相比于神经网络,不用担心陷入局部最优问题,因为是凸优化
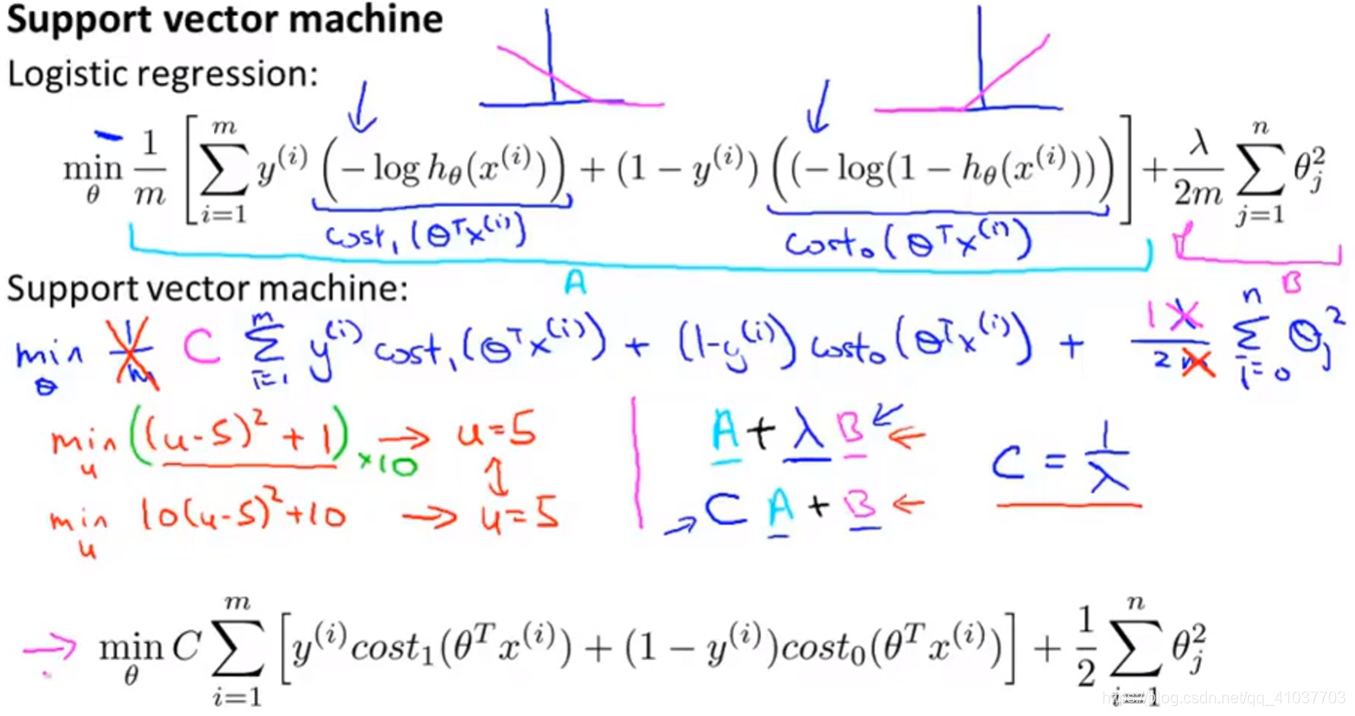
\[
h_{\theta}(x)=\left\{\begin{array}{ll}{1,} & {\text { if } \theta^{T} x \geq 0} \\ {0,} & {\text { other }}\end{array}\right.\tag{9.1}
\]
最小化上式,得到参数\(\theta\)后下次代入为SVM的假设函数,
