6、如果当前时间是 2018年5月1日10点10分9秒,则下面代码的输出结果是????????????????????????????????????????????????????????????????????????????????
import time
print(time.strftime("%Y=%m-%d@%H>%M>%S", time.gmtime()))
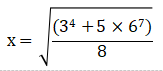
a = pow((3^4+5*6^7)/8,0.5)
print("%.3f"%a)
import jieba
s = "中国特色社会主义进入新时代,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾。"
n = ____①____
m = ____②____
print("中文字符数为{},中文词语数为{}。".format(n, m)),中文

print("二进制{____①____}、十进制{____②____}、八进制{____③____}、十六进制{____print("二进制{0:b}、十进制{0}、八进制{0:o}、十六进制{0:x}".format(0x4DC0+50))
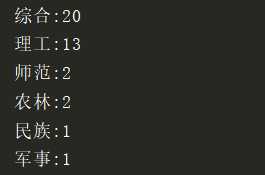
ls = ["综合", "理工", "综合", "综合", "综合", "综合", "综合", "综合", "综合", "综合", "师范", "理工", "综合", "理工", "综合", "综合", "综合", "综合", "综合","理工", "理工", "理工", "理工", "师范", "综合", "农林", "理工", "综合", "理工", "理工", "理工", "综合", "理工", "综合", "综合", "理工", "农林", "民族", "军事"]
ls = ["综合", "理工", "综合", "综合", "综合", "综合", "综合", "综合", "综合", "综合", "师范", "理工", "综合", "理工", "综合", "综合", "综合", "综合", "综合", "理工", "理工", "理工", "理工", "师范", "综合", "农林", "理工", "综合", "理工", "理工", "理工", "综合", "理工", "综合", "综合", "理工", "农林", "民族", "军事"]
d = {}
for word in ls:
d[word] = d.get(word, 0) + 1
for k in d:
print("{}:{}".format(k, d[k]))
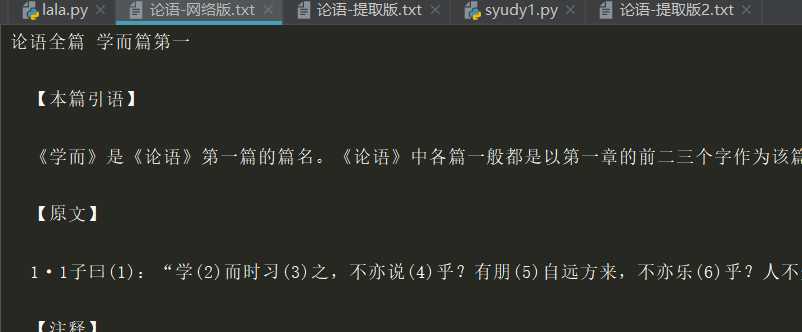
【原文】
1.11子曰:“父在,观其(1)志;父没,观其行(2);三年(3)无改于父之道(4),可谓孝矣。”
【注释】
(略)
【译文】
(略)
【评析】
(略)该版本通过【原文】标记《论语》原文内容,采用【注释】、【译文】和【评析】标记对原文的注释、译文和评析。????????????????????????????????????????????????????????????????????????????????
????????????????????????????????????????????????????????????????????????????????
问题1:请编写程序,提取《论语》文档中所有原文内容,输出保存到“论语-提取版.txt”文件。输出文件格式要求:去掉文章中原文部分每行行首空格及如“1.11”等的数字标志,行尾无空格、无空行。参考格式如下(原文中括号及内部数字是对应源文件中注释项的标记):????????????????????????????????????????????????????????????????????????????????
子曰(1):“学(2)而时习(3)之,不亦说(4)乎?有朋(5)自远方来,不亦乐(6)乎?人不知(7),而不愠(8),不亦君子(9)乎?”
有子(1)曰:“其为人也孝弟(2),而好犯上者(3),鲜(4)矣;不好犯上,而好作乱者,未之有也(5)。君子务本(6),本立而道生(7)。孝弟也者,其为人之本与(8)?”
子曰:“巧言令色(1),鲜(2)仁矣。”
(略)????????????????????????????????????????????????????????????????????????????????
问题2:请编写程序,在“论语-提取版.txt”基础上,进一步去掉每行文字中所有括号及其内部数字,保存为“论文-原文.txt”文件。参考格式如下: ????????????????????????????????????????????????????????????????????????????????
子曰:“学而时习之,不亦说乎?有朋自远方来,不亦乐乎?人不知,而不愠,不亦君子乎?”
有子曰:“其为人也孝弟,而好犯上者,鲜矣;不好犯上,而好作乱者,未之有也。君子务本,本立而道生。孝弟也者,其为人之本与?”
子曰:巧言令色,鲜仁矣。”fi = open("论语-网络版.txt", "r", encoding="utf-8")
fo = open("论语-提取版2.txt", "w", encoding="utf-8")
wflag = False #写标记
for line in fi:
if "【" in line: #遇到【时,说明已经到了新的区域,写标记置否
wflag = False
if "【原文】" in line: #遇到【原文】时,设置写标记为True
wflag = True
continue
if wflag == True: #根据写标记将当前行内容写入新的文件
line = line.lstrip() #去除每行左边的空格
for i in range(0,25):
for j in range(0,25):
line = line.replace("{}·{}".format(i,j),"")
for i in range(0,100):
line = line.replace("{}".format(i),"")
for i in range(0,100):
line = line.replace("()","")
# line = line.replace("*","")
if line == "\n":
line = line.strip("\n")
fo.write(line)
import time
print(time.strftime("%Y=%m-%d@%H>%M>%S", time.gmtime()))
s = input()
print(____①____)s = input("请输入:")# "请输入一个字符串:"
print("{:=^15}".format(s[0:15]))
____①____ timestr = "2020-10-10 10:10:10" t = time.strptime(timestr, "%Y-%m-%d %H:%M:%S") print(time.strftime("____②____", t))因为python版本造成的错误
import time
timestr = "2020-10-10 10:10:10"
t = time.strptime(timestr, "%Y-%m-%d %H:%M:%S")
print(time.strftime("%Y年%m月%d日%H时%M分%S秒", t))

