Anaconda:https://www.anaconda.com/download/
Python_whl:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
import cv2 # opencv读取的格式是BGR import matplotlib.pyplot as plt import numpy as np %matplotlib inline
# img读入的本质上就是数组 img = cv2.imread(‘cat.jpg‘)
#图像的显示,也可以创建多个窗口 cv2.imshow(‘image‘,img) # 等待时间,毫秒级,0表示任意键终止 cv2.waitKey(0) cv2.destroyAllWindows()
我们来将上述图像显示的代码封装成一个函数
def cv_show(name,img): cv2.imshow(name,img) cv2.waitKey(0) cv2.destroyAllWindows()
我们可以看看图像的各种基本信息
print(img.shape) # 图片形状(h, w, c) # 读取灰度图 -->通道数 c == 1 img=cv2.imread(‘cat.jpg‘,cv2.IMREAD_GRAYSCALE) img # 看看图片的类型 numpy.ndarray type(img) # 图片的size = h * w * c img.size # 图片中数据的类型 比如uint8 float32 img.dtype
保存图片
# (‘路径/保存图片名字‘, 要保存的图片) cv2.imwrite(‘mycat.png‘, img)
vc = cv2.VideoCapture(‘test.mp4‘)
# 检查是否打开正确 if vc.isOpened(): oepn, frame = vc.read() else: open = False
while open: ret, frame = vc.read() if frame is None: break if ret == True: gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) cv2.imshow(‘result‘, gray) if cv2.waitKey(100) & 0xFF == 27: break vc.release() cv2.destroyAllWindows()
import cv2#导入opencv包 video=cv2.VideoCapture(0)#打开摄像头 fourcc = cv2.VideoWriter_fourcc(*‘XVID‘)#视频存储的格式 fps = video.get(cv2.CAP_PROP_FPS)#帧率 #视频的宽高 size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))) out = cv2.VideoWriter(‘video.avi‘, fourcc, fps, size)#视频存储 while out.isOpened(): ret,img=video.read()#开始使用摄像头读数据,返回ret为true,img为读的图像 if ret is False:#ret为false则关闭 exit() cv2.namedWindow(‘video‘,cv2.WINDOW_AUTOSIZE)#创建一个名为video的窗口 cv2.imshow(‘video‘,img)#将捕捉到的图像在video窗口显示 out.write(img)#将捕捉到的图像存储 #按esc键退出程序 if cv2.waitKey(1) & 0xFF ==27: video.release()#关闭摄像头 break
img=cv2.imread(‘cat.jpg‘) cat=img[0:100,0:200] cv_show(‘cat‘,cat)
def color_space_demo(src): img = cv2.imread(src) # 转成灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv_show("gray", gray) # 转成HSV hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) cv_show(‘hsv‘, hsv) # hsv转成rgb(bgr) img = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) cv_show(‘hcv2img‘, img) # yuv...也可以转
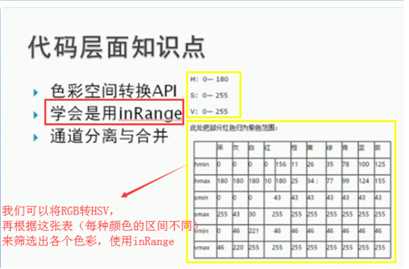
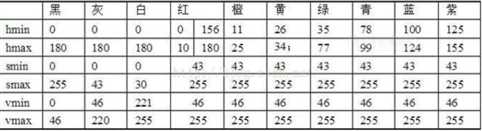
def extrace_object_demo(src): img = cv2.imread(src) # 通道数是3 # print(img.shape) img_binary = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 通道数是 1 # print(img_binary.shape) # 1.将RGB转换成HSV色彩空间 hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # print(hsv.shape) # 2.定义数组,说明你要提取(过滤)的颜色目标 # 三通道,所以是三个参数 # 红色 lower_hsv_r = np.array([156, 43, 46]) upper_hsv_r = np.array([180, 255, 255]) # 3.进行过滤,提取,得到二值图像 mask_red = cv2.inRange(hsv, lower_hsv_r, upper_hsv_r) # 通道数是 1 # print(mask_red.shape) # 4.展示成果 cv_show(‘original‘, img) cv_show(‘mask_red‘, mask_red) # 5.合并展示 res = np.hstack((img_binary, mask_red)) cv_show("hastck", res) return mask_red
# 提取 b,g,r=cv2.split(img) print(b.shape) # 合并 img = cv2.merge((b,g,r)) print(img.shape)
# 只保留R cur_img = img.copy() cur_img[:,:,0] = 0 cur_img[:,:,1] = 0 cv_show(‘R‘,cur_img)
top_size,bottom_size,left_size,right_size = (50,50,50,50) replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE) reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT) reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101) wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP) constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)
import matplotlib.pyplot as plt plt.subplot(231), plt.imshow(img, ‘gray‘), plt.title(‘ORIGINAL‘) plt.subplot(232), plt.imshow(replicate, ‘gray‘), plt.title(‘REPLICATE‘) plt.subplot(233), plt.imshow(reflect, ‘gray‘), plt.title(‘REFLECT‘) plt.subplot(234), plt.imshow(reflect101, ‘gray‘), plt.title(‘REFLECT_101‘) plt.subplot(235), plt.imshow(wrap, ‘gray‘), plt.title(‘WRAP‘) plt.subplot(236), plt.imshow(constant, ‘gray‘), plt.title(‘CONSTANT‘) plt.show()
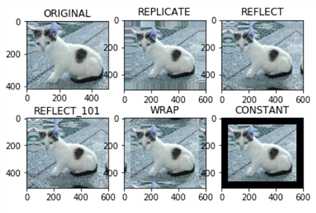
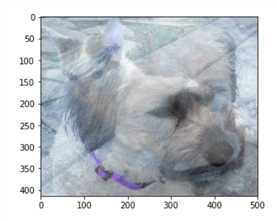
必须保证要融合的图片shape一致
img_cat=cv2.imread(‘cat.jpg‘) img_dog=cv2.imread(‘dog.jpg‘) img_cat + img_dog # ValueError: operands could not be broadcast together with shapes (414,500,3) (429,499,3) # 将狗狗的图片和猫猫的图片resize一样 img_dog = cv2.resize(img_dog, (500, 414)) # 选择融合的权重 res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0) # 展示结果 plt.imshow(res)
进一步演示resize的用法
# 将猫猫的图片放大 res = cv2.resize(img, (0, 0), fx=4, fy=4) plt.imshow(res)

res = cv2.resize(img, (0, 0), fx=1, fy=3)
plt.imshow(res)

原文:https://www.cnblogs.com/kongweisi/p/11555438.html