一、HDFS定义
HDFS (Hadooop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合走来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二、HDFS优缺点
2.1、优点
1) 高容错性
2) 适合处理大数据
3) 可构建在廉价机器上,通过多副本机制,提高可靠性。
2.2 缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的
2)无法高效的对大量小文件进行存储
3)不支持并发写入、文件随机修改。
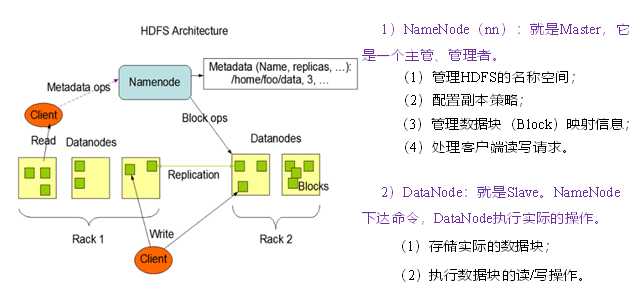
三、HDFS组成架构

四、HDFS写数据流程
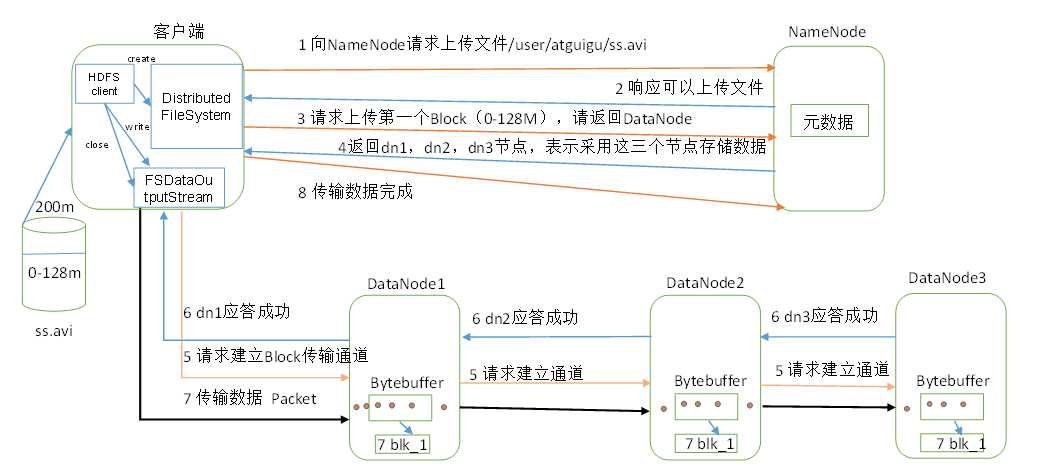
1.Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象。
2.通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block。
3.通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包。
4.以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet。
5.这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client。
6.完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流。
7.调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功。
五、HDFS读数据流程
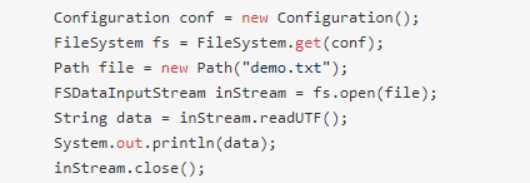
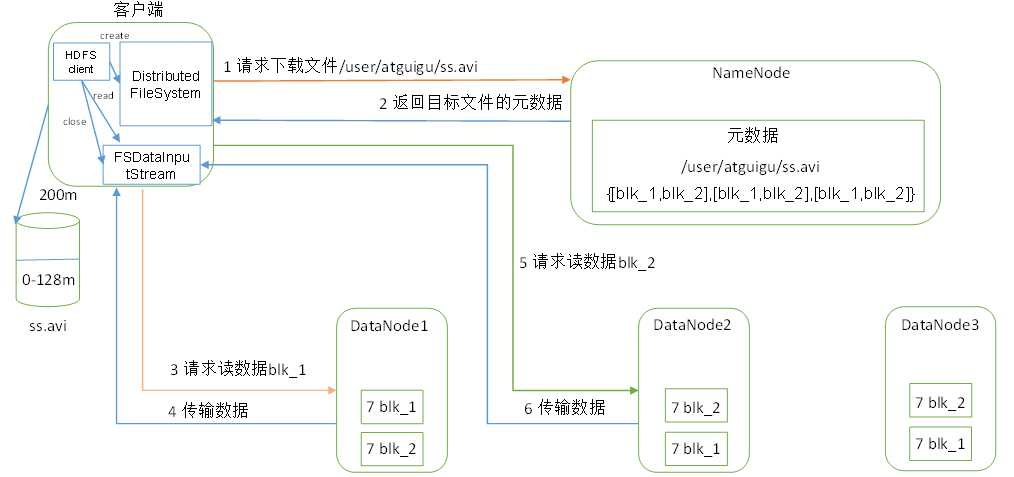
1.初始化FileSystem,然后客户端用FileSystem的open函数打开文件
2.FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3.FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用FSDI的read()函数开始读取数据。
