简介:
基于内存的并行计算,Facebook推出的分布式SQL交互式查询引擎 多个节点管道式执行
支持任意数据源 数据规模GB~PB 是一种Massively parallel processing(mpp)(大规模并行处理)模型
数据规模PB 不是把PB数据放到内存,只是在计算中拿出一部分放在内存、计算、抛出、再拿
多数据源、支持SQL、扩展性(可以自己扩展新的connector)、混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)、高性能、流水线(pipeline)
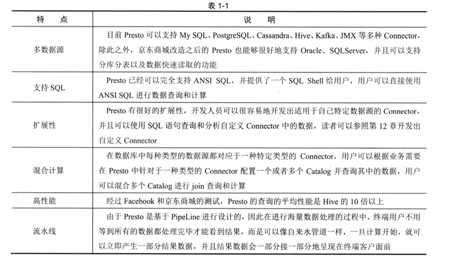
数据仓库 交互式略弱的查询引擎 只能访问HDFS文件 磁盘
但是presto是无法代替hive的
基于spark core mpp模式 详细课件spark sql一文
cube预计算
时序,数据放内存 索引 预计算
不适合多个大表的join操作,因为presto是基于内存的,太多数据内存放不下的
如果一个presto查询查过30分钟,那
就kill吧,说明不适合 也违背了presto的实时初衷
相当于MySQL的一个实例,
相当于MySQL的database
大内存、万兆网络、高计算能力
presto 查询引擎是一个Master-Slave的拓扑架构

中心的查询角色 接收查询请求、解析SQL 生成执行计划 任务调度 worker管理
coordinator进行是presto集群的master进程
执行任务的节点
presto以插件形式对数据存储层进行了抽象,它叫做连接器,不仅包含Hadoop相关组件的连接器还包括RDBMS连接器
具体访问哪个数据源是通过catalog 中的XXXX.properties文件中connector.name决定的
提取数据 负责实际执行查询计划
将coordinator和worker结合在一起服务;
worker节点启动后向discovery service服务注册
coordinator通过discovery service获取注册的worker节点
1、coordinator接到SQL后,通过SQL语法解析器把SQL语法解析变成一个抽象的语法树AST,只是进行语法解析如果有错误此环节暴露
2、语法符合SQL语法,会经过一个逻辑查询计划器组件,通过connector 查询metadata中schema 列名 列类型等,将之与抽象语法数对应起来,生成一个物理的语法树节点 如果有类型错误会在此步报错
3、如果通过,会得到一个逻辑的查询计划,将其分发到分布式的逻辑计划器里,进行分布式解析,最后转化为一个个task
4、在每个task里面,会将位置信息解析出来,交给执行的plan,由plan将task分给worker执行

基于内存的并行计算
流水式计算作业
本地化计算
Presto在选择Source任务计算节点的时候,对于每一个Split,按下面的策略选择一些minCandidates
优先选择与Split同一个Host的Worker节点
如果节点不够优先选择与Split同一个Rack的Worker节点
如果节点还不够随机选择其他Rack的节点
动态编译执行计划
GC控制
1、如果某个worker挂了,discovery service 会通知coordinator
2、对于query是没有容错的,一旦worker挂了,query就执行失败了,与其在这里容错不如直接执行
3、coordinator 和discovery service 的单点故障问题还没有解决
原文:https://www.cnblogs.com/www-qcdwx-com/p/11577850.html