redis整个db都是一个哈希字典表(不支持范围查找), 那这样的话keys命令需要遍历db里所有的key吗??渣浪多年前就热衷于用xxx_yyy_zzz_*的方式去匹配key了,为什么他们热衷于这样做, 是不是redis有特殊的优化技巧呢? 带着这些疑问下载了最新版Redis代码。
1. 定位keys的实现方式, 是否真的低性能。--done
2. 定位redis-cluster里主机不分发keys给集群里其它主机的原因。 --done
3. 找到一个spring-cloud+redis cluster 执行keys命令的范式。--未验证
1. 服务器启动阶段,server.c::initServerConfig()调用populateCommandTable加载命令列表;
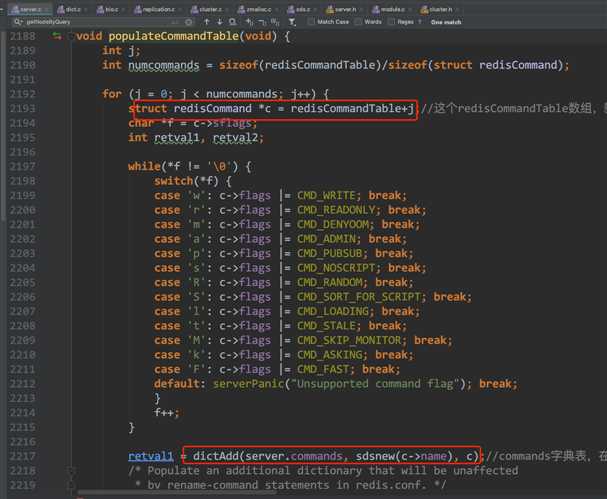
redis所支持的命令列表是下面硬编码 , 可以看到keys命令处理函数(keysCommand)的逻辑是, 遍历数据库的所有key.
struct redisCommand redisCommandTable[] = { {"module",moduleCommand,-2,"as",0,NULL,0,0,0,0,0}, {"get",getCommand,2,"rF",0,NULL,1,1,1,0,0}, {"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0}, //... {"keys",keysCommand,2,"rS",0,NULL,0,0,0,0,0}, //... };
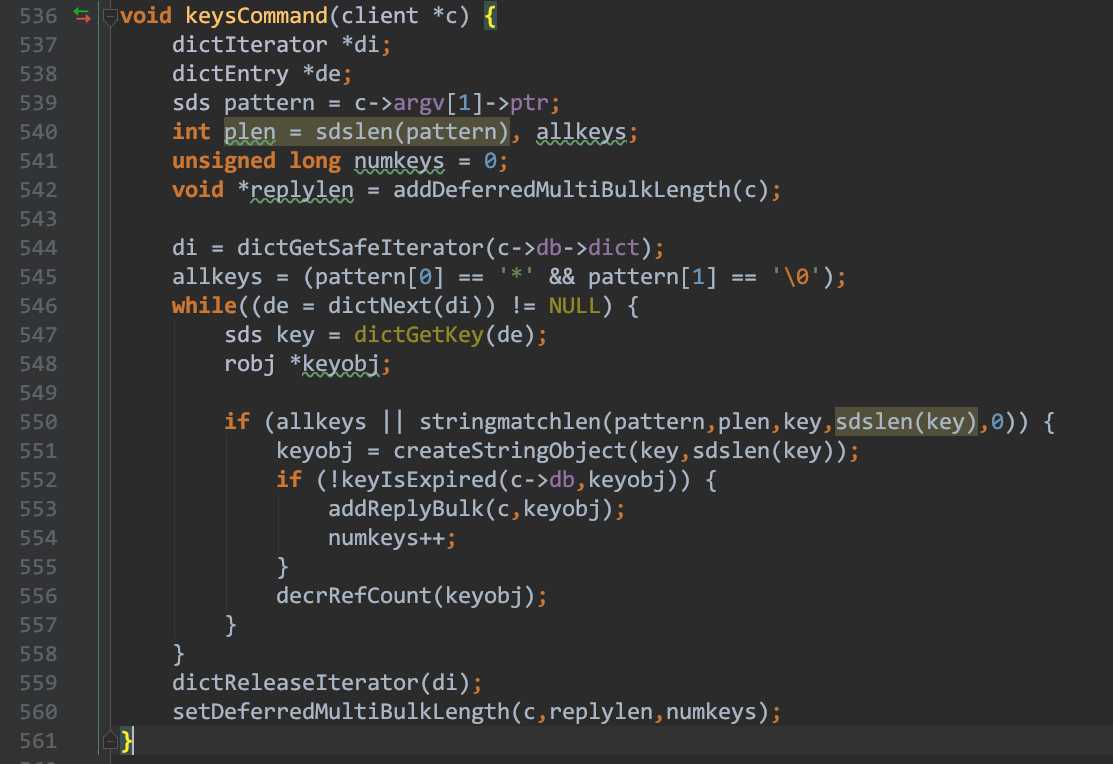
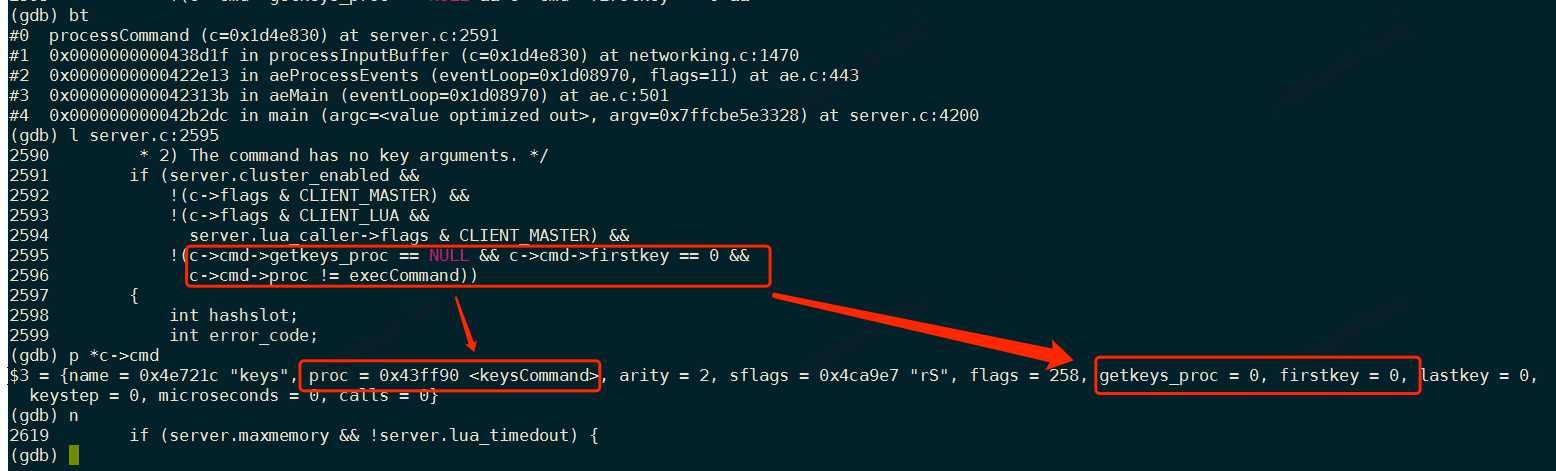
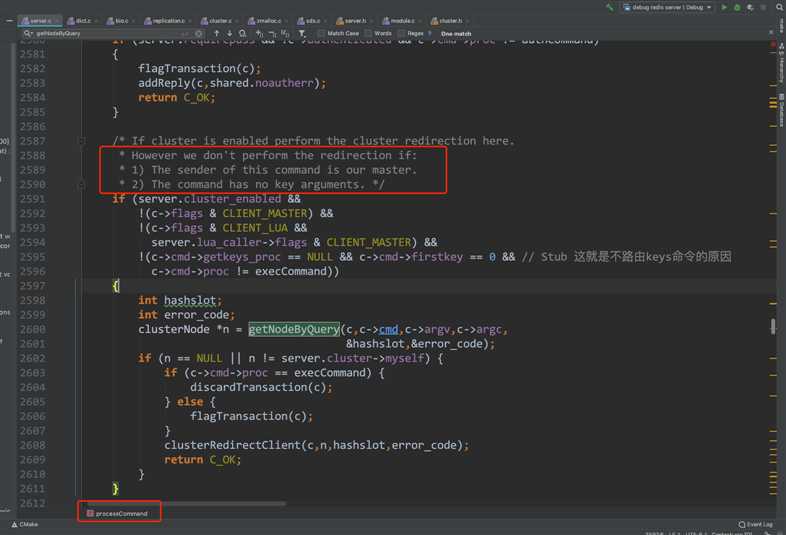
方法一:aaa:bbb:ccc:ddd这类key全部存在一张hash表里,数据均匀分布是什么?
方法二:去cluster每个节点执行keys命令,结果汇总。
方法三:自己维护“索引”。例如在redis里使用key为aaa:bbb:ccc的hash表存放所有以aaa:bbb:ccc:*这类key。
1. keys命令是通过遍历全部db下key再过滤实现的。
2. keys命令不会被cluster路由给其它集群节点,更不会返回集群各节点keys结果的汇总结果。
原文:https://www.cnblogs.com/yinkw/p/redis_keys.html