最近读了《word2vec Parameter Learning Explained》,是一片很好的讲解word2vec的论文。帮助我更加直观的理解了词向量的生成以及层次softmax和负采样的思想,对以下问题有了更深刻的认识:
1 Continuous Bag-of-Word Model
1.1 One-word context
CBOW的思想是给定上下文去预测中心词,先假设最上下文只有一个词的情况。
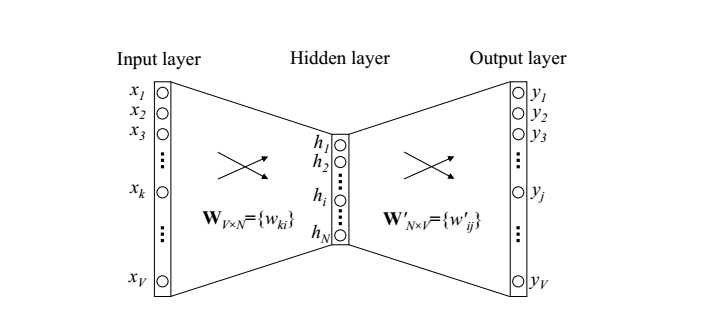
x是输入词wI对应的onehot向量,WVXN是一个VxN的矩阵,W‘NxV是一个NxV的矩阵,V为词表的大小,N是词向量的维度,其中W的每个行向量就是word2vec要去学习的词向量。
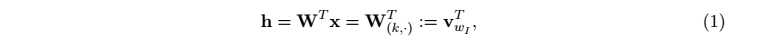
由于x是onehot的向量,h实际上就是wI对应的词向量
$$W = \left[ \begin{matrix}
&—w_{1}^\mathrm{T}—&\\
&—w_{2} ^\mathrm{T}—&\\
&\vdots &\\
&—w_{N} ^\mathrm{T}—&
\end{matrix} \right] $$
word2vec Parameter Learning Explained论文笔记:CBOW,Skip-Gram,层次softmax与负采样解读
原文:https://www.cnblogs.com/DLstudy/p/11485928.html