学习得到的模型适用于新样本的能力称为泛化能力
学习器能拟合样本所有数据,即把训练样本自身的一些特点当作所有潜在样本的一般性质,导致泛化能力下降的现象。
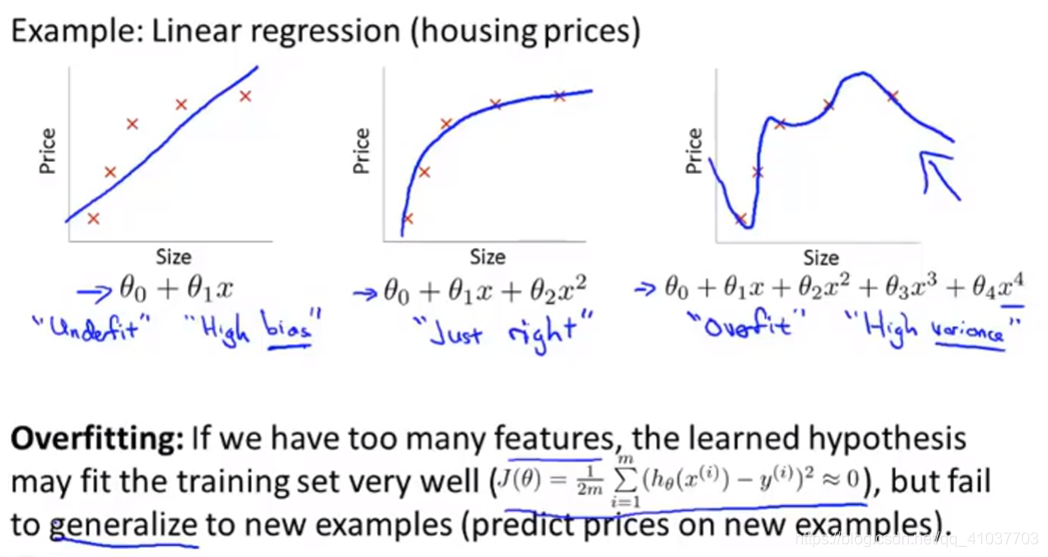
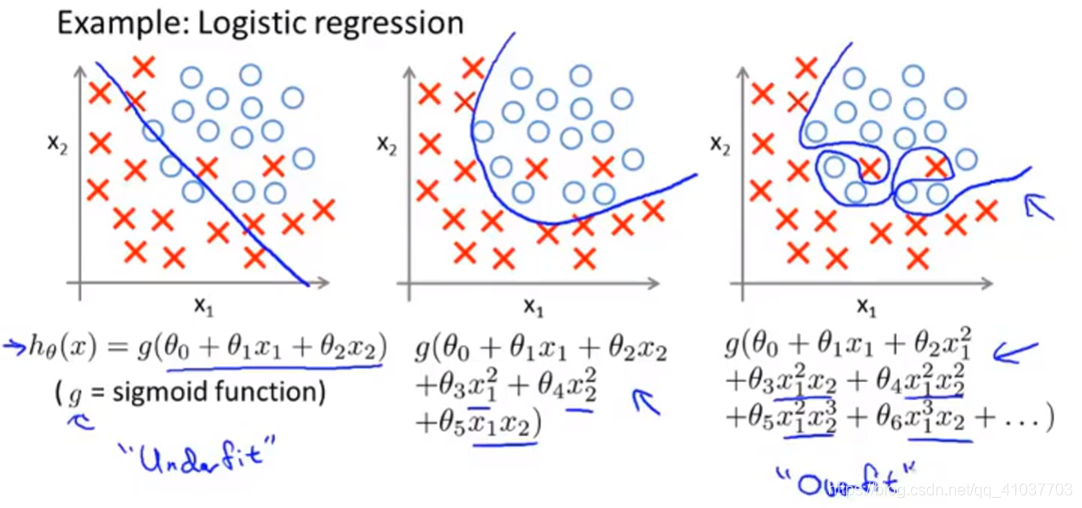
分类错误样本数占样本总数的比率,==设定样本数少的类别作为正类别==
机器预测的正结果中用户真正需要的结果所占的比例 eg:判断得癌症人中,真正得癌症的人的比率
用户真正需要的结果中机器成功预测结果所占的比例 eg:所有得癌症的人中,能判断出得癌症人的比率