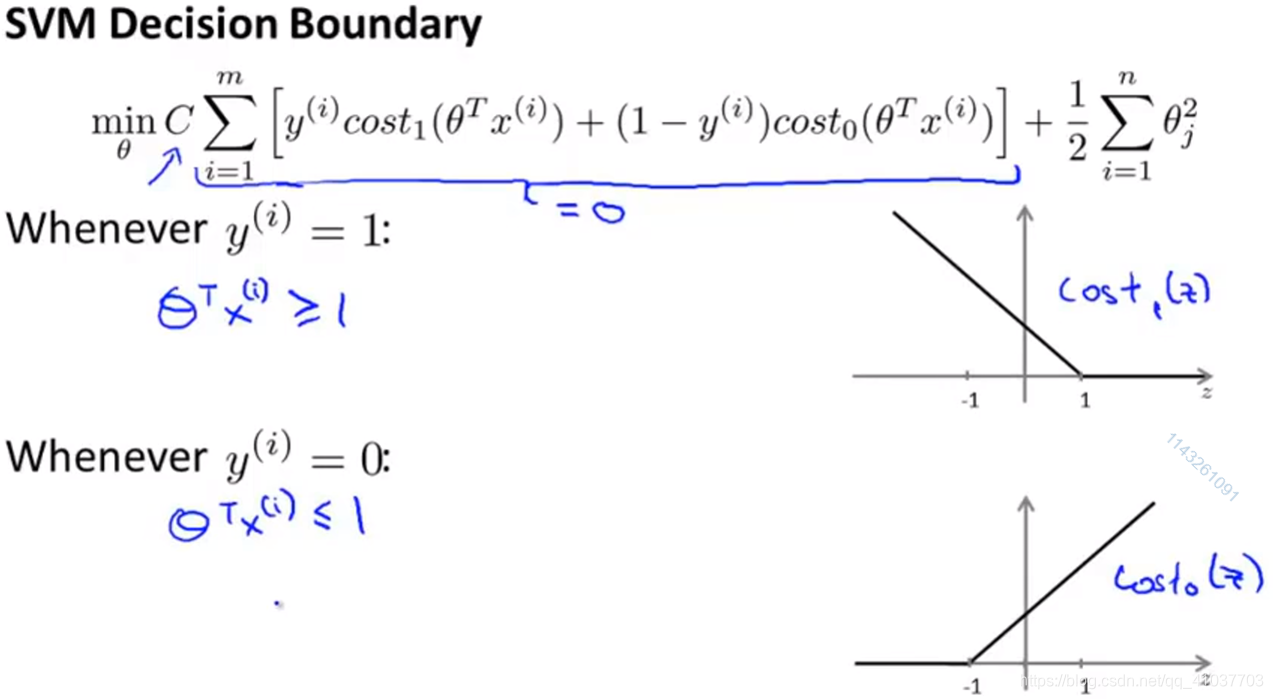
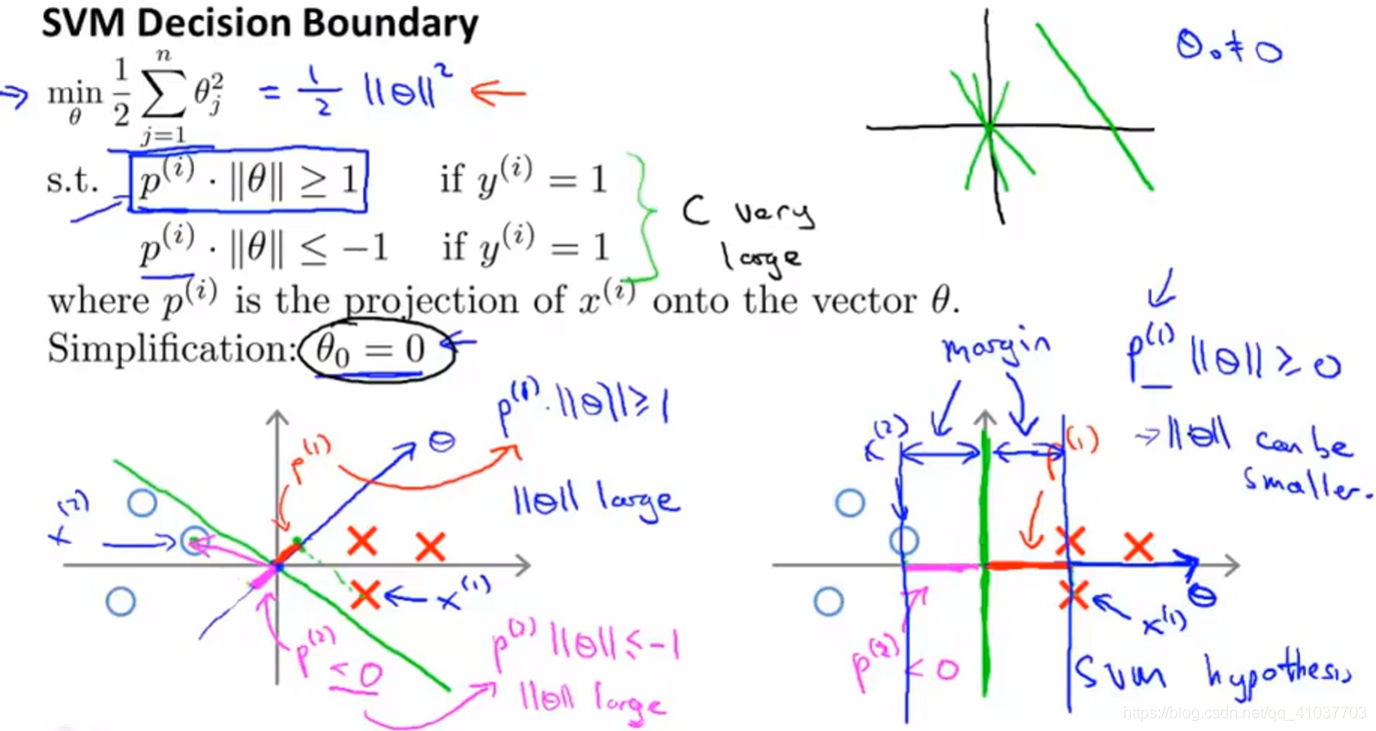
SVM采用该方法可解决非线性问题

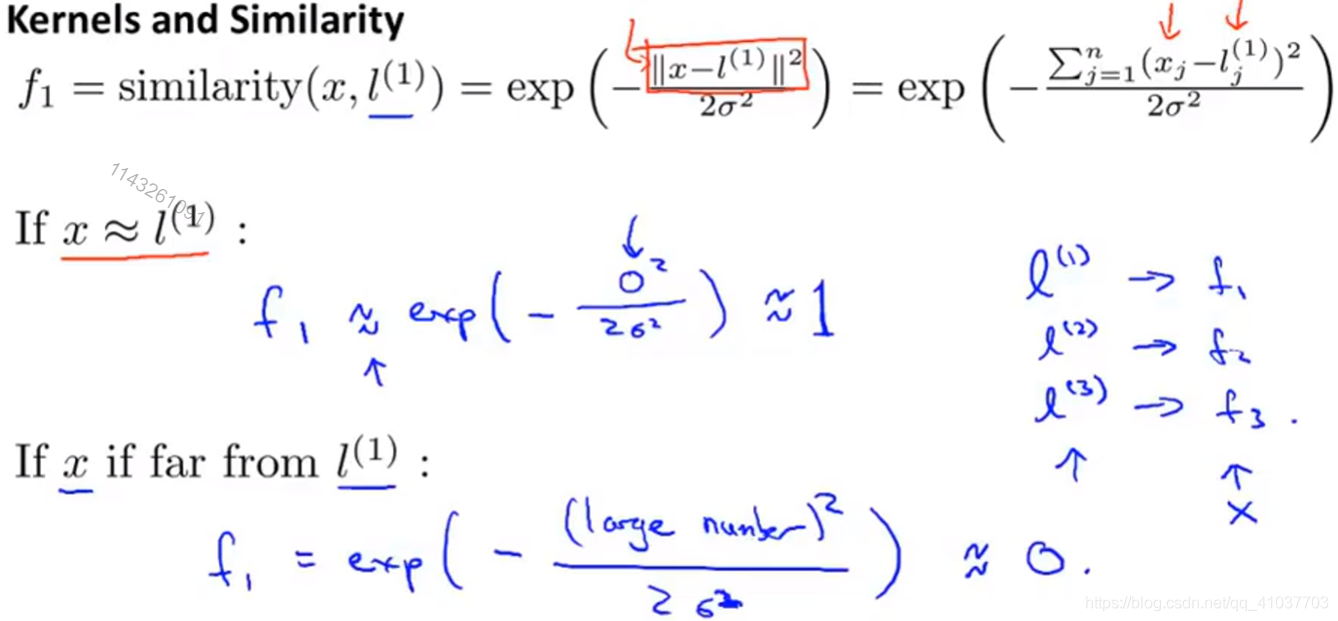
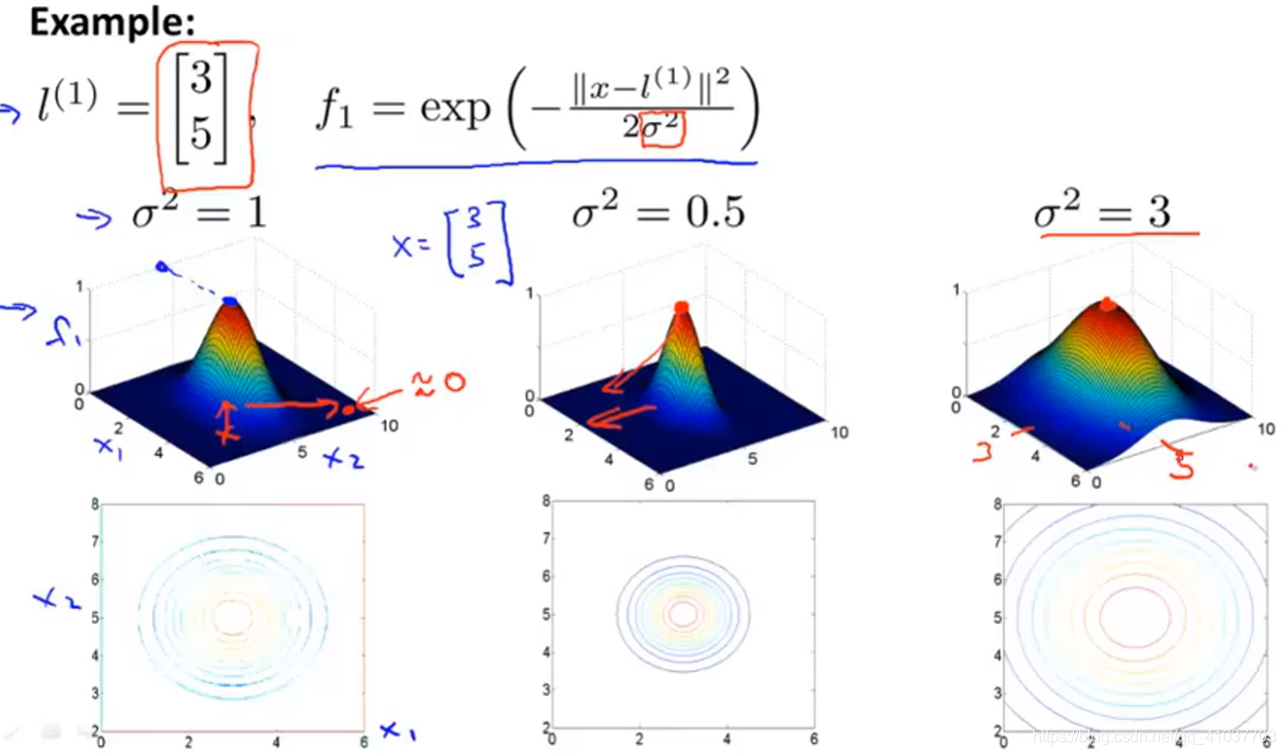
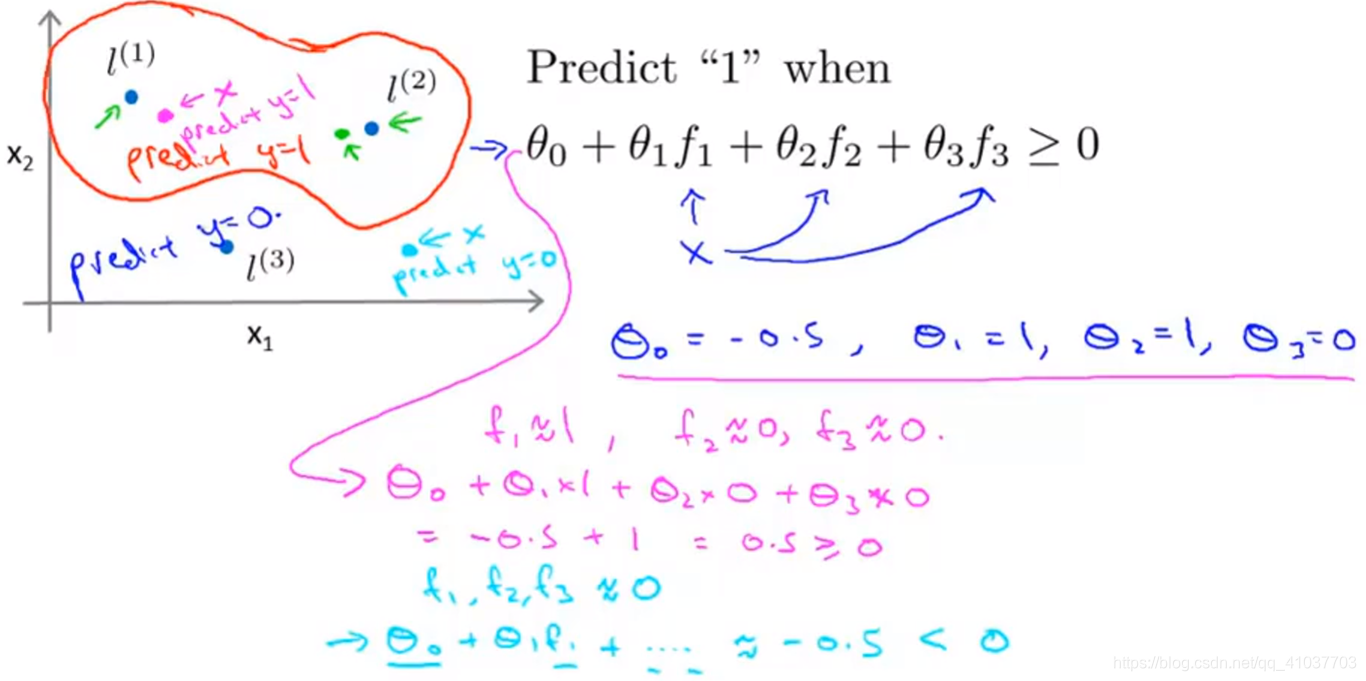
