python解释器有很多种 最常见的就是Cpython解释器
GIL本质也是一把互斥锁:将并发变成串行牺牲效率保证数据的安全
用来阻止同一个进程下的多个线程的同时执行(同一个进程内多个线程无法实现并行但是可以实现并发
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
GIL的存在是因为CPython解释器的内存管理不是线程安全的
垃圾回收机制本身就是python解释器开启的一个进程必然除了主线程外还会有一个垃圾回收线程
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理
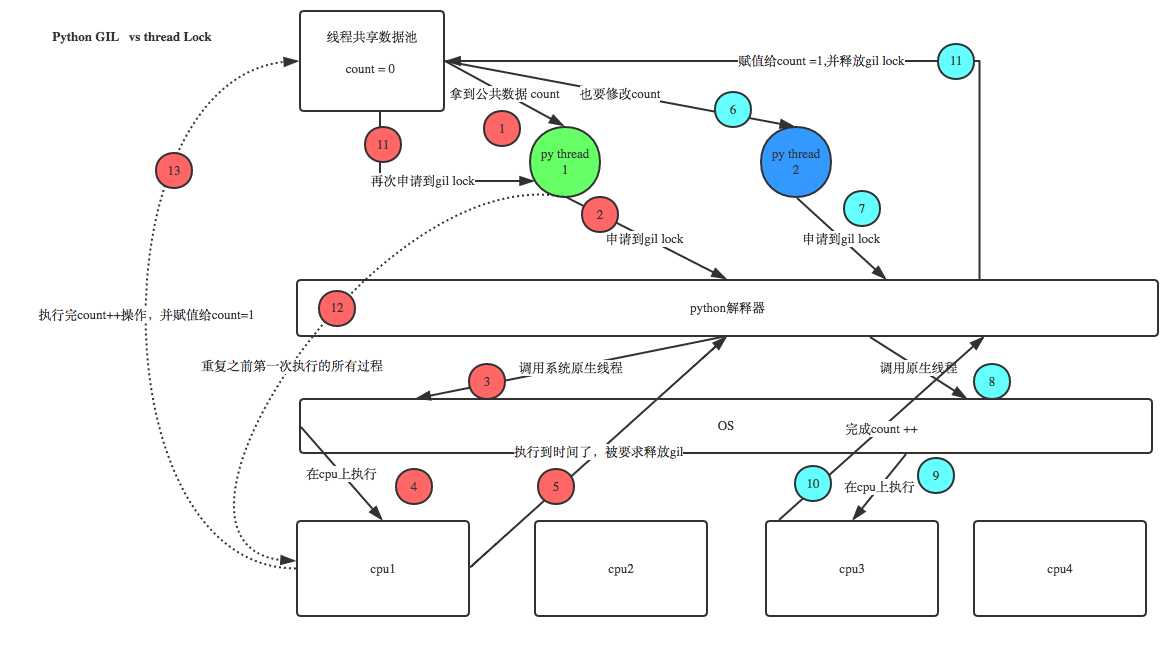
研究python的多线程是否有用需要分情况讨论
四个任务 计算密集型的 10s
单核情况下
开线程更省资源
多核情况下
开进程 10s
开线程 40s
四个任务 IO密集型的
单核情况下
开线程更节省资源
多核情况下
开线程更节省资源
# 计算密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) # 本机为6核
start=time.time()
for i in range(6):
# p=Process(target=work) #耗时 4.732933044433594
p=Thread(target=work) #耗时 22.83087730407715
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为6核
start=time.time()
for i in range(4000):
p=Process(target=work) #耗时9.001083612442017s多,大部分时间耗费在创建进程上
# p=Thread(target=work) #耗时2.051966667175293s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))python的多线程到底有没有用
需要看情况而定 并且肯定是有用的
多进程+多线程配合使用from threading import Thread
import time
n = 100
def task():
global n
tmp = n
# time.sleep(1)
n = tmp -1
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(n)过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
原文:https://www.cnblogs.com/suren-apan/p/11561965.html