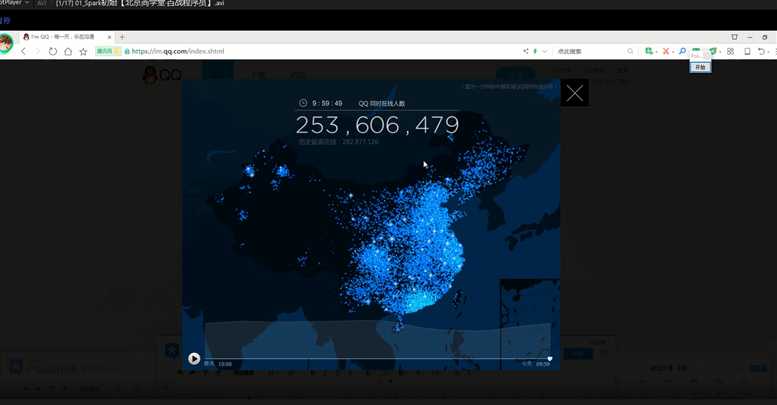
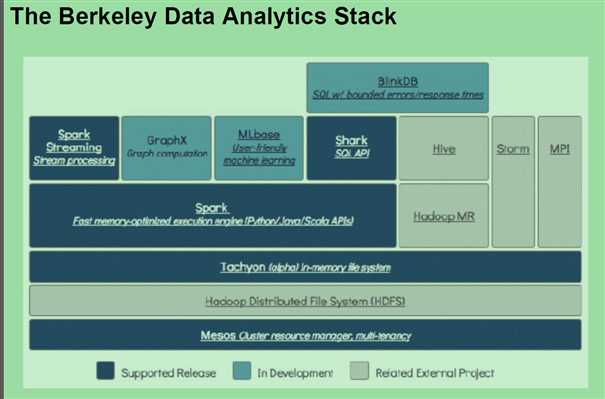
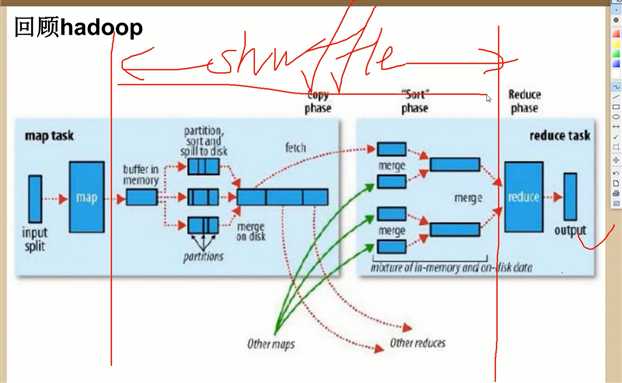
http://spark.apache.org/ RM spark 1:100 内存; 1:10磁盘。 DAG You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources. Mesos resilient 英 [r?‘z?l??nt] 美 [r?‘z?l??nt] adj. 弹回的,有弹力的 stom 流式处理, 数据在源源不断的输入,源源不断的产生。 spark streaming :流式处理 spark core : 批处理。 spark sql : 即席处理。(sql查询)
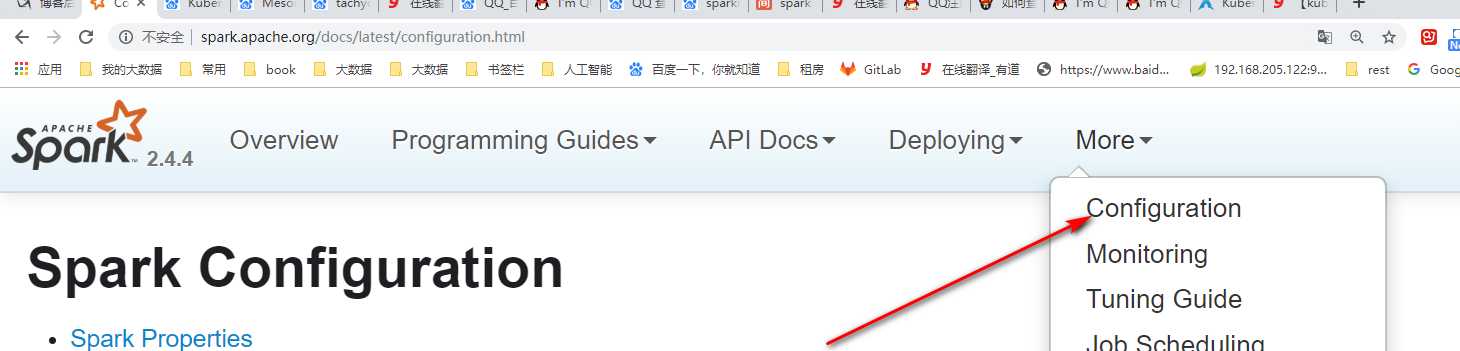
spark官方配置项 http://spark.apache.org/docs/latest/configuration.html
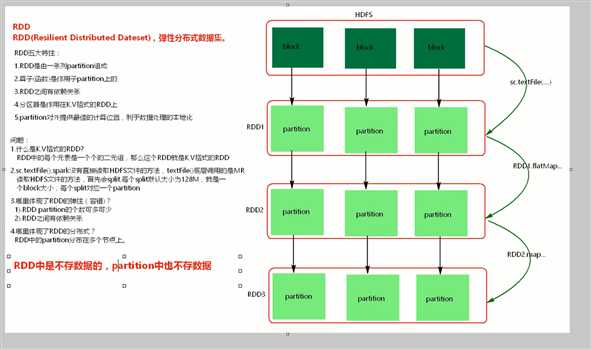
pair n. 一对,一双,一副 vt. 把…组成一对 RDD(Resilient Distributed Datasets) [1] ,弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。
## scala WC排序
package com.bjsxt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("ScalaWordCount")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("src/words") // 一行行读取的
val words:RDD[String] = lines.flatMap(line =>{
line.split(" ")
})
val pairWords:RDD[(String, Int)] = words.map(word =>{
new Tuple2(word,1)
})
/**
* reduceByKey 先分组,后对每一组内的kye对应的value去聚合
*/
val reduce = pairWords.reduceByKey((v1:Int,v2:Int) => { v1 + v2 })
// val result = reduce.sortBy(tuple =>{tuple._2},false)
val reduce2:RDD[(Int, String)] = reduce.map(tuple=>{tuple.swap}); // string,int ==> int,string
// sortByKey 按key降序
val result = reduce2.sortByKey(false).map(_.swap);
result.foreach(tuple =>{println(tuple)})
sc.stop()
// 简化版
// val conf = new SparkConf().setMaster("local").setAppName("ScalaWordCount")
// new SparkContext(conf).textFile("src/words").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).foreach(println(_))
}
}
java spark WC 排序
package com.bjsxt.spark;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class JavaSparkWorkCount {
public static void main(String[] args) {
/**
* conf
* 1.可以设置spark的运行环境,
* 2.可以设置spark在webui中显示的application的名称
