最近基于session的推荐系统火热起来,但是大多数的工作没有考虑用户长期的稳定偏好和演变。这篇文章提出了一个novel Behavior-Intensive Neural Network(BINN)模型,该模型结合了用户的历史稳定偏好和当前的购买动机,来进行下一次推荐。该模型的两个主要部件分别为:Neural Item Embedding 和 Discriminative Behaviors Learning 。有区别的学习目标用户的历史偏好和当前动机。
看完摘要
问题1:历史稳定偏好是如何知道稳定的呢?
问题2:这两部件是怎么实现?
随着时间的变化用户的历史行为自然的会形成一个行为交互序列,我们用以下的形式代表
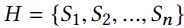
其中$|H|=n$表示用户的数量。对于每一个用户$u$都会有对应的交互序列
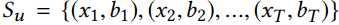
其中$x_j$代表用户$u$与第$j$个item进行交互,$b_j$表示行为类型(比如:点击,加入购物车,购买),我们的the next-based的推荐任务就是去预测下一个item,即$x_{T+1}$
首先回顾Google的word2vec,Skip-gram的模型结构
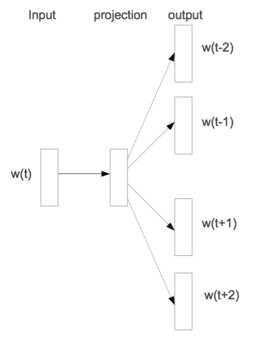
Skip-gram是利用当前词预测其上下文词。给定一个训练序列$w_1,w_2,...,w_T$,该模型的目标函数是最大化平局的log概率:
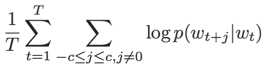
其中$c$表示context的大小,c越大,训练样本越大,准确率越高,同时训练时间也变长。在skip-gram模型中,$P(w_{i+j}|w_t)$利用softmax函数定义如下:
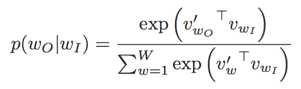
其中$W$是语料库的大小,但是在通常情况下,语料库特别大,直接计算不现实。为了解决这个问题,提出了2种方法,一个是hierarchical softmax,另一个方法是negative sample。对于negative sample,具体就是把目标函数修正为
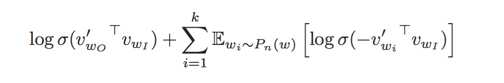
其中$P_n(w)$是噪声分布。即训练目标是使用logistics regression区分出目标词和噪音词。
item2vec就是把用户的交互行为序列当成一个word2vec种句子,出现在同一个集合的商品被视为positive。对于集合$w_1,w_2,...,w_k$目标函数:
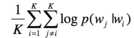
同时也采用负采样, 并将skip-gram中的sfotmax函数代替为
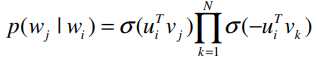
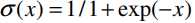
其中参数$N$为确定每个positive要绘制的negative的数量
在本篇文章中,作者改进了item2vec。
作者认为,和普通的句子不同的是,有些item是经常被访问,即在$H$中将会经常出现这些商品,这是因为用户在进行商品的对比和选择,所以往往会有相似的物品交叉出现,这也表明了作者的动机,同时,那些低频率的商品可能是用户无意间点击的,这样可以去除噪音。所以,目标函数改写为
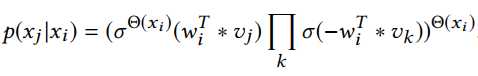
其中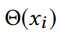 是在序列中$x_i$出现的频率,同时目标函数变成:
是在序列中$x_i$出现的频率,同时目标函数变成:
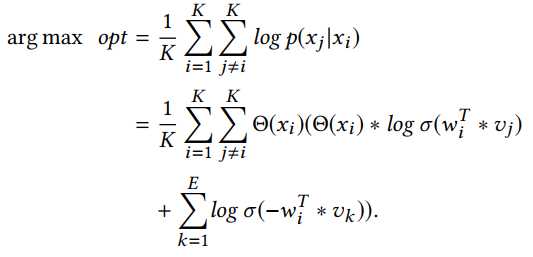
原文:https://www.cnblogs.com/simplekinght/p/11545180.html