论文:Towards End-to-End Lane Detection: an Instance Segmentation Approach
代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
参考:车道线检测算法LaneNet + H-Net(论文解读)
本文提出一种端到端的车道线检测算法,包含 LanNet + H-Net 两个网络模型。其中 LanNet 是一种将语义分割和对像素进行向量表示结合起来的多任务模型,最后利用聚类完成对车道线的实例分割。H-Net 是有个小的网络结构,负责预测变换矩阵 H,使用转换矩阵 H 对同属一条车道线的所有像素点进行重新建模(使用 y 坐标来表示 x 坐标)。
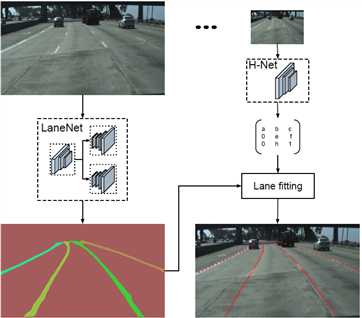
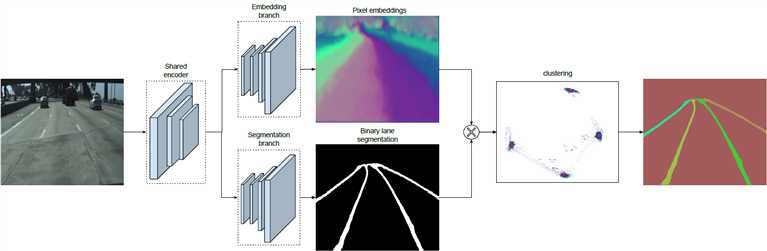
论文中将实例分割任务拆解成语义分割(LanNet 一个分支)和聚类(LanNet一个分支提取 embedding express, Mean-Shift 聚类)两部分。如上图所示,LanNet 有两个分支任务,分别为 a lane segmentation branch and a lane embedding branch。Segmentation branch负责对输入图像进行语义分割(对像素进行二分类,判断像素属于车道线还是背景);Embedding branch对像素进行嵌入式表示,训练得到的embedding向量用于聚类。最后将两个分支的结果进行结合利用 Mean-Shift 算法进行聚类,得到实例分割的结果。
在设计语义分割模型时,论文主要考虑了以下两个方面:
1.在构建label时,为了处理遮挡问题,论文对被车辆遮挡的车道线和虚线进行了还原;
2. Loss使用交叉熵,为了解决样本分布不均衡的问题(属于车道线的像素远少于属于背景的像素),参考论文ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation ,使用了boundedinverse class weight对loss进行加权:
$W_{class} = \frac{1}{ln(c+p_(class))}$
其中,p 为对应类别在总体样本中出现的概率,c 是超参数(ENet论文中是1.02,使得权重的取值区间为[1,50])。
为了区分车道线上的像素属于哪条车道,embedding_branch 为每个像素初始化一个 embedding 向量,并且在设计 loss 时,使属同一条车道线的像素向量距离很小,属不同车道线的像素向量距离很大。
这部分的loss函数是由两部分组成:方差loss($L_{var}$)和距离loss($L_{dist}$):
$L_{var} = \frac{1}{C} \sum_{c=1}^{C} \frac{1}{N_c} [\Arrowvert \mu_c-x_i \Arrowvert -\delta_v]_{+}^{2}$
$L_{dist} = \frac{1}{C(C-1)} \sum_{c_A=1}^{C} \sum_{c_B=1, c_A \ne C_B}^{C} [\delta_d - \Arrowvert \mu_{c_A} - \mu_{c_B} \Arrowvert ]_{+}^{2}$
其中,C 是车道线数量,$N_c$ 是属同一条车道线的像素点数量,$\mu_c$ 是车道线的均值向量,$x_i$ 是像素向量(pixel embedding),$[x]_+ = max(0, x)$。
