下面介绍myeclipse与hadoop的集成。
我用的myeclipse版本是8.5.
1、安装hadoop开发插件
在hadoop1.2.1版本的安装包contrib/目录下,已经不再提供hadoop-eclipse-pligin-1.2.1.jar;
而是提供了源代码文件,需要我们自行重新编译成jar包文件;这里方便,大家可以从这里下载:
hadoop-eclipse-plugin-1.2.1.jar.pdf
由于博客上传文件的类型限制,故添加了pdf后缀,下载之后重命名,去掉".pdf"即可。
然后将该文件拷贝到myeclipse根目录下/dropins目录下。
2、设置myeclipse
启动myeclipse,打开Perspective;
【Window】->【Open Perspective】->【Other...】->【Map/Reduce】->【OK】
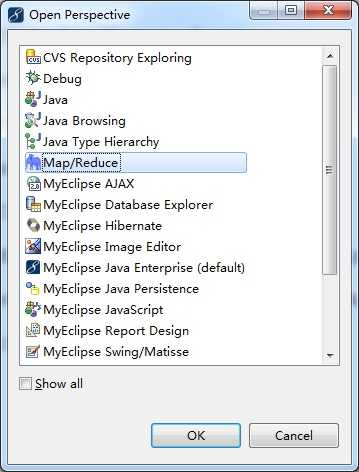
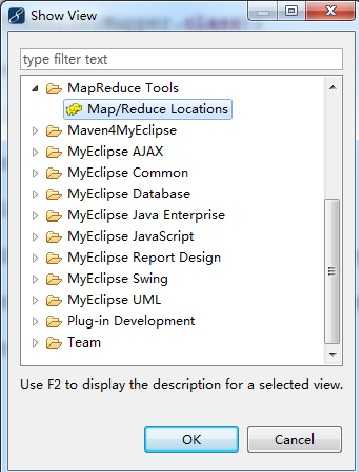
然后打开View:
【Window】->【Show View】->【Other...】->【MapReduce Tools】->【Map/Reduce Locations】->【OK】
然后,添加Hadoop location,在Map/Reduce locations下面的空白处单击右键:
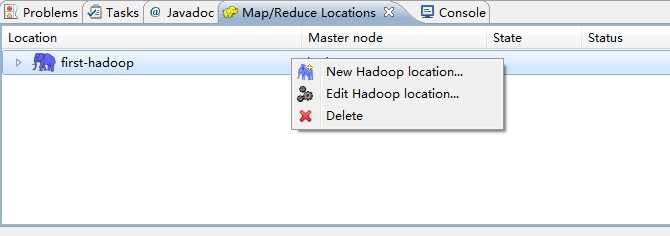
(我这里已经建了一个,所以会有一条,第一次建,应该是空白的)
然后选择edit hadoop location
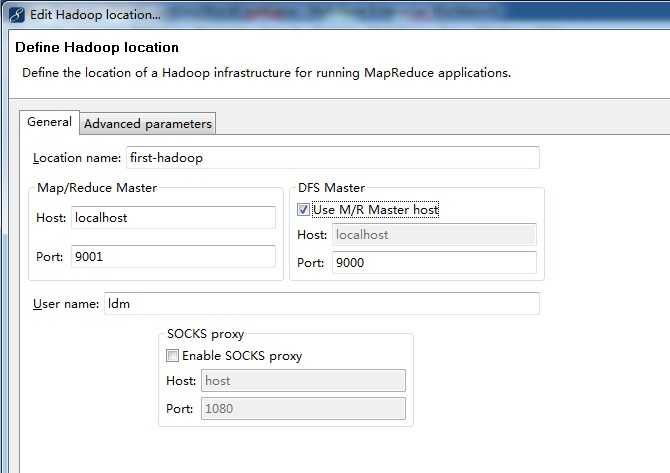
location name: 我填写的是:first-hadoop
Map/Reduce Master 这个框里
Host:就是jobtracker 所在的集群机器,这里写localhost
Hort:就是jobtracker 的port,这里写的是9001
这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port
DFS Master 这个框里
Host:就是namenode所在的集群机器,这里写localhost
Port:就是namenode的port,这里写9000
这两个参数就是core-site.xml里面fs.default.name里面的ip和port
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)
user name:这个是连接hadoop的用户名,我的是ldm。
然后点击finish按钮,此时,这个视图中就有多了一条记录。
重启myeclipse并重新编辑刚才建立的那个连接记录,现在我们编辑advance parameters tab页
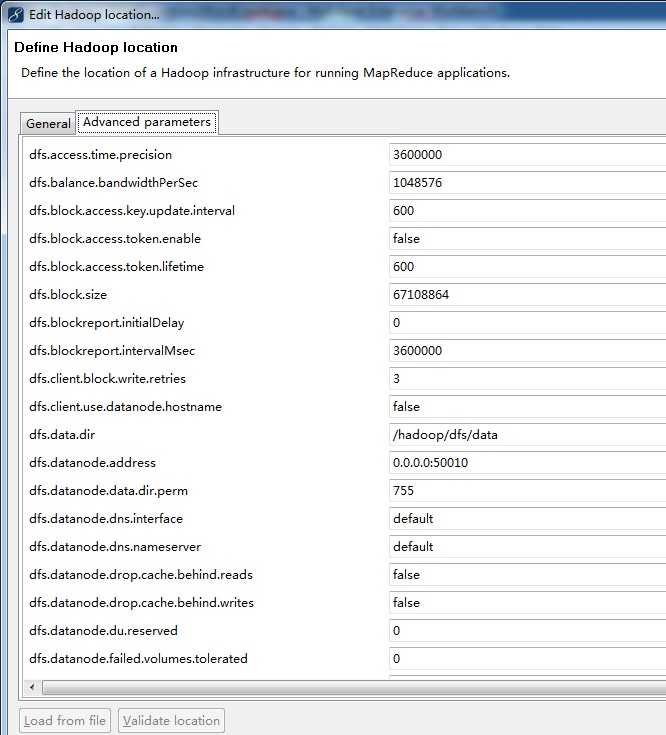
这里大部分的属性都已经自动填写上了,其实就是把core-defaulte.xml、hdfs-defaulte.xml、mapred-defaulte.xml里面的一些配置属性展示出来。
因为在安装hadoop的时候,其site系列配置文件里有改动,所以这里也要弄成一样的设置。
主要关注的有以下属性:
fs.defualt.name:这个在General tab页已经设置了
mapred.job.tracker:这个在General tab页也设置了
dfs.replication:这个这里默认是3,因为我在hdfs-site.xml里面设置成了1,所以这里也要设置成1
然后点击finish,然后就连接上了(先要启动sshd服务,启动hadoop进程),连接上的标志如图:

3、wordcount实例
新建Map/Reduce Project:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->
【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: c:\cygwin64\home\ldm\hadoop】
->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】
新建WordCount类:
然后将hadoop安装包中实例WordCount.java类中的代码拷入。
接下来,新建一个文件夹input,新建两个文件input/file1,input/file2;
文件内容分别为Hello World Bye World和Hello Hadoop Goodbye Hadoop
然后在cygwin终端中运行命令:hadoop fs -put input input
将文件夹input上传到分布式文件系统中,命令中的路径根据自己路径为准。
配置运行参数:
①在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations
②在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
③配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
然后点击run;
如果显示如下,说明已经成功在myeclipse下运行第一个MapReduce程序了。
windows下hadoop的单机伪分布式部署(3),布布扣,bubuko.com
原文:http://www.cnblogs.com/liudmblog/p/3920328.html