1、导入数据可视化的相关库文件
import pandas as pd pd.set_option(‘display.max_column‘,30) import numpy as np import statsmodels.api as sm import matplotlib.pyplot as plt import seaborn as sns sns.set() from pylab import rcParams ##matplotlib rcParams[‘figure.figsize‘] = 12, 8
2、读入数据
train = pd.read_csv(‘data/first_round_training_data.csv‘)[[‘Parameter‘+str(i) for i in range(1,11)]+[‘Quality_label‘]] test = pd.read_csv(‘data/first_round_testing_data.csv‘)
3、区分开类别特征和连续特征
理解:类别变量就是说特征取值比较少的变量,连续特征值就是说特征连续取值,所有用可视化数据的nunique()
train.nunique().plot(kind=‘bar‘)
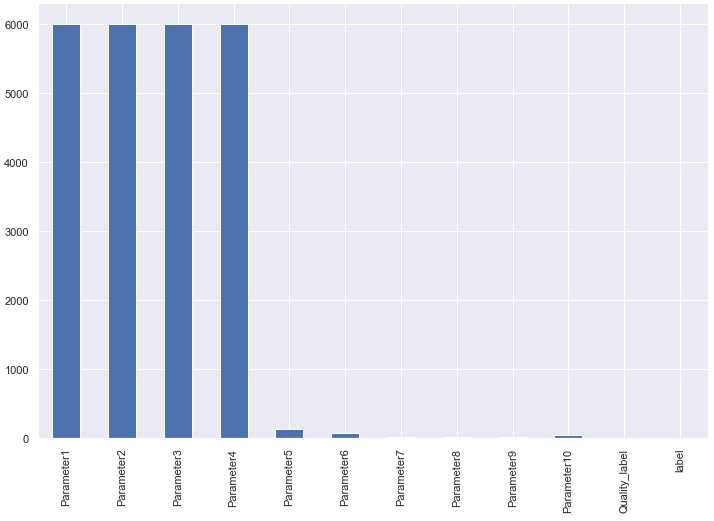
上图中前四个表示连续特征,后边的都是类别特征,最后两个是标签。
4、可视化特征取值与类别的关系
理解:这样步骤可以用来看特征中是否有些异常点等。
