跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
redis使用跳跃表作为有序集合的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,redis就会使用跳跃表来作为有序集合键的底层实现。redis只在两个地方用到跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构。
跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息。
typedef struct zskiplistNode{
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
}zskiplistNode;
(1).层
跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候,程序根据幂次定律随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
(2).前进指针
(3).跨度
层的跨度用于记录两个节点之间的距离:
>两个节点之间的跨度越大,那么距离越远;
>指向null的所有前进指针的跨度是0。
跨度是用来计算排位(rank)的。
(4).后退指针
和可以一次跳过多个节点的前进指针不同,因为每个节点只有一个后退指针,所以每次只能后退到前一个节点。
(5)分值和成员
节点的分值是一个double类型的浮点数,跳跃表的所有节点都是按分值从小倒大排序。
节点的成员对象是一个指针,它指向一个字符串对象,而字符串对象则保存着一个SDS。
在同一张跳跃表中,各个节点保存的成员必须是唯一的,但是多个节点保存的分值却可以是相同的:分值相同的节点将按照成员对象在字典序中的大小进行排序,小的排前面。
typedef struct zskiplist{
//层
struct zskiplistNode *header,*tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
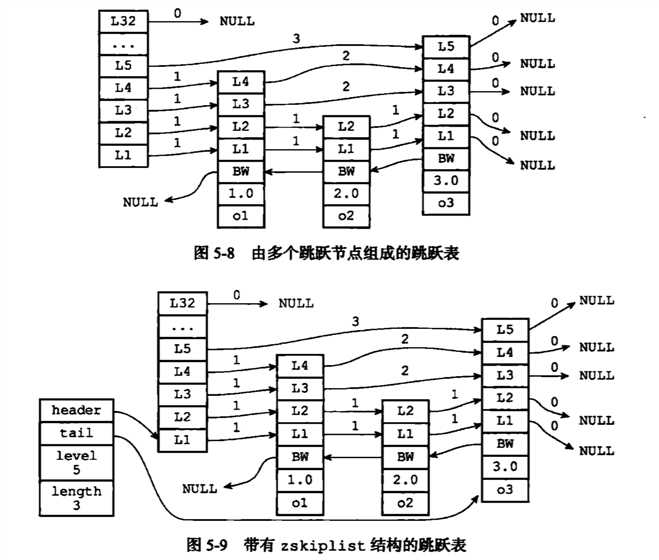
header和tail指针分别指向跳跃表的表头和表尾节点,通过这两个指针,程序定位表头节点和表尾节点的复杂度是O(1)。通过length属性记录节点的数量。
整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,redis就会使用整数集合作为集合键的底层实现。
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
contents数组是整数集合的底层实现:整数集合的每个元素都是contents的一个数据项,每个项在数组中按值的大小从小到大排列,并且数组中不包含任何重复项。
另外还有一点就是 假设一个新元素add到整数集合中,并且新元素的encoding类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级,然后才能讲新元素添加到整数集合中。一旦对数组进行了升级,无法降级。
原文:https://www.cnblogs.com/juin1058/p/11573633.html