Hash索引 优点:通过字段的值计算的hash值,定位数据非常快。 缺点:不支持范围查询 为什么不支持范围查询? 因为底层数据结构是散列的,无法进行比较大小 平衡二叉树 会取一个中间值,中间值左边称为左子树 ,中间值右边称为右子树 。
左子树比中间小,右子树比中间值。
数据结构平衡二叉树算法 平衡二叉查找树,又称 AVL树。 它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它 的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。
也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。
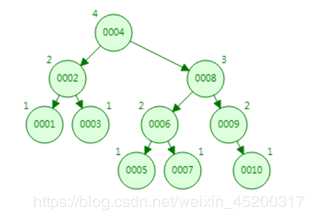
假设查询10 (需要经历4次IO操作) 1次 从硬盘中读取4 (内存),判断下10>4,取右指针 2次 从硬盘中读取8
(内存),判断下10>8,取右指针 3次 从硬盘中读取9 (内存),判断下10>,取右指针 4次 从硬盘中读取10
(内存),判断下10=10,定位到数据 优点:平衡二叉树算法基本与二叉树查询相同,效率比较高
缺点:插入操作需要旋转,支持范围查询
B树
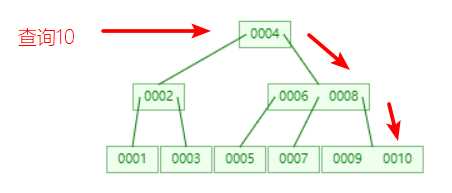
B树查询效率比平衡二叉树效率要高,因为B树的节点中可以有多个元素,从而减少树的高度,减少IO操作,从而提高查询效率
缺点:范围查询效率还是比较低。 B+树 解决范围查询问题、减少IO查询的操作。
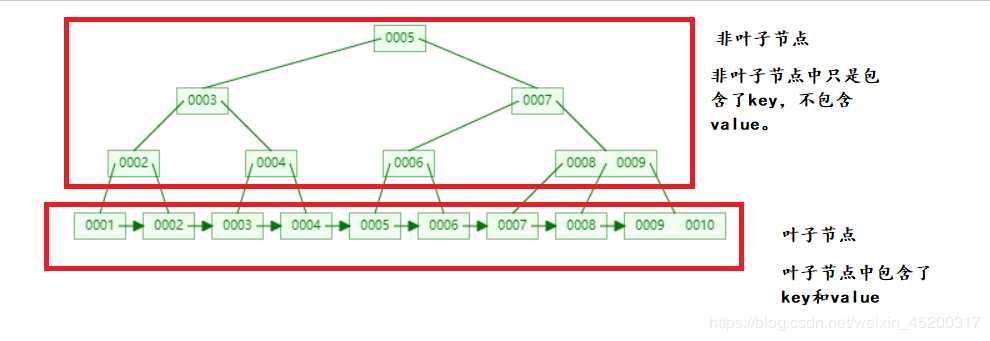
B+树算法: 通过继承了B树的特征,B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。通过非叶子节点查询叶子节点获取对应的value,所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
缺点:因为有冗余节点数据,会比较占内存。
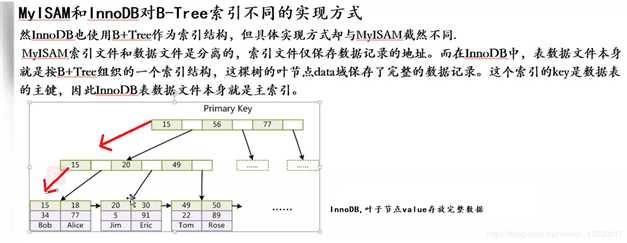
MyISAM和InnoDB对B-Tree索引不同的实现
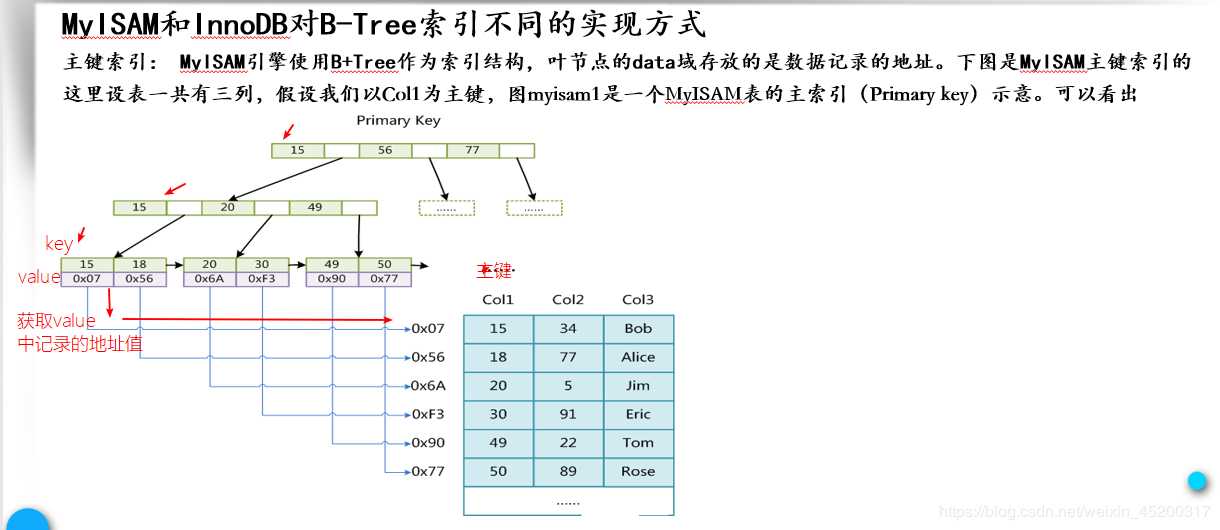
原文:https://www.cnblogs.com/gurenli/p/11443435.html