? 上一篇blog介绍了简洁优美的resnet,这一篇介绍一下相对复杂的GoogleNet
? GoogleNet的提出是在2014年,当时大多数网络都追求深度,但是看如下几幅图片

? 在利用CNN识别出图中的小狗时,势必要为每个卷积层选择合适的kernel size。但是上面几幅图中小狗的位置都不相同,大小也不一样,利用单一的卷积核大小显然不合理。比如第一张就应该用较大的卷积核,第三张就应该用较小的卷积核。
? 问题出现了,解决方法很快就被想出。何不在一个卷积层上储备多个不同大小的卷积核呢,与其增加深度,不如增加宽度,想法看起来很自然。
? 论文中提出的解决方案叫做Inception模块,下面我们随着其发展顺序逐一介绍
? 下图就是最原始的Inception模块。它没有使用单一的卷积核,而是使用了3个不同大小的滤波器,此外还有一条路执行max pooling操作。这四条路的输出最后会被级联起来传至下一个模块
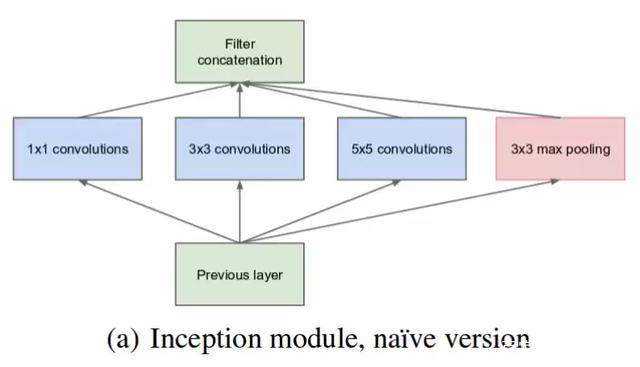
? 此外,在执行3*3或5*5的卷积操作之前,先进行1*1的卷积。这样做的目的是减少channel数量。降低计算成本。
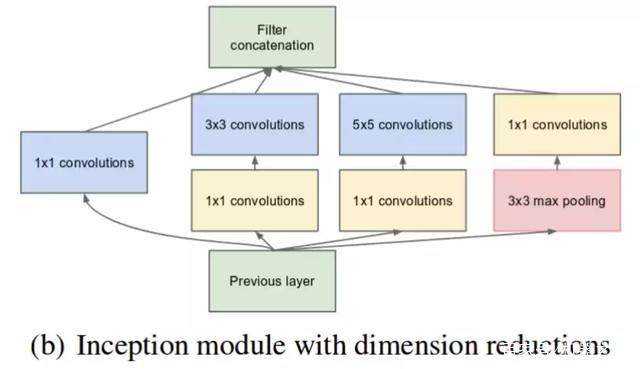
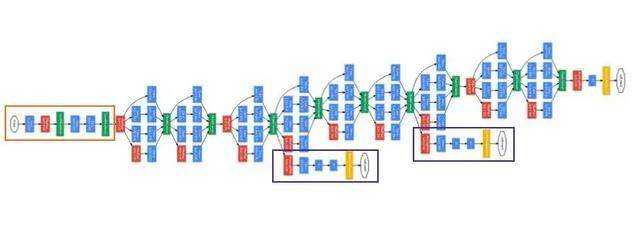
? 最初的GoogleNet就是建立在Inception v1的基础上,其一共有9个线性堆叠的Inception模块。
? 这样一个网络也很深,也会遭受 gradient vanish 的问题。于是作者在网络中间加了两个辅助分类器(auxiliary classifier)(图中紫框)。这两个辅助分类器在训练过程中使用,在预测过程中不使用。在计算loss时,由如下公式