同一车道线的像素向量,距离车道线均值向量 $\mu_c$ 超过 $\delta_v$ 时, pull force($L_{var}$) 才有意义,使得 $x_i$ 靠近 $\delta_d$;
不同车道线的均值向量 $\mu_{c_A}$ 和 $\mu_{c_B}$ 之间距离小于 $\delta_d$ 时,push force($L_{dist}$) 才有意义,使得 $\mu_{c_A}$ 和 $\mu_{c_B}$ 彼此远离。
为了方面聚类,论文中设定 $\delta_d > 6\delta_v$。
在进行聚类时,首先使用 mean shift 聚类,使得簇中心沿着密度上升的方向移动,防止将离群点选入相同的簇中;之后对像素向量进行划分:以簇中心为圆心,以 $2\delta_v$ 为半径,选取圆中所有的像素归为同一车道线。重复该步骤,直到将所有的车道线像素分配给对应的车道。
LaneNet是基于ENet 的encoder-decoder模型,如图5所示,ENet由5个stage组成,其中stage2和stage3基本相同,stage1,2,3属于encoder,stage4,5属于decoder。
如上图所示,在LaneNet 中,语义分割和实例分割两个任务共享 stage1 和 stage2,并将 stage3 和后面的 decoder 层作为各自的分支(branch)进行训练;其中,语义分割分支(branch)的输出 shape 为W*H*2,实例分割分支(branch)的输出 shape 为W*H*N,W,H分别为原图宽和高,N 为 embedding vector 的维度;两个分支的loss权重相同。

LaneNet的输出是每条车道线的像素集合,还需要根据这些像素点回归出一条车道线。传统的做法是将图片投影到 bird’s-eye view 中,然后使用 2 阶或者 3 阶多项式进行拟合。在这种方法中,变换矩阵 H 只被计算一次,所有的图片使用的是相同的变换矩阵,这会导致地平面(山地,丘陵)变化下的误差。
为了解决这个问题,论文训练了一个可以预测变换矩阵 H 的神经网络 H-Net,网络的输入是图片,输出是变换矩阵 H:
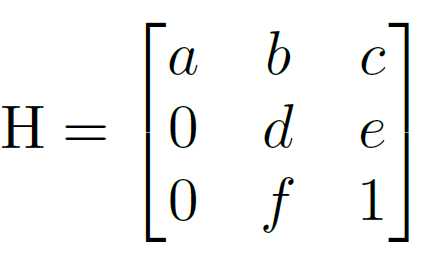
通过置 0 对转置矩阵进行约束,即水平线在变换下保持水平。(即坐标 y 的变换不受坐标 x 的影响)
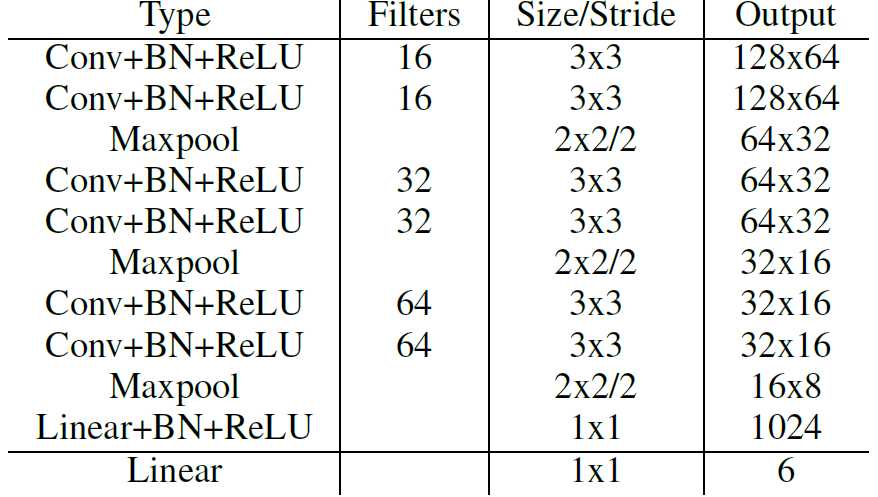
由上式可以看出,转置矩阵 H 只有6个参数,因此H-Net的输出是一个 6 维的向量。H-Net 由 6 层普通卷积网络和一层全连接网络构成,其网络结构如图所示:
Curve fitting的过程就是通过坐标 y 去重新预测坐标 x 的过程:
$P^{‘} = HP$
$w = (Y^TY)^{-1}Y^Tx^{‘}$
$x_i^{‘*} = \alpha y^{‘2} + \beta y^{‘} + \gamma$
$p_i^{*} = H^{-1}p_i^{‘*}$
$Loss = \frac{1}{N} \sum_{i=1}^{N}(x_i^{*} - x_i)^2 $
Dataset : Tusimple
Embedding dimension = 4
δ_v=0.5
δ_d=3
Image size = 512*256
Adam optimizer
Learning rate = 5e-4
Batch size = 8
Dataset : Tusimple
3rd-orderpolynomial
Image size =128*64
Adam optimizer
Learning rate = 5e-5
Batch size = 10
原文:https://www.cnblogs.com/xuanyuyt/p/11523192.html