BTREE *****
HASH
RTREE
FULLTEXT
Btree索引种类
b-tree(树,二分法)
b+tree(B+树如下图)
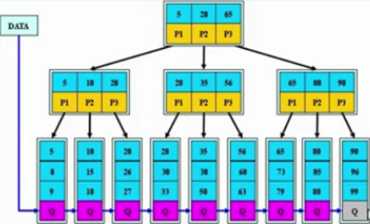
btree索引工作原理
#每个框大小16k
b*tree (b*树)
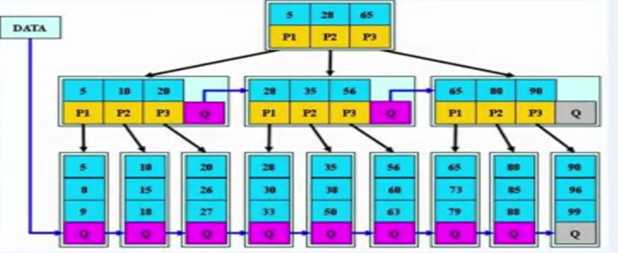
Mysql中Btree中类细分,及结构原理
#如果没有索引查询数据就会执行sql语句进行遍历整张表,数据会查询每一列的数据
辅助索引(二级索引)***
1、创建索引时;选择表中的某个索引键(key)
2、会将整个列提取出来
3、将排序后的值,均匀的分布的Btree索引的叶子节点中,进而生成枝节点,最终生成根节点,尽量控制索引树的高度,来减少索引树的遍历次数。
4、叶子节点上同时会存储原表数据行的指针,进而找到表中数据所在行的数据,次项动作叫做回表查询。(整行)。
5、如果有聚集索引,就会读取主键的值,然后拿着主键的值去读取聚集索引中的值。
#辅助索引
聚集索引(主键,建表中创建)
生成条件:
1、 会选择主键列作为聚集索引列(一般主键需要在键表时加入)
2、 如果没有主键,会选择唯一键生成。
结构原理:
1、 按照聚集索引列的值的顺序,安照顺序存储数据页,形成所谓叶子节点。(叶子节点是数据行,而辅助索引却是一个数据)
2、 枝节点和根节点依然只存储下层最小值及指针
覆盖索引(联合索引)
分析业务,将大部分的数据查询的列,联合起来Btree,可以很大部分的减少回表查询,从而减少随机I/O。
唯一索引(人为)
列中的数据必须唯一,一般在建表时建立
例子:
如果假设有一张表(表名xinxi表),其中内容有三列(id、name、age)
如果使用如下sql语句
Select * from xinxi where name=“张三”
1、 如果有辅助索引,并且索引在name这一列上就会直接读取数据,这里只查询了一个数据,如果查询了两列数据这个索引读取了索引中的数据后就会回表进行查询其他列进行遍历。
2、 如果表中有聚集索引(聚集索引一般和主键在一起,也可以把他理解成主键)和辅助索引,其中辅助索引在name列上,执行这条sql语句就会返回name=张三的值如果又查询了age这一列就会,通过辅助索引找到主键然后那这主键的值去找聚集索引(又因为聚集索引中的叶节点中存储的是整个数据行),然后返回age列的值。
索引其实也是表,也占用空间。
1、 数据行数多,高度页高;
解决方案:
1、 表分区,一般以800w行*(比较早期的解决方案)
2、 分布式(MyCat、TDDL、DBLE、DRDS)
索引列值很长的时候高多越高
1、 列值本来就很长
解决方案:
前缀索引
变长长度列,尽量使用varchar数据类型
怎么建立索引(PRI主键索引,mul普通索引、UNI唯一索引)#索引多了也不一定也是好事
辅助索引的管理
1、 单列普通辅助索引
2、 覆盖索引
3、 唯一索引
4、 前缀索引
创建普通索引
Alter table t1 add index index_name(name)#在name上创建一个名为index_name的索引
Alter table t1 drop index index_name; #删除索引
Show index from t1; #查看索引
Create index index_name on t1(name);
覆盖索引(联合索引)创建
Alter table add index index_co_po(name,id) #在id和name上创建索引
前缀索引创建
Alter table t1 add index index_name(name(10));#建立name的10个字符的索引
唯一索引创建
Alter table t1 add unique index index_name (name) #在name上创建唯一索引,这个唯一索引需要创建在的列上需要没有重复;
原文:https://www.cnblogs.com/DB-MYSQL/p/11575636.html