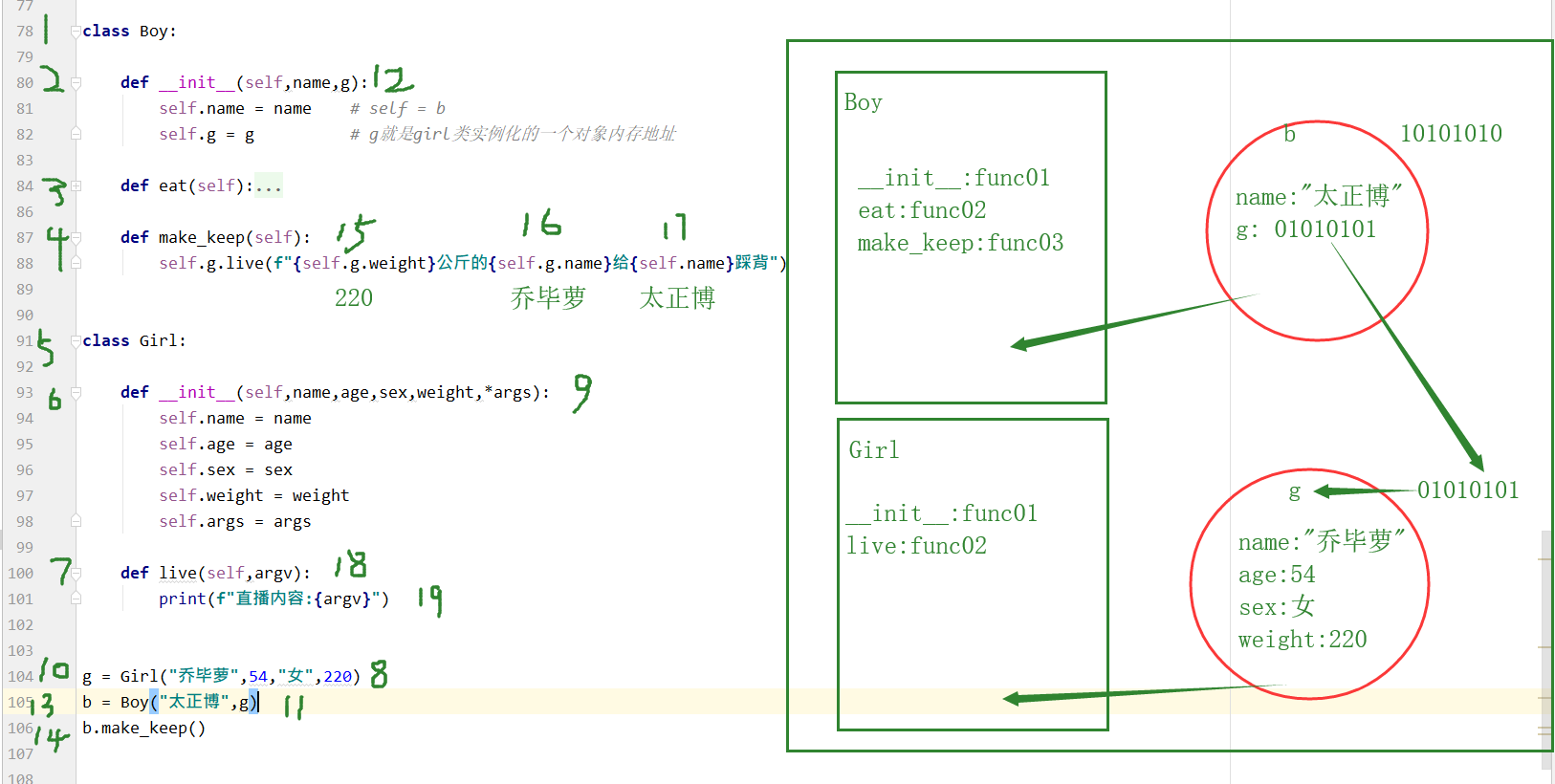
将一个类的对象封装到另一个类实例化的对象空间中
class Boy:
def __init__(self,name,g):
self.name = name # self = b
self.g = g # g就是girl类实例化的一个对象内存地址
def eat(self):
print(f"{self.name}和{self.g.age}岁,且{self.g.weight}公斤的{self.g.name}py朋友.一起吃了个烛光晚餐!")
def make_keep(self):
self.g.live(f"{self.g.weight}公斤的{self.g.name}给{self.name}踩背")
class Girl:
def __init__(self,name,age,sex,weight,*args):
self.name = name
self.age = age
self.sex = sex
self.weight = weight
self.args = args
def live(self,argv):
print(f"直播内容:{argv}")
g = Girl("乔毕萝",54,"女",220)
b = Boy("太正博",g)
b.make_keep()
self.g.f.eat() 一定是组合 (组合是咱们最常用的关系)13.继承
继承的优点:
减少重复代码
结构清晰,规范
增加耦合性(不在多,在精)
继承的分类:
单继承,多继承
Python2: python2.2 之前都是经典类,python2.2之后出现了新式类,继承object就是新式类
Python3: 只有新式类,不管你继不继承object都是新式类
单继承
A(B)
A -- 子类(派生类)
B -- 父类(基类,超类)
通过子类的类名使用父类的属性和方法
通过子类的对象使用父类的属性和方法
class Animal: # 父类
live = "活的"
def __init__(self, name, age, sex):
print("is __init__")
self.name = name
self.sex = sex
self.age = age
def eat(self): # self 是函数的位置参数
print("吃")
class Human(Animal): # 子类
pass
# 通过子类的类名使用父类的属性和方法
print(Human.live)
Human.eat(12)
Human.__init__(Human,"日魔",18,"男")
print(Human.__dict__)
# 通过子类的对象使用父类的属性和方法
p = Human("日魔",18,"男")
print(p.__dict__)
print(p.live)
查找顺序:
通过子类,类名使用父类的属性或方法(查找顺序):当前类, 当前类的父类,当前类的父类的父类 --->
通过子类对象使用父类的属性或方法(查找顺序):先找对象,实例化这个对象的类,当前类的父类, --->
使用子类和父类方法或属性
方法一:不依赖继承
class Animal: # 父类
live = "活的"
def __init__(self, name, age, sex):
# self = p的内存地址
self.name = name
self.sex = sex
self.age = age
def eat(self): # self 是函数的位置参数
print("吃")
class Human: # 子类
#在本类的__init__方法中,使用另一个类名的__init__方法进行初始化
def __init__(self, name, age, sex, hobby):
print(Animal.live)
# self = p的内存地址
Animal.__init__(self,name,age,sex)
self.hobby = hobby
p = Human("日魔",18,"男","健身")
print(p.__dict__)
方法二: 依赖继承
class Animal: # 父类
live = "活的"
def __init__(self, name, age, sex):
# self = p的内存地址
self.name = name
self.sex = sex
self.age = age
def eat(self): # self 是函数的位置参数
print("吃")
class Dog(Animal):
# 初始化方法
def __init__(self, name, age, sex, attitude):
# self = p的内存地址
# super(Dog,self).__init__(name,age,sex) # 完整写法
super().__init__(name,age,sex) # 正常写法 重构方法
self.attitude = attitude
d = Dog("日魔",18,"男","忠诚")
print(d.__dict__)
super只能继承之后使用原文:https://www.cnblogs.com/sunyongchao/p/11438218.html