解决办法:
import time
times = "2020-10-10 10:10:10"
t = time.strptime(times, "%Y-%m-%d %H:%M:%S")
t2 = time.strftime("%Y{0}%m{1}%d{2}%H{3}%M{4}%S{5}", t)
print(t2.format("年","月","日","时","分","秒"))
#或者
print((time.strftime("%Y{0}%m{1}%d{2}%H{3}%M{4}%S{5}", t)).format("年","月","日","时","分","秒"))

TGS2402:甲醛:1.36
TGS2500:氮气:5.20
TGS2310:甲烷:1.70
TGS2820:乙烯:2.43
输入格式
在屏幕上按照浓度值递减的顺序,显示输出每种气体名称,浓度,及其浓度在四种气体浓度中所占的百分比;示例如下:
氮气的浓度是:5.20,占比: 49%
str = ‘TGS2402:甲醛:1.36\nTGS2500:氮气:5.20\nTGS2310:甲烷:1.70\nTGS2820:乙烯:2.43‘
ls = str.split("\n")
sum = 0
fieds = []
for gas in ls:
fi = gas.split(":")
sum += eval(fi[2])
fieds.append(fi)
fieds.sort(key=lambda x: x[2], reverse=True)
for gas in fieds:
print(‘{}的浓度是:{},占比:{:3.0f}%‘.format(gas[1], gas[2], 100 * eval(gas[2]) / sum))
#{:3.0f} 表示,跟前面的字符保持三个空格,保留0位小数

