计算机只能处理数字,如果要处理文本,就必须先把文本转换为计算机能识别的二进制数才能处理,将文本转换为二进制数的过程称为:编码;
ASCII (American Standard Code for Information Interchange): 美国信息交换标准代码,一种使用7个或8个二进制位进行编码的方案(标准ASCII码为7位,扩充为8位),最多可以给256个字符(包括英文大小写字母、数字、标点符号、控制字符及其他符号)
要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
全世界有上百种语言,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。
新问题的出现:Unicode编码统一采用4字节编码,不利于数据传输,因此,一种对Unicode编码进行压缩的UTF-8编码出现。
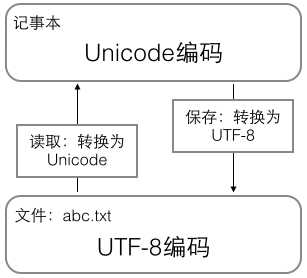
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8或其他编码。
字节是二进制数据的单位。一个字节通常8位长。但是,一些老型号计算机结构使用不同的长度。为了避免混乱,在大多数国际文献中,使用词代替byte。
在多数的计算机系统中,一个字节是一个8位长的数据单位,大多数的计算机用一个字节表示一个字符、数字或其他字符。一个字节也可以表示一系列二进制位。
字节通常简写为“B”,而位通常简写为小写“b”,计算机存储器的大小通常用字节来表示。
数据存储是以“字节”(Byte)为单位,数据传输大多是以“位”(bit,又名“比特”)为单位,一个位就代表一个0或1(即二进制),每8个位(bit,简写为b)组成一个字节(Byte,简写为B),是最小一级的信息单位。
换算:
1byte = 8bit
1KB(KiB) = 1024byte
1MB(MiB) = 1024KB
1GB(GiB) = 1024MB
1TB(TiB) = 1024GB
原文:https://www.cnblogs.com/jonnyleung/p/11579977.html