python 常用的编码类型:
>>> s = ‘中国‘
>>> s = s.encode(‘utf-8‘) # 这里用utf8进行编码,注意如果括号里面不写类型,那么会默认为是utf8
>>> s.decode(‘utf-8‘) # 这里就要用utf8进行解码
‘中国‘
>>> s1 = ‘中国‘.encode(‘gbk‘)
>>> s1.decode(‘gbk‘)
‘中国‘

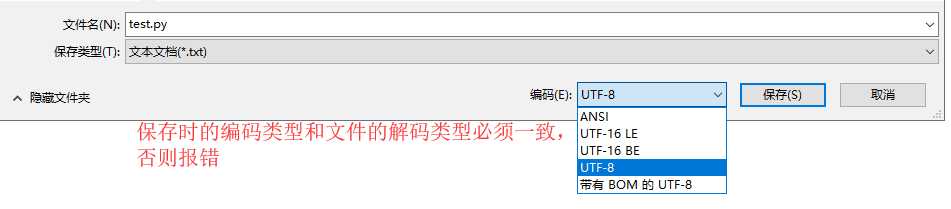
报错一般是如下两种:
1:SyntaxError: (unicode error) ‘utf-8‘ codec can‘t decode byte 0xc4 in position 0:invalid continuation byte
2:SyntaxError: encoding problem: gbk
原文:https://www.cnblogs.com/su-sir/p/11525974.html