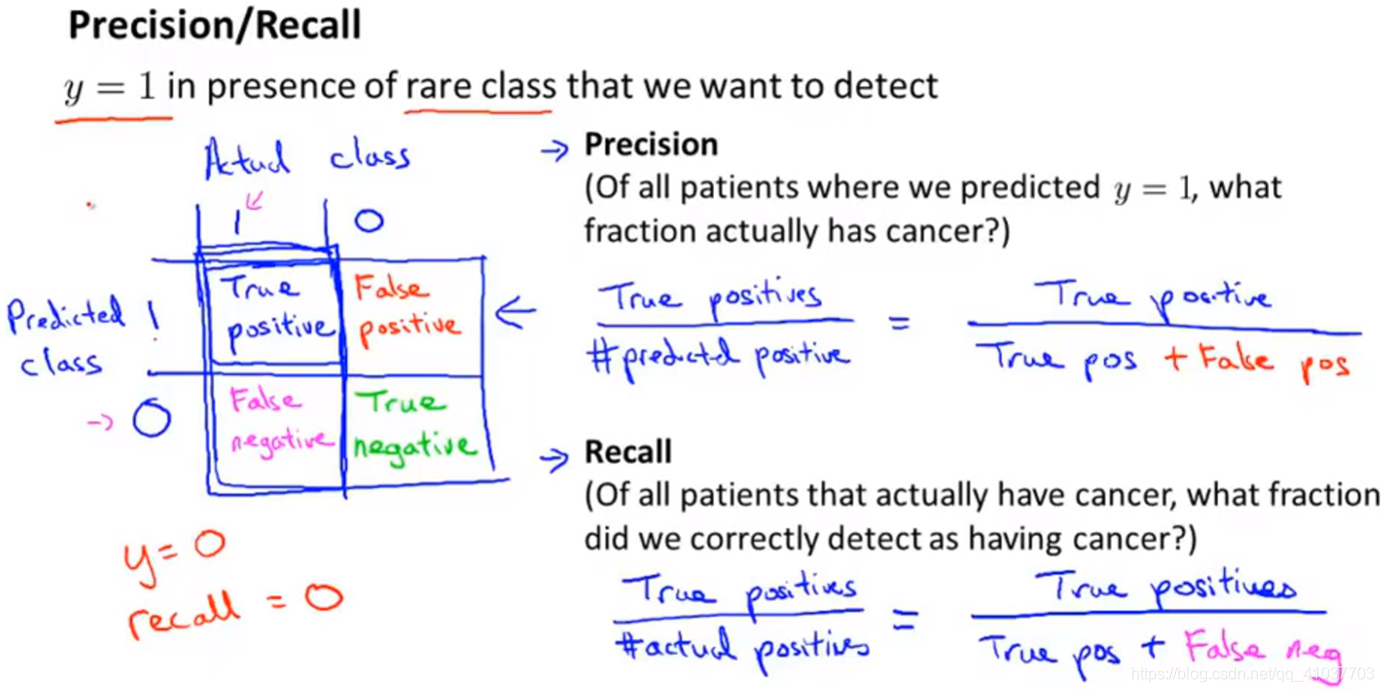
通过改变判断阈值,高阈值,P高R低;低阈值P低R高

查准率与查全率相等时的值
各统计变量倒数算术平均数的倒数。给较低的值更高的权重
\[
\frac{1}{F1}=\frac{1}{2}(\frac{1}{P}+\frac{1}{R})\tag{1.1}
\]
\[ F_1=2\frac{PR}{P+R}\tag{1.2} \]
标准正态分布的平方
即逻辑数据类型,取值为0或1
原文:https://www.cnblogs.com/jestland/p/11548440.html