int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存,)
字符类型,必须提供max_length参数, max_length表示字符长度。
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
一个证书类型,取值范围是 [-9223372036854775808,9223372036854775807]
相当于varchar类型
十进制小数。有两个参数:①max_digits,小数总长度 ②decimal_places,有几个小数位
用于指定某个字段可以为空(null=True)
如果设置为unique=True 则该字段在此表中必须是唯一的 。
如果设置db_index=True,那么该字段会创建索引。
为字段指定默认值
配置auto_now_add=True,创建数据记录的时候会自动把当前时间添加到数据库,后续的修改该字段不会自动更新。
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 ‘一对多‘中‘多‘的一方。
外键关联中的多对多关系
外键关联中的一对一关系。一对一其实就是把一张数据很多的表按照数据的使用频率分为两张表
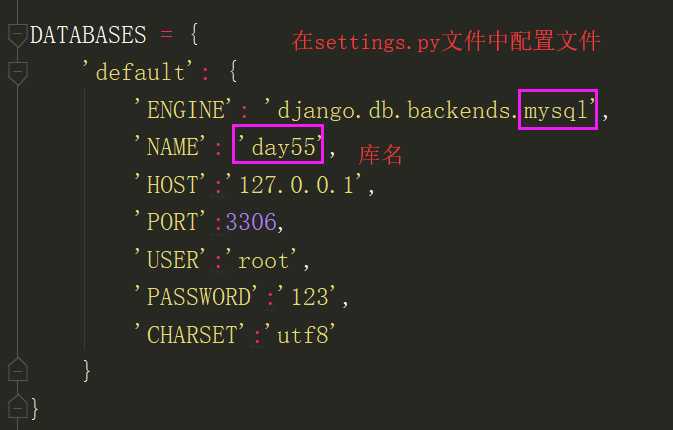
在开始查询之前,先做一点准备工作,在Django的配置文件中,配置mysql数据库。
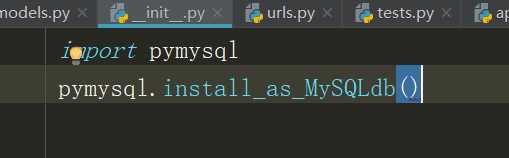
然后在项目或app下面的__init__.py文件中指明要用pymysql连接数据库
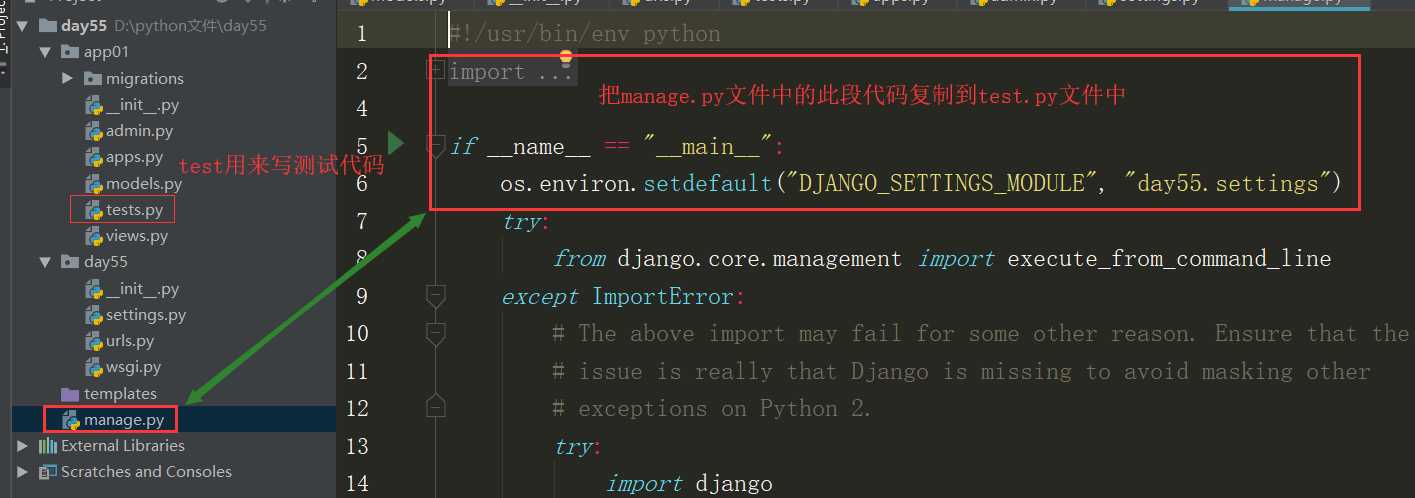
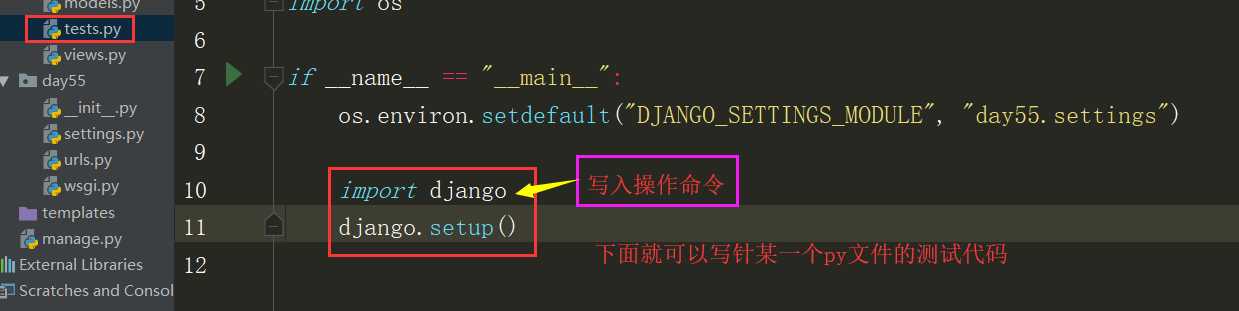
在表查询之前,先做一些准备工作。我在tests.py文件中做测试。那么首先要写以下类似于manage.py的代码。
如果想在测试时,查看内部的sql语句,可以在配置文件中加入一下配置。
LOGGING = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘handlers‘: { ‘console‘:{ ‘level‘:‘DEBUG‘, ‘class‘:‘logging.StreamHandler‘, }, }, ‘loggers‘: { ‘django.db.backends‘: { ‘handlers‘: [‘console‘], ‘propagate‘: True, ‘level‘:‘DEBUG‘, }, } }
**********************************查询方法******************************************
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序(‘-id‘)/(‘price‘)
<6> reverse(): 对查询结果反向排序 >>>前面要先有排序才能反向
<7> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<8> first(): 返回第一条记录
<9> last(): 返回最后一条记录
<10> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<11> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
<12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<13> distinct(): 从返回结果中剔除重复纪录
all()
filter()
exclude()
order_by()
reverse()
distinct()
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
get()
first()
last()
exists()
count()
1、基于create新增,通过此方法新增得到的是一个数据对象,可以通过点语法取值