for i in [‘Parameter‘+str(i) for i in range(1,11)]: sns.scatterplot(x=‘Quality_label‘, y=i, data=train) plt.title(i) plt.show()
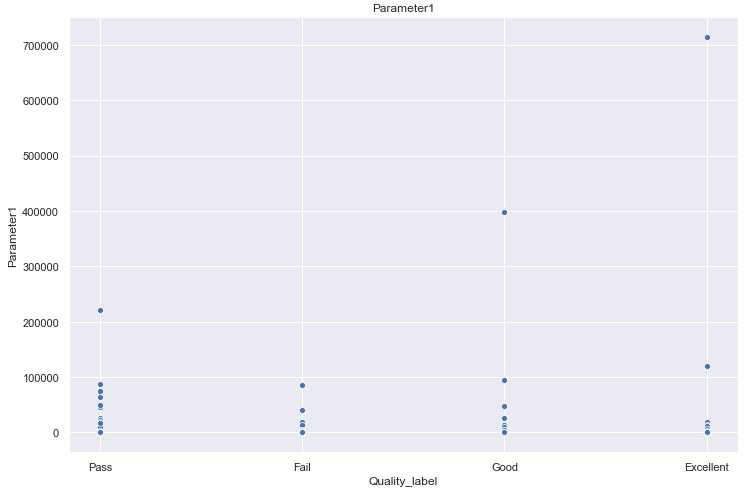
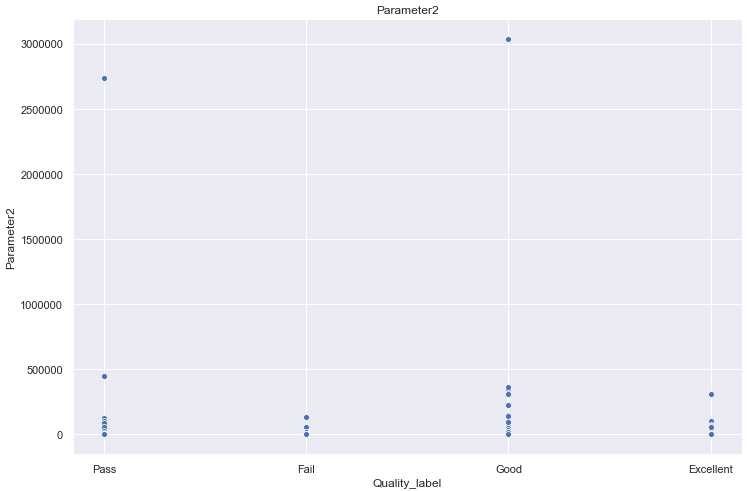
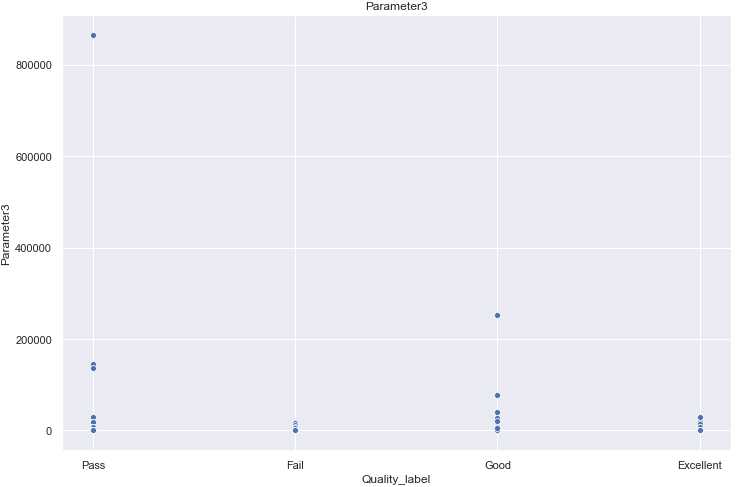
。。。。后面还有7张图就不贴了。。
5、用散点图绘制训练集和测试集的分布,查看异常值
for i in [‘Parameter‘+str(i) for i in range(1,11)]: plt.figure(figsize=(14,8)) plt.scatter(x=range(len(train)), y=train[i], label=‘Train‘) plt.scatter(x=range(len(test),len(test)*2), y=test[i], label=‘Test‘) plt.title(i) plt.legend() plt.show()
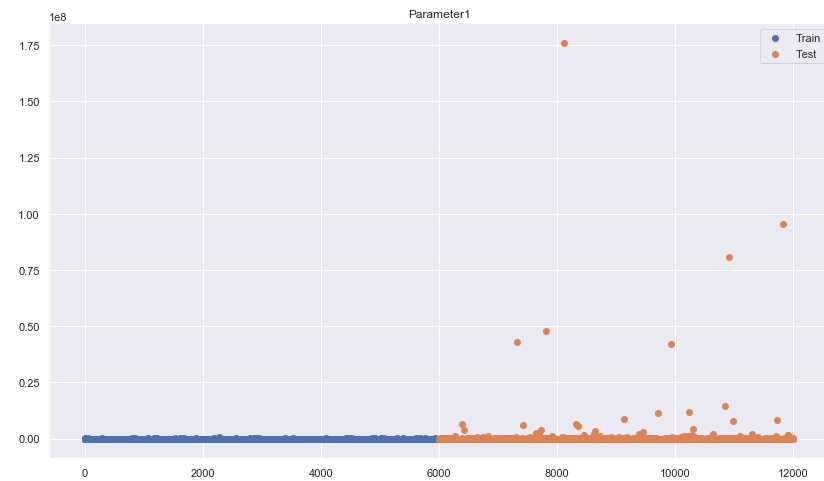
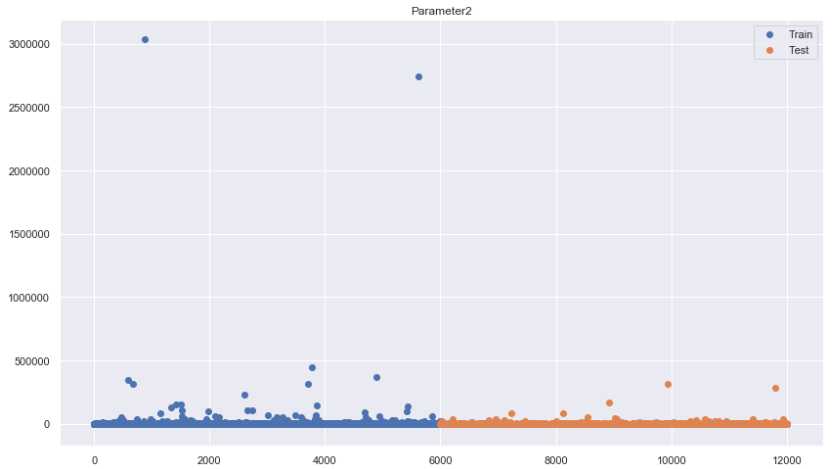
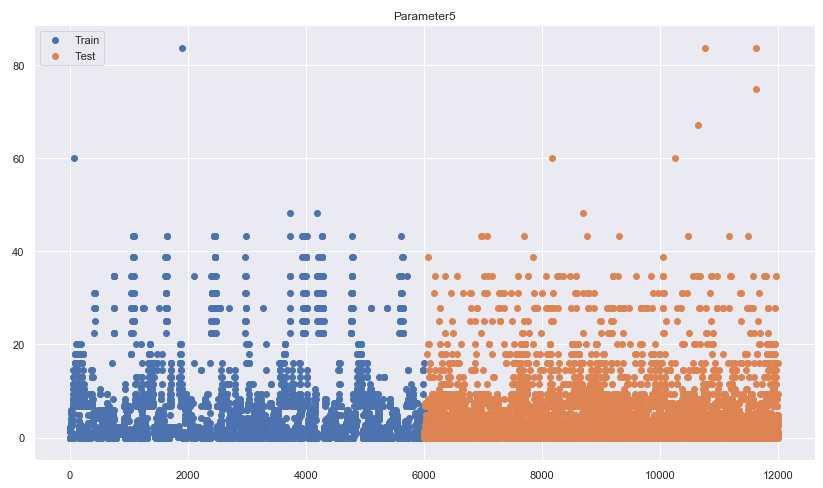
。。。。。。后面还有几张
原文:https://www.cnblogs.com/tyh666/p/11477899.html