from sklearn.datasets import make_blobs
from matplotlib import pyplot
# create test data sets
datas, targets = make_blobs(
n_samples=100, #样本数量
n_features=2, #样本特征数
centers=3, #中心数量
cluster_std=[0.5, 1.0, 1.5], #方差
center_box=(-20.0, 20.0),
shuffle=True,
random_state=None
)
pyplot.scatter(datas[:,0],datas[:,1],c=targets)
pyplot.show()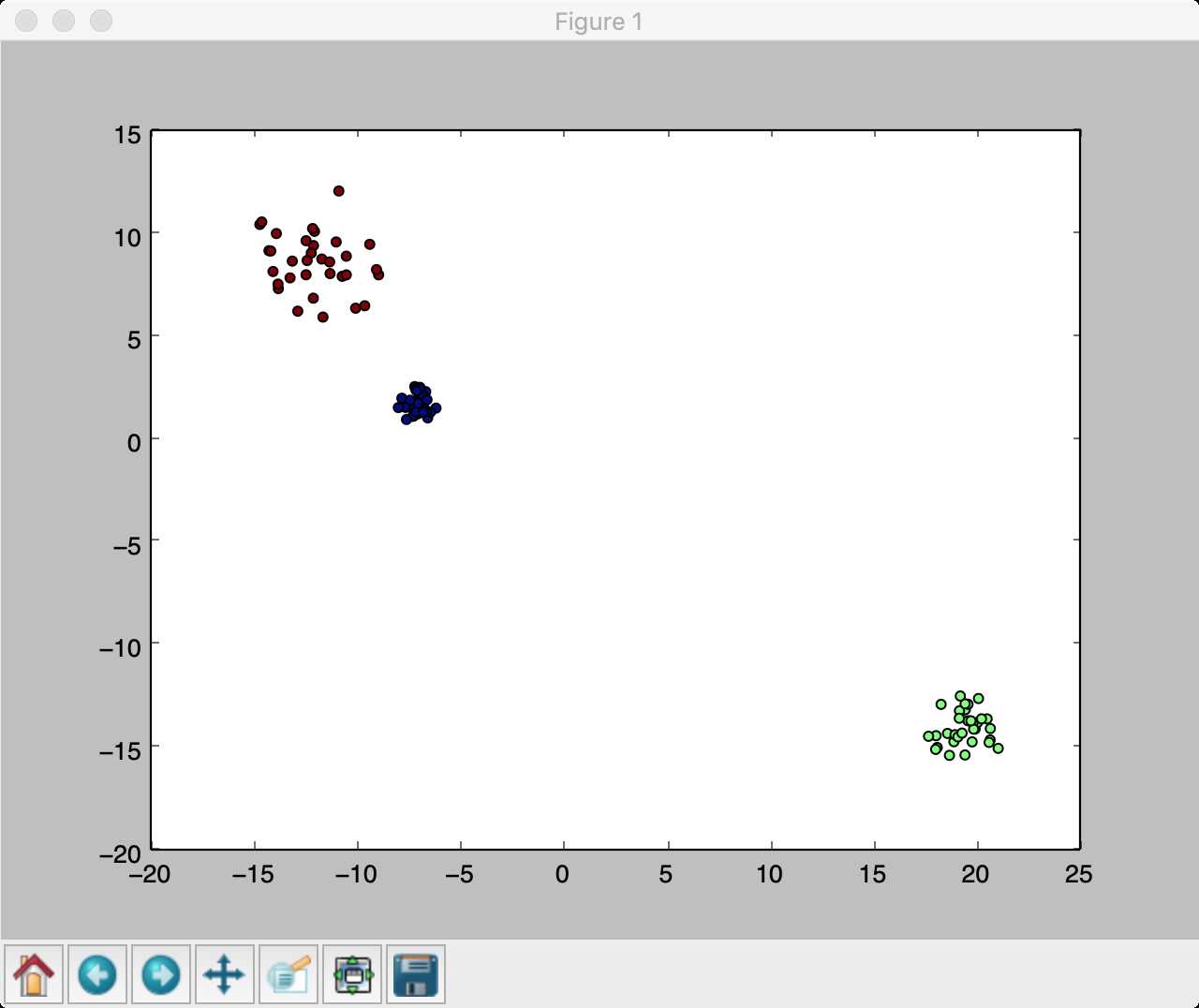
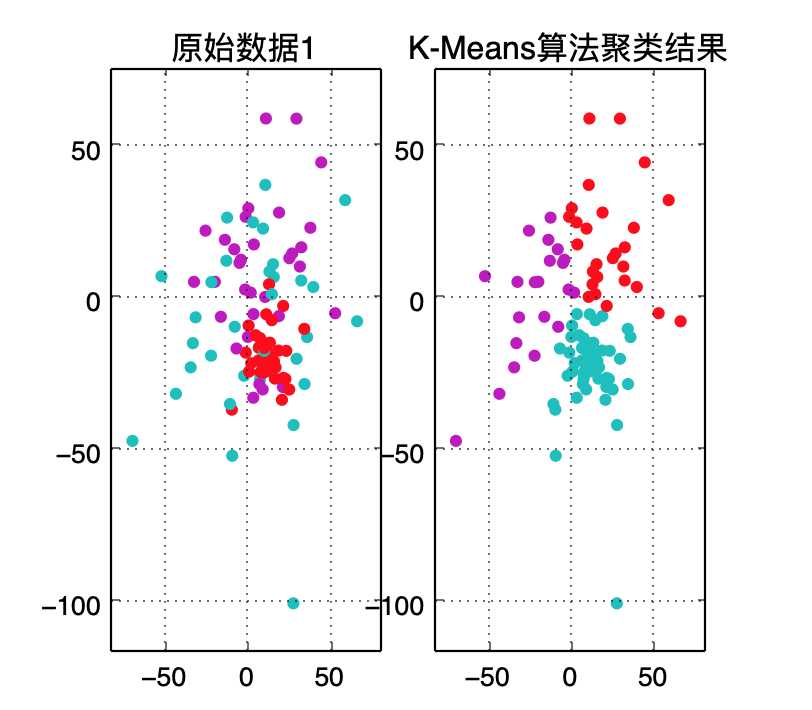
km = KMeans(n_clusters=3, random_state=10)#创建模型(几个群组,随机种子数)
km.fit(datas, targets)#计算聚类
y_hat = km.predict(datas)#给这个样本估计最接近的分组(簇)
'''
ret = km.fit_predict(datas) #返回一个给数据每一项分组的组号列表
print km.get_params()#获取参数信息
km.set_params(keyname=value)
'''
其他常用函数

原文:https://www.cnblogs.com/KevinGeorge/p/11450557.html