前几天无意中发现一个网站,里面罗列了各种User-Agent,哇!真的是特别多,我开心的不得了,然后今天决定把它们都爬下来,以后大批量爬虫有UA池!
选择BROWSERS

废话不多说,附上代码
1 # -*- coding: utf-8 -*- 2 3 import requests 4 from lxml import etree 5 6 url = ‘http://useragentstring.com/pages/useragentstring.php?typ=Browser‘ 7 8 header = { 9 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60‘, 10 } 11 12 response = requests.get(url,headers=header,timeout=60 13 ) 14 15 tree = etree.HTML(response.text) 16 ua_list = tree.xpath(‘//div[@id="liste"]/ul/li/a/text()‘) 17 18 for ua in ua_list: 19 print(ua,len(ua)) 20 21 print(len(ua_list))
结果,我获得了9529条User-Agent
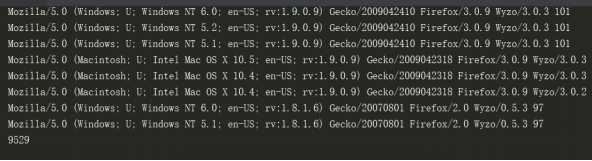
这应该是史上最强UA池了吧!

原文:https://www.cnblogs.com/Summer-skr--blog/p/11484656.html