现在做爬虫的大部分都在用Python,其实java也可以,这里介绍一款轻量级国产爬虫框架 Webmagic
官方地址:http://webmagic.io/

个人对于爬虫的理解分为2种,第一种是爬取页面(静态数据),第二种是爬取接口(动态加载的数据)
对于静态的页面数据,关键获取到页面document结构。
对于接口的数据,关键是找到接口链接和对应参数。
Webmagic对着两种都有非常简洁,易于理解的处理方案。
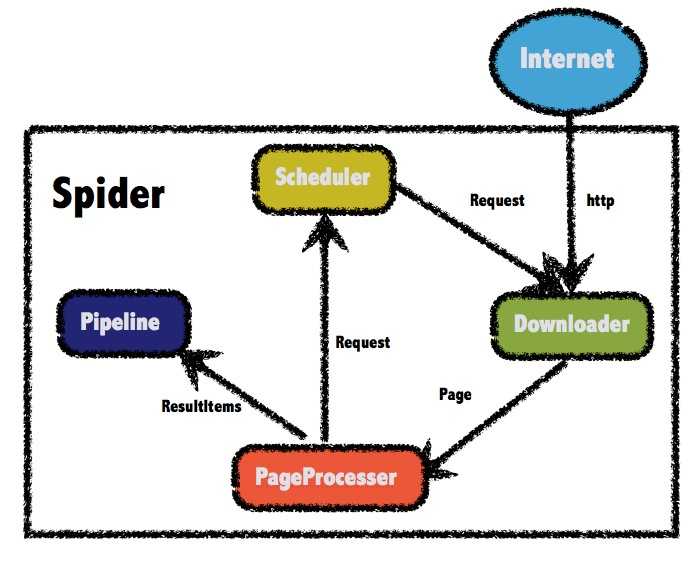
三个核心:PageProcessor,Pipeline,Spider
PageProcessor 实现爬取规则
Pipeline 实现数据持久化
Spider 启动爬虫,指定规则。
例如:
Spider.create(new MyProcessor())
.addPipeline(new MyPipeline())
.addUrl("http://www.xxxx.com").thread(3).run();
表示 启动一个爬虫,爬取规则为MyProcesser,爬取后的数据处理方式为MyPipeline,目标网站为http://www.xxxx.com,线程数量为3个,就是这么简洁。
另附一张官方架构图
原文:https://www.cnblogs.com/yhood/p/11597081.html