2、基于对象的绑定方法新增

1、基于对象修改

2、基于queryset修改

1、基于queryset

2、基于对象

1、all():拿到所有结果

2、filter(**kwargs): 它包含了与所给筛选条件相匹配的对象。filter内可以传多个条件,但要注意这些条件之间是and的关系

3、get:返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误(不推荐使用)

4、exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象

5、order_by(*field): 对查询结果排序,默认是升序。可以在排序的字段前面加一个减号就是降序

6、reverse(): 对查询结果反向排序 >> > 前面要先有排序才能反向

7、count(): 返回数据库中匹配查询(QuerySet) 的对象数量。

8、first(): 返回第一条记录

9、last(): 返回最后一条记录

10、exists(): 如果QuerySet包含数据,就返回True,否则返回False

11、values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列

12、values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列

13、distinct(): 从返回结果中剔除重复纪录 去重的对象必须是完全相同的数据才能去重

# 查询价格大于200的书籍 res = models.Book.objects.filter(price__gt=200) # gt表示大于 print(res) # 查询价格小于200的书籍 res = models.Book.objects.filter(price__lt=200) # lt表示小于 print(res) # 查询价格大于等于200.22的书籍 res = models.Book.objects.filter(price__gte=200.22) # 加上‘e‘就表示等于的意思 print(res) # 查询价格小于等于200.22的书籍 res = models.Book.objects.filter(price__lte=200.22) print(res) # 查询价格要么是200,要么是300,要么是666.66 res = models.Book.objects.filter(price__in=[200,300,666.66]) # 使用in加类表来表示 print(res) # 查询价格在200到800之间的 res = models.Book.objects.filter(price__range=(200,800)) # 两边都包含 print(res) # 查询书籍名字中包含p的 """原生sql语句 模糊匹配 like % _ """ res = models.Book.objects.filter(title__contains=‘p‘) # contains仅仅只能拿小写p res = models.Book.objects.filter(title__icontains=‘p‘) # icontains忽略大小写 print(res) # 查询书籍是以三开头的 res = models.Book.objects.filter(title__startswith=‘三‘) # startswith:以....开头 res1 = models.Book.objects.filter(title__endswith=‘p‘) # endswith:以.....结尾 print(res) print(res1) # 查询出版日期是2017的年(******) res = models.Book.objects.filter(create_time__year=‘2017‘) print(res) 例题