4.FSDataInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端。
5.当此数据块读取完毕时,FSDataInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
6.当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
7.在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
8.失败的数据节点会被记录,此后不再连接。
六、NN和2NN工作机制 (Fsimage 与 EditLog定义及合并过程)
fsimage文件:即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,包含文件系统中的所有目录和文件inode的序列化信息。
edits:文件系统的写操作首先把它记录在edit中。
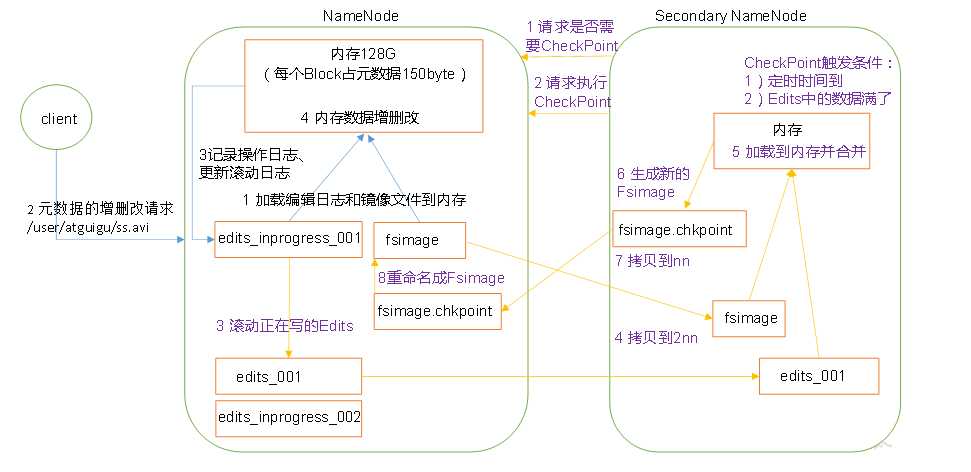
合并过程:
1.secondary namenode通过周期性(五分钟),通过getEditLog获取editlog大小,当其达到合并的大小时通过RollEditLog方法进行合并。
2.namenode停止使用edits文件,并生成一个新的临时的edits.new文件。
3.Secondarynamenode通过namenode内建的Http服务器,以get的方式获取edits与fsimage文件。Get方法中携带着fsimage与edits的路径。
4.Secondaryname将fsimage载入内存并逐一执行edits中的操作,生成新的fsimage文件。
5.执行结束后,会向namenode发送http请求,告知namenode合并结束,namenode通过http post的方式获取新fsimage文件。
6.Namenode更新fsimage文件中记录检查点执行的时间,并改名为fsimage文件。
7.Edit.new文件更名为edit文件。
注:由此可知namenode 与 secondarynamenode 有着相似的内存需求,因为secondarynamenode也会将fsimage载入内存,因此secondarynamenode需要运行在一台专门机器上。
原文:https://www.cnblogs.com/lisen10/p/11353894.html