\[
total\_loss = real\_loss + 0.3 * aux\_loss_1 + 0.3 * aux\_loss_2
\]
? v2 在v1的基础上做了一点改变。将一个5*5的卷积用两个3*3的卷积进行替代。
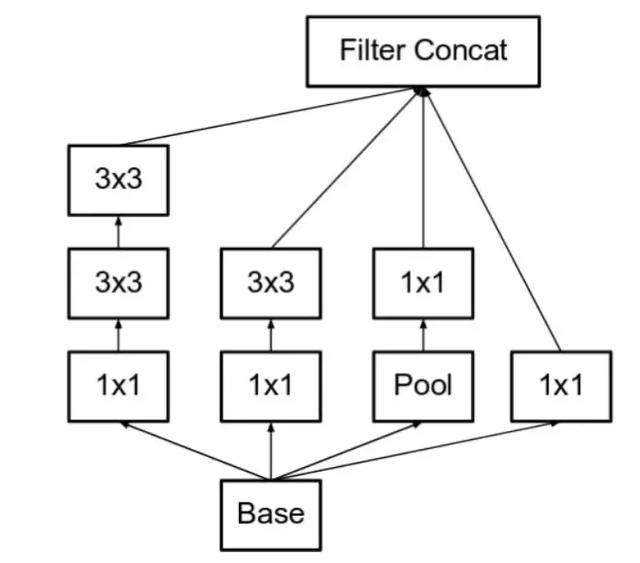
? 那么为什么能够这么做呢,看下面一幅图
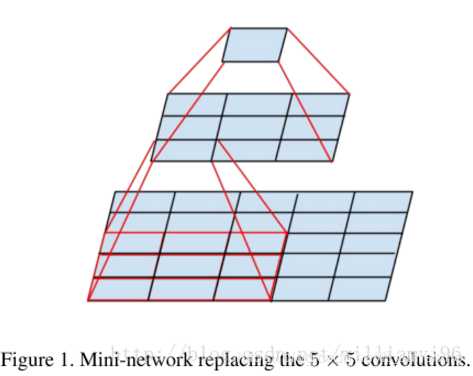
? 从图中可以看出1个5*5卷积得到的neuron和2个3*3卷积得到的neuron,它们两者对应被卷积层的感受野(RF,respective field)是相同的,都是一个5*5大小的矩阵。而决定CNN效果的就是感受野的选择,因此这两种操作在效果上是等价的。但是在开销上两个3*3的卷积核所需要的参数少于5*5的参数。简单计算一下
? 两个3*3卷积需要的参数 \(2*3*3*channel\)
? 一个5*5卷积需要的参数 \(1*5*5*channel\)
? 显然前者开销更少。
? 此外,一个3*3的卷积也能用一个1*3的卷积和一个3*1的卷积替代,增加深度,增强非线性表达能力的同时也能减少开销。如下图
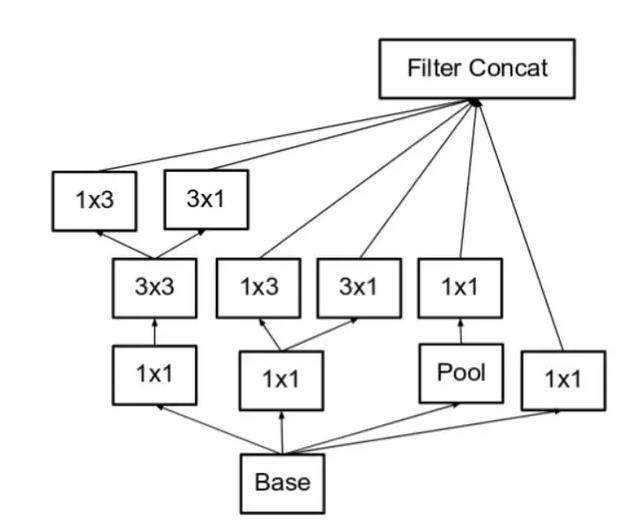
? 至此Inception v2介绍完毕
? Inception v3其实就对对Inception v2做了一点小优化
原文:https://www.cnblogs.com/buaa17231043/p/11438391.html