* 3.可以设置当前spark application 运行的资源(内存+core:核心)
* 如4核8线程 与spark核不一样;可以最多提供给spark 8个core;spark的核只能跑一个task
* 物理机4核8线程;表示核双线程:表示某一时刻可以同时跑两个线程;不存在cpu争抢
*
*
* spark运行模式:
* 1.local --zai1eclipse,IDEA中开发spark程序要用local模式,本地模式,多用于测试
* 2.standlone -- spark 自带的资源调度框架,支持分布式搭建,Spark任务可以依赖standlone调度资源
* 3.yarn -- hadoop 生态圈中资源调度框架。Spark也可以基于yarn调度资源
* 4.mesos -- 资源调度框架
*/
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("JavaSparkWorkCount");
conf.set("内存", "10G");
/**
* SparkContext 是通往集群的唯一通道
*/
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文件
JavaRDD<String> lines = sc.textFile("./words");
// 一对多;进来一条数据,出多条数据
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
* FlatMapFunction<String, String> == line,word
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
// 在java中如果想让某个RDD转换为K,V格式,使用xxxToPair
// K,V 格式的RDD:JavaPairRDD<String,Integer>
// JavaRDD<String> ==> JavaRDD<k,v>
JavaPairRDD<String,Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
/**
* reduceByKey
* 1.先将相同的key分组
* 2.对每一组的key对应的value去按照你的逻辑去处理
*/
// <Integer, Integer, Integer> 进来一个,进来一个, 出去一个
JavaPairRDD<String, Integer> reduce = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// v1 v2 进来后返回给v1;再看有没有v3,如果有v3,v1(v1+v2)和v3进来。
return v1 + v2;
}
});
JavaPairRDD<Integer, String> mapToPair = reduce.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple)
throws Exception {
// return new Tuple2<Integer, String>(tuple._2,tuple._1);
return tuple.swap();
}
});
JavaPairRDD<Integer,String> sortByKey = mapToPair.sortByKey(false);
JavaPairRDD<String,Integer> mapToPair2 = sortByKey.mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple)
throws Exception {
return tuple.swap();
}
});
mapToPair2.foreach(new VoidFunction<Tuple2<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple);
}
});
sc.stop();
}
}
原文:https://www.cnblogs.com/xhzd/p/11531159.html