联表查询
将多张表连在一起查询a,b表
select * from a,b;
会把两个表进行笛卡尔乘积,a表的每个记录,先和b表的所有记录挨个乘积,例如a表10条记录,b表10条记录
就会有100条记录的产生.a表在前,用a表记录去乘以b表记录,反之亦然.
下面两张表,一张员工表,一张部门表
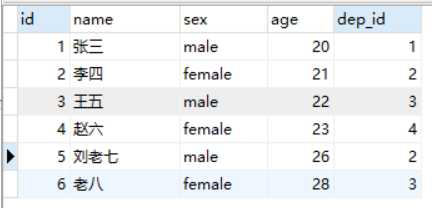
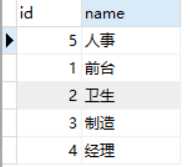
select * from employee,department;
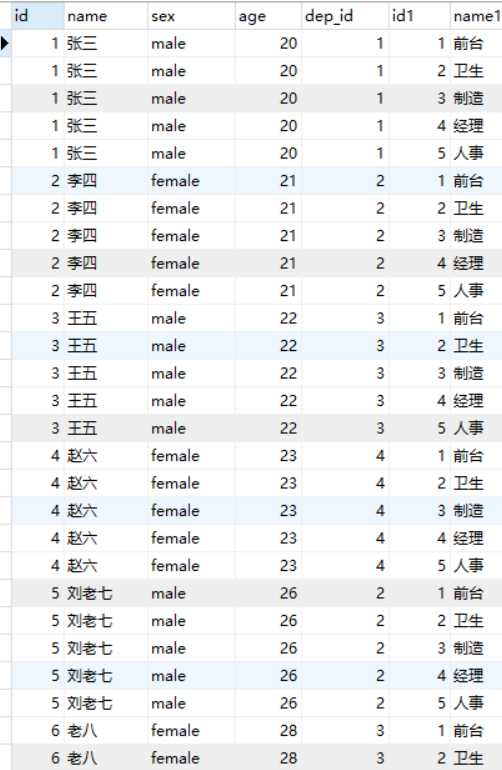
张三和每个部分进行了匹配,其他人也一样,图太长,老八的没有截取上
下面无论怎么连接都是在笛卡尔积结果的基础上进行了过滤,因此需要条件来进行过滤.
select * from employee inner join department on employee.dep_id=department.id;
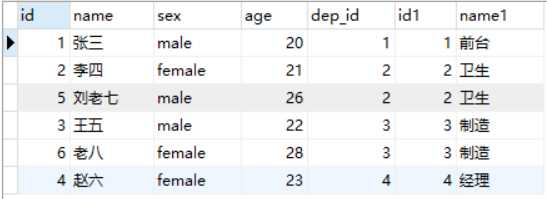
两张表匹配的项才会出现在最终的查询结果里,发现部门表里面的5没有,因为员工表里面没有5部门的员工.
select * from employee left join department on employee.dep_id=department.id;
左边表的所有记录都会显示
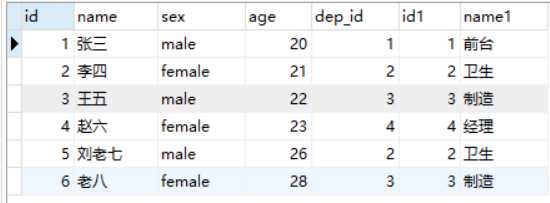
select * from employee right join department on employee.dep_id=department.id;
--使用别名,as可以省略
select * from employee e right join department d on e.dep_id=d.id;
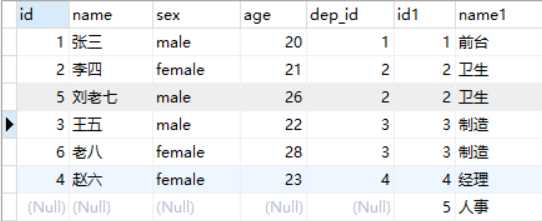
右外连接,右表的全部显示,坐标匹配不上的用null填充
select * from employee left join department on employee.dep_id=department.id union select * from employee right join department on employee.dep_id=department.id;
左右表都全量显示
先根据条件找出部门表中经理的id,然后在员工表中选出dep_id=id的数据
select id from department where namel="经理";
select name from emp where id =4;
合并
select name from emp where id =(select id from department where namel="经理")
子查询是先差一张表,根据查询结果,再去查另一张表
需求是查询经理的名字,
1不知道经理的id,先查出经理的id
2根据经理的id到员工表中查出dep_id = 经理的id的记录中的name叫什么
子查询就是单表查询,完全可以用连表查询,但是效率没有连表查询效率高,
连表查询是从一张大表里面查出想要的数据,子查询如果需求是两个部门,拿到两个部分的id,会分别的扫描全表拿到与部分id相同的记录,会多次扫描全表,先进行的子查询查出来多少个,后面的全表扫描就会进行多少次.
原文:https://www.cnblogs.com/gyxpy/p/11578806.html