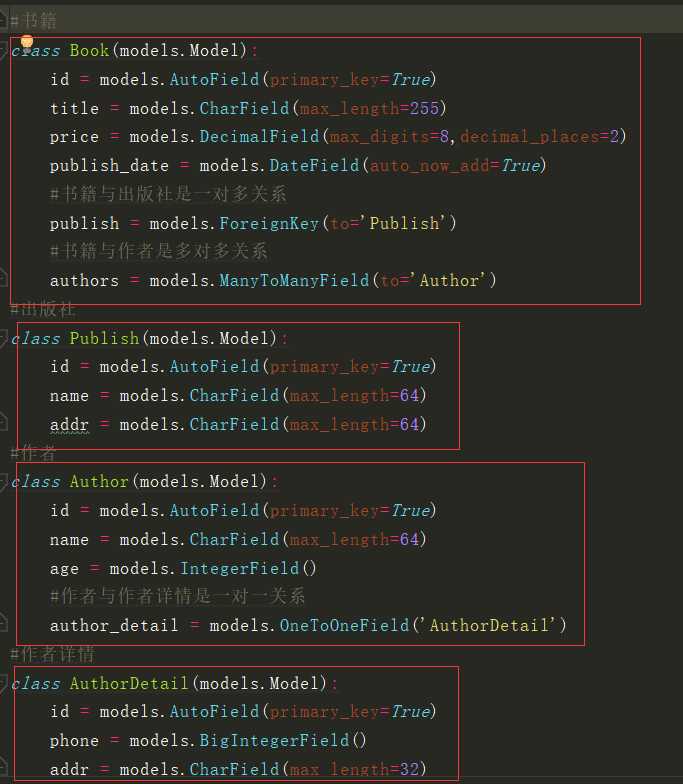
from django.db import models # Create your models here. #书籍 class Book(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=255) price = models.DecimalField(max_digits=8,decimal_places=2) publish_date = models.DateField(auto_now_add=True) #书籍与出版社是一对多关系 publish = models.ForeignKey(to=‘Publish‘) #书籍与作者是多对多关系 author = models.ManyToManyField(to=‘Author‘) #出版社 class Publish(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=64) addr = models.CharField(max_length=64) #作者 class Author(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=64) age = models.IntegerField() #作者与作者详情是一对一关系 author_detail = models.OneToOneField(‘AuthorDetail‘) #作者详情 class AuthorDetail(models.Model): id = models.AutoField(primary_key=True) phone = models.BigIntegerField() addr = models.CharField(max_length=64)
一对多的增删改查 增 第一种方法: models.Book.objects.create(title=‘水浒传‘,price=155.66,publish_id=1) 第二种方法: publish_obj = models.Publish.objects.filter(pk=1).first() models.Book.objects.create(title=‘龙珠超‘,price=66.66,publish=publish_obj) 改 1.传数字的 models.Book.objects.filter(pk=2).update(publish_id=3) 2.传对象的 publish_obj = models.Publish.objects.filter(pk=2).first() models.Book.objects.filter(pk=1).update(publish=publish_obj) 删 models.Book.objects.filter(pk=2).delete()
# 多对多字段的增删查改 #增 book_obj = models.Book.objects.filter(pk=2).first() print(book_obj.authors) # 对象点击多对多虚拟字段,先执行这一步,才能执行下一步 book_obj.authors.add(2,3) # 添加作者 #添加多个 author_obj = models.Author.objects.filter(pk=1).first() author_obj1 = models.Author.objects.filter(pk=2).first() author_obj2 = models.Author.objects.filter(pk=3).first() book_obj.authors.add(author_obj) book_obj.authors.add(author_obj1,author_obj2) """ add() 是给书籍添加作者 括号内既可以传数字也可以传对象 并且支持一次性传多个 逗号隔开即可 """ # 改 # 将主键为1的书籍对象 作者修改为2,3 book_obj = models.Book.objects.filter(pk=1).first() book_obj.authors.set([2,]) book_obj.authors.set([2,3]) author_obj = models.Author.objects.filter(pk=1).first() author_obj1 = models.Author.objects.filter(pk=2).first() author_obj2 = models.Author.objects.filter(pk=3).first() book_obj.authors.set([author_obj,]) book_obj.authors.set([author_obj, author_obj1, author_obj2]) """ set()括号内 需要传一个可迭代对象 可迭代对象中 可以是多个数字组合 也可以是多个对象组合 但是不要混着用!!! """ # 删 book_obj = models.Book.objects.filter(pk=1).first() #根据id删除 # book_obj.authors.remove(3) book_obj.authors.remove(1,2) # 删除作者id为1和2的数据 #根据对象删除 author_obj = models.Author.objects.filter(pk=1).first() author_obj1 = models.Author.objects.filter(pk=2).first() author_obj2 = models.Author.objects.filter(pk=3).first() book_obj.authors.remove(author_obj) book_obj.authors.remove(author_obj1,author_obj2) """ remove()括号内既可以传数字 也可以传对象 并且支持传对个 逗号隔开即可 """ # 将某本书跟作者的关系全部清空 book_obj = models.Book.objects.filter(pk=1).first() book_obj.authors.clear() # 清空当前书籍与作者的所有关系 """ add() set() remove() 上面三个都支持传数字 或者对象 并且可以传多个 但是set需要传可迭代对象 clear() clear括号内不需要传任何参数 """
表与表之间的关系:
一对一(OneToOneField):一对一字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
一对多(ForeignKey):一对多字段建在多的那一方
多对多(ManyToManyField):多对多字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
正向和反向查询 正向 ----> 关联字段在当前表中,从当前表向外查叫正向 反向 ---> 关联字段不在当前表中,当当前表向外查叫反向
正向查询按外键字段
反向查询按表名小写
一对一的查询 正向:author---关联字段在author表里--->authordetail 按字段 反向:authordetail---关联字段在author表里--->author 按表名小写 一对多的查询 正向:book---关联字段在book表里--->author 按字段 反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书 多对多的查询 正向:book---关联字段在book表里--->author 按字段 反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书
一共五张表:author authordetail book publish book_authors
