主要参考连接为:参考链接,里面有详细的特征选择内容。
特征选择是特征工程里的一个重要问题,其目标是寻找最优特征子集。特征选择能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化模型,协助理解数据产生的过程。并且常能听到“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,由此可见其重要性。但是它几乎很少出现于机器学习书本里面的某一章。然而在机器学习方面的成功很大程度上在于如果使用特征工程。
之所以要考虑特征选择,是因为机器学习经常面临过拟合的问题。 过拟合的表现是模型参数太贴合训练集数据,模型在训练集上效果很好而在测试集上表现不好,也就是在高方差。简言之模型的泛化能力差。过拟合的原因是模型对于训练集数据来说太复杂,要解决过拟合问题,一般考虑如下方法:
其中第1条一般是很难做到的,一般主要采用第2和第4点
特征选择的一般过程:
但是, 当特征数量很大的时候, 这个搜索空间会很大,如何找最优特征还是需要一些经验结论。
根据特征选择的形式,可分为三大类:
发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选
基本想法是:分别对每个特征 x_i ,计算 x_i 相对于类别标签 y 的信息量 S(i) ,得到 n 个结果。然后将 n 个 S(i) 按照从大到小排序,输出前 k 个特征。显然,这样复杂度大大降低。那么关键的问题就是使用什么样的方法来度量 S(i) ,我们的目标是选取与 y 关联最密切的一些 特征x_i 。
sklearn使用到的内容主要为:
from sklearn.feature_selection import SelectKBest
score_func:callable,函数取两个数组X和y,返回一对数组(scores, pvalues)或一个分数的数组。默认函数为f_classif,计算F分数,默认函数只适用于分类函数。
k:int or "all", optional, default=10。所选择的topK个特征。“all”选项则绕过选择,用于参数搜索。
scores_ : array-like, shape=(n_features,),特征的得分
pvalues_ : array-like, shape=(n_features,),特征得分的p_value值,如果score_func只返回分数,则返回None。
fit(X,y),在(X,y)上运行记分函数并得到适当的特征。
fit_transform(X[, y]),拟合数据,然后转换数据。
get_params([deep]),获得此估计器的参数。
get_support([indices]),获取所选特征的掩码或整数索引。
inverse_transform(X),反向变换操作。
set_params(**params),设置估计器的参数。
transform(X),将X还原为所选特征
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,衡量的是变量之间的线性相关性,结果的取值区间为[-1,1] , -1 表示完全的负相关(这个变量下降,那个就会上升), +1 表示完全的正相关, 0 表示没有线性相关性。Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的pearsonr方法能够同时计算相关系数和p-value。
方法一:
pandas中,df.corr()可以直接计算相关系数
方法二:
import numpy as np from scipy.stats import pearsonr np.random.seed(0) size = 300 x = np.random.normal(0, 1, size) print("Lower noise:", pearsonr(x, x + np.random.normal(0, 1, size))) print("Higher noise:", pearsonr(x, x + np.random.normal(0, 10, size))) from sklearn.feature_selection import SelectKBest from sklearn import datasets iris=datasets.load_iris() model=SelectKBest(lambda X,Y:np.array(list(map(lambda x:pearsonr(x,Y),X.T))).T[0],k=2) #构建相关系数模型 model.fit_transform(iris.data, iris.target) #对模型将数据传入 print(‘相关系数:‘,model.scores_) #返回所有变量X与Y的相关系数值 print(‘P值:‘,model.pvalues_) #返回所有变量X的P值 print(‘所选变量的数值为:\n‘,model.fit_transform(iris.data, iris.target)) #打印传入数据的话会返回k=2所选择的两个变量的数据的值
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
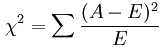
这个统计量的含义简而言之就是自变量对因变量的相关性。用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
import numpy as npfrom sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from sklearn import datasets iris=datasets.load_iris() model=SelectKBest(chi2,k=2) #构建相关系数模型 model.fit_transform(iris.data, iris.target) #对模型将数据传入 print(‘卡方系数:‘,model.scores_) #返回所有变量X与Y的相关系数值 print(‘P值:‘,model.pvalues_) #返回所有变量X的P值 print(‘所选变量的数值为:\n‘,model.fit_transform(iris.data, iris.target)) #打印传入数据的话会返回k=2所选择的两个变量的数据的值
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
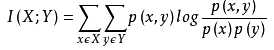
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
import numpy as np from sklearn.feature_selection import SelectKBest from minepy import MINE from sklearn import datasets iris=datasets.load_iris() def mic(x, y): m = MINE() m.compute_score(x, y) return (m.mic(), 0.5) model=SelectKBest(lambda X,Y:np.array(list(map(lambda x:mic(x,Y),X.T))).T[0],,k=2) #构建互信息数模型 model.fit_transform(iris.data, iris.target) #对模型将数据传入 print(‘互信息系数:‘,model.scores_) #返回所有变量X与Y的相关系数值 print(‘P值:‘,model.pvalues_) #返回所有变量X的P值 print(‘所选变量的数值为:\n‘,model.fit_transform(iris.data, iris.target)) #打印传入数据的话会返回k=2所选择的两个变量的数据的值
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
import numpy as np from sklearn.feature_selection import RFE,RFECV from sklearn.linear_model import LogisticRegression from sklearn import datasets iris=datasets.load_iris() # FECV() #利用交叉验证来选择,不过这里的交叉验证的数据集切割对象不再是 行数据(样本),而是列数据(特征),但是计算量会大,cv默认是3 model=RFE(estimator=LogisticRegression(), n_features_to_select=2) #构建逻辑回归的递归消除模型 model.fit_transform(iris.data, iris.target) #传入数据 print(model.classes_) #返回递归消除得到的变量
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
import numpy as np from sklearn.feature_selection import SelectFromModel from sklearn.linear_model import LogisticRegression from sklearn import datasets iris=datasets.load_iris() #带L1惩罚项的逻辑回归作为基模型的特征选择 model=SelectFromModel(LogisticRegression(penalty="l1", C=0.1)) model.fit_transform(iris.data, iris.target) #传入数据 print(model.fit_transform(iris.data, iris.target)) #返回模型选择的变量的数据内容
L2的特征选择请参考连接:https://www.cnblogs.com/jasonfreak/p/5448385.html
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
import numpy as np from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import GradientBoostingClassifier from sklearn import datasets iris=datasets.load_iris() #带L1惩罚项的逻辑回归作为基模型的特征选择 model=SelectFromModel(GradientBoostingClassifier()) model.fit_transform(iris.data, iris.target) #传入数据 print(model.fit_transform(iris.data, iris.target)) #返回模型选择的变量的数据内容
原文:https://www.cnblogs.com/dwithy/p/11570766.html