10、????????????????????????????????????????????????????????????????????????????????
显示:????????????????????????????????????????????????????????????????????????????????
请输入5个整数,用逗号隔开:????????????????????????????????????????????????????????????????????????????????
输入:????????????????????????????????????????????????????????????????????????????????
20,23,34,52,11????????????????????????????????????????????????????????????????????????????????
11,20,23,34,52
def BubbleSort(numbers):
for i in range(len(numbers)-1):
for j in range(len(numbers)-1):
if eval(numbers[j]) > eval(numbers[j+1]):
numbers[j], numbers[j+1] = numbers[j+1],numbers[j]
return numbers
numbers = input()
numls = numbers.split(",")
sortednum = BubbleSort(numls)
print(‘,‘.join(sortednum))
2013,客户公司券商服务交易资产投资产品收益????????????????????????????????????????????????????????????????????????????????
2014,收益公司券商客户资产投资交易服务资产证券化 ????????????????????????????????????????????????????????????????????????????????
2015,公司券商客户服务资产投资债券资产证券化融资融券收益????????????????????????????????????????????????????????????????????????????????
2016,公司客户服务券商资产投资债券管理????????????????????????????????????????????????????????????????????????????????
请利用jieba库分析上述四年的主题词提取有用的信息。????????????????????????????????????????????????????????????????????????????????
1)提取每一年的主题词的个数按照年度顺序显示在屏幕上;显示示例如下:????????????????????????????????????????????????????????????????????????????????
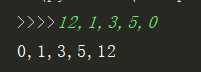
2013:9????????????????????????????????????????????????????????????????????????????????
2014:10????????????????????????????????????????????????????????????????????????????????
...????????????????????????????????????????????????????????????????????????????????
2)合计四年来的不同主题词的个数统计,以及每个主题词出现的次数按照主题词次数从大到小的顺序显示在屏幕上;显示示例如下:????????????????????????????????????????????????????????????????????????????????
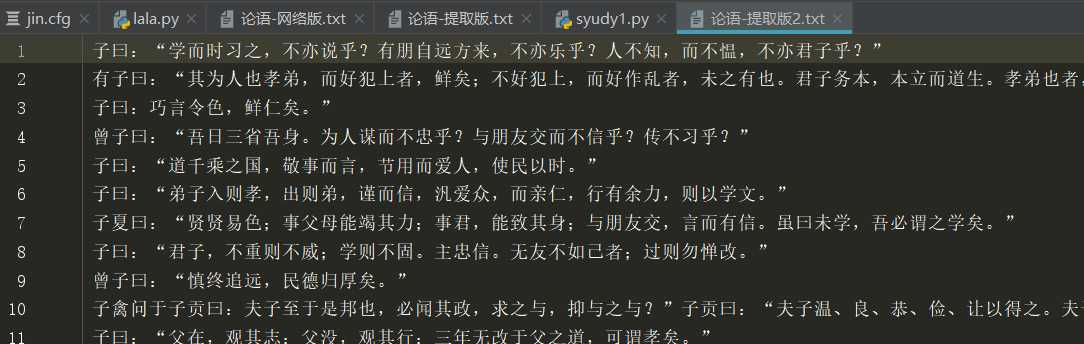
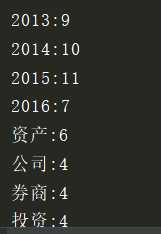
4年出现的不同主题词有12个????????????????????????????????????????????????????????????????????????????????
资产:6????????????????????????????????????????????????????????????????????????????????
公司:4????????????????????????????????????????????????????????????????????????????????
投资:4????????????????????????????????????????????????????????????????????????????????
...????????????????????????????????????????????????????????????????????????????????
3)分析每一年相比前一年的主题词的差别,在屏幕显示出来;显示示例如下: ????????????????????????????????????????????????????????????????????????????????
2014比2013多了主题词: 资产 证券化; 少了主题词: 产品
#自己瞎写的啊哈哈
import jieba
#提取每一年的主题词的个数按照年度顺序显示在屏幕上
with open("topic1.txt", "r", encoding = "utf-8") as f:
for line in f:
l1 = line.strip().split(",")[1]
l2 = jieba.lcut(l1)
print("{}:{}".format(line.strip().split(",")[0], len(l2)))
#合计四年来的不同主题词的个数统计,以及每个主题词出现的次数按照主题词次数从大到小的顺序显示在屏幕上
with open("topic1.txt", "r", encoding = "utf-8") as f:
dic = {}
l3 = ""
for line in f:
l2 = line.strip().split(",")[1]
l3 = l3 + l2
l4 = jieba.lcut(l3.strip())
for word in l4:
dic[word] = dic.get(word, 0) + 1
lis1 = []
for k,v in dic.items():
lis1.append([k,v])
lis1.sort(key = lambda x:x[1],reverse= True)
for i in lis1:
print("{}:{}".format(i[0],i[1]))
#第三问
import jieba
with open("topic1.txt", "r", encoding = "utf-8") as f:
read = []
read_f1 = f.readline()
read_f2 = f.readline()
read_f3 = f.readline()
read_f4 = f.readline()
read.append((read_f1,read_f2,read_f3,read_f4))
print(read)
def func(x,y):
r1 = x.strip().split(‘,‘)
r2 = y.strip().split(‘,‘)
r1_j = jieba.lcut(r1[1])
r2_j = jieba.lcut(r2[1])
r1_duo = []
r2_duo = []
for word1 in r1_j:
if word1 in r2_j:
continue
else: r1_duo.append(word1)
for word2 in r2_j:
if word2 in r1_j:
continue
else: r2_duo.append(word2)
r1_str = ‘,‘.join(r1_duo)
r2_str = ‘,‘.join(r2_duo)
return print("{}比{}多了主题词:{},少了主题词:{}".format(r2[0], r1[0],r2_str,r1_str))
for i in range(0,3):
a = func(read[0][i],read[0][i+1])

原文:https://www.cnblogs.com/dabai123/p/11405658.html