\(f\)即为样本X根据高斯核函数和标记计算得到的特征变量。
\(f\in[0,1]\)当训练好参数\(\theta\)后,根据一个样本x到不同标记的距离大小不同,特征变量不同,即赋予参数不同权重,最后计算出\(\theta^Tf\),判断y=0或y=1,从而得到非线性边界
将所有训练样本均作为标记点

即没有核参数的函数

效果较差,针对非线性问题

C(\(=\frac{1}{\lambda}\))大:即\(\lambda\)小,\(\theta\)大,意味着低偏差,高方差,倾向于过拟合
C(\(=\frac{1}{\lambda}\))小:即\(\lambda\)大,\(\theta\)小,意味着高偏差,低方差,倾向于欠拟合
\(\sigma^2\)大,特征量\(f\)随着x变化缓慢,即x变化很多,\(\theta^Tf\)变化很小,边界变化慢偏差较大
\(\sigma^2\)小,特征量\(f\)随着x变化剧烈,即x变化很小,\(\theta^Tf\)变化很多,边界变化快方差较大
选取参数C
根据样本情况选取合适的核函数
编写选取的核函数,输入样本生成所有的特征变量
根据样本情况缩放样本比例
若特征数量n(10000)>样本数m(10-1000),使用逻辑回归或者线性核函数,因为数据少无法拟合复杂非线性函数
若特征数量n(1-1000)<样本数m(10-50000)适中,使用高斯核函数,
若特征数量n(1-1000)<样本数m(50000+)很大,带高斯核函数的SVM会运行很慢,手动创建更多特征变量,使用逻辑回归和线性核函数
原文:https://www.cnblogs.com/jestland/p/11548527.html