其中author与authordetail 为一对一的关系,用了OneToOneField
book与author是多对多的关系,用ManyToMany,自动创建关联的表
book与publish是一对多的关系,直接用ForeignKey创建即可
# 1.查询书籍id是1 的出版社名称 book_obj = models.Book.objects.filter(pk=1).first() print(book_obj.publish.name) print(book_obj.publish.addr) # 2.查询书籍id是2 的作者姓名 book_obj = models.Book.objects.filter(pk=2).first() print(book_obj.authors) # app01.Author.None print(book_obj.authors.all()) res = book_obj.authors.all() for r in res: print(r.name) # 3.查询作者是jason的家庭住址 author_obj = models.Author.objects.filter(name=‘jason‘).first() print(author_obj.author_detail.addr) # 4.查询出版社是东方出版社出版的书籍 publish_obj = models.Publish.objects.filter(name=‘东方出版社‘).first() # print(publish_obj.book_set) # app01.Book.None print(publish_obj.book_set.all()) # 5.查询作者是jason的写过的所有的书籍 author_obj = models.Author.objects.filter(name=‘jason‘).first() print(author_obj.book_set) # app01.Book.None print(author_obj.book_set.all()) # 6.查询电话号码是130的作者姓名 author_detail_obj = models.AuthorDetail.objects.filter(phone=130).first() print(author_detail_obj.author.name) print(author_detail_obj.author.age) """ 当你反向查询的结果是多个的时候 就需要加_set 否则直接表明小写即可 """ # 7.查询书籍id为1 的作者的电话号码 book_obj = models.Book.objects.filter(pk=1).first() author_list = book_obj.authors.all() for author_obj in author_list: print(author_obj.author_detail.phone)
# 正向 # 1.查询jason作者的手机号 res = models.Author.objects.filter(name=‘jason‘).values(‘author_detail__phone‘,‘author_detail__addr‘) print(res) res1 = models.AuthorDetail.objects.filter(author__name=‘jason‘).values(‘phone‘) print(res1) # 查询jason这个作者的年龄和手机号 # 正向 res = models.Author.objects.filter(name=‘jason‘).values(‘age‘,‘author_detail__phone‘) print(res) # 反向 res1 = models.AuthorDetail.objects.filter(author__name=‘jason‘).values(‘phone‘,‘author__age‘) print(res1) # 查询手机号是130的作者年龄 # 正向 res = models.AuthorDetail.objects.filter(phone=130).values(‘author__age‘) print(res) # # 反向 res1 = models.Author.objects.filter(author_detail__phone=130).values(‘age‘) print(res1) # 查询书籍id是1 的作者的电话号码 res = models.Book.objects.filter(pk=1).values(‘authors__author_detail__phone‘) res1 = models.Book.objects.filter(pk=1).values(‘外键字段1__外键字段2__外键字段3__普通字段‘) print(res) """只要表里面有外键字段 你就可以无限制跨多张表""" # 1.查询出版社为北方出版社的所有图书的名字和价格 res = models.Publish.objects.filter(name=‘北方出版社‘).values(‘book__title‘,‘book__price‘) print(res) # 2.查询北方出版社出版的价格大于19的书 res = models.Book.objects.filter(price__gt=19,publish__name=‘北方出版社‘).values(‘title‘,‘publish__name‘) print(res)
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
用到的内置函数:
from django.db.models import Avg, Sum, Max, Min, Count
例子:
from django.db.models import Max,Min,Count,Sum,Avg # 查询主键值为3的书籍的作者个数 res = models.Book.objects.filter(pk=3).aggregate(count_num=Count(‘authors‘)) print(res) # 查询所有出版社出版的书的平均价格 res = models.Publish.objects.aggregate(avg_price=Avg(‘book__price‘)) print(res) # 统计东方出版社出版的书籍的个数 res = models.Publish.objects.filter(name=‘东方出版社‘).aggregate(count_num=Count(‘book__id‘))
# 分组查询(group_by) annotate # 统计每个出版社出版的书的平均价格 res = models.Publish.objects.annotate(avg_price=Avg(‘book__price‘)).values(‘name‘,‘avg_price‘) print(res) # 统计每一本书的作者个数 res = models.Book.objects.annotate(count_num=Count(‘authors‘)).values(‘title‘,‘count_num‘) print(res) # 统计出每个出版社卖的最便宜的书的价格 res = models.Publish.objects.annotate(min_price=Min(‘book__price‘)).values(‘name‘,‘min_price‘) print(res) # 查询每个作者出的书的总价格 res = models.Author.objects.annotate(sum_price=Sum(‘book__price‘)).values(‘name‘,‘sum_price‘)
Django之单表查询,多表查询(正向、反向查询),聚合查询
原文:https://www.cnblogs.com/xiongying4/p/11553178.html
