Spark Streaming使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个 RDD,以Spark作业的方式处理并生成其他的RDD。处理的结果可以以批处理的方式传给外部系统。高层次的架构如下图:
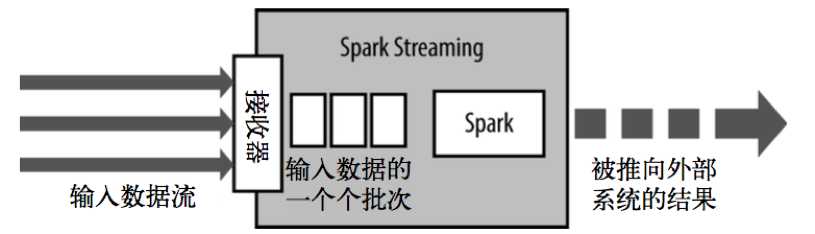
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个RDD序列,每个RDD代表数据流中一个时间片内的数据

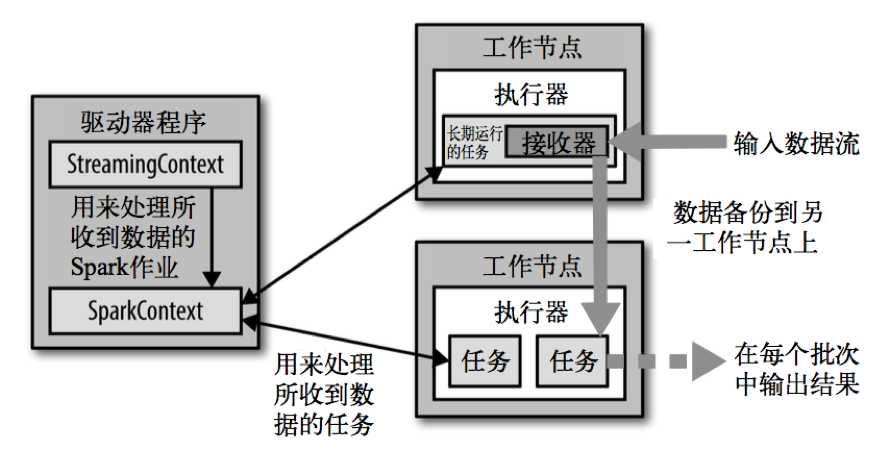
Spark Streaming在Spark的驱动器程序—工作节点的结构的执行过程如下图所示。Spark Streaming为每个输入源启动对应的接收器。接收器以任务的 形式运行在应用的执行器进程中,从输入源收集数据并保存为RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存RDD的方式一样。驱动器程序中的StreamingContext会周期性地运行Spark作业来处理这些数据,把数据与之前时间区间中的RDD进行整合
原文:https://www.cnblogs.com/zhanghuicheng/p/11235660.html