注:本人参考“裸睡的猪”公众号同名文章,学习使用。
使用Python分析出国庆哪些旅游景点:好玩、便宜、人还少的地方,不然拍照都要抢着拍!
爬取出行网站的旅游景点售票数据,反映出旅游景点的热度。这里选择爬取“去哪儿”网。
我们可以在哪去儿的门票页(http://piao.qunar.com/ticket/list.htm?keyword=)搜索:**国庆旅游景点**,就可以看到推荐的景点的一些信息,如:名称、地区、热度、销量、价格、等级、地理信息等等,信息应该说是比较全,良心!
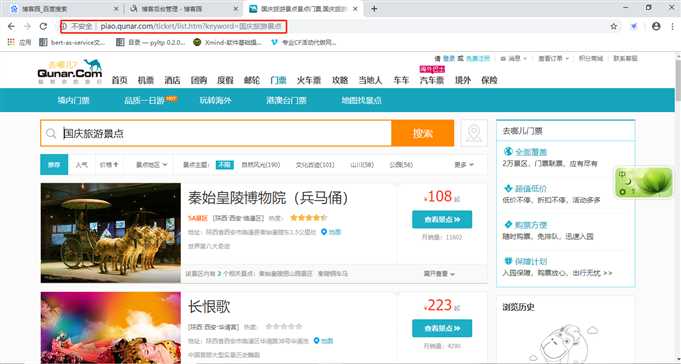
然后鼠标右键检查或者直接按下F12打开浏览器调试窗口,查找加载数据的url(翻页就可以看到)
结果发现返回的是json字串,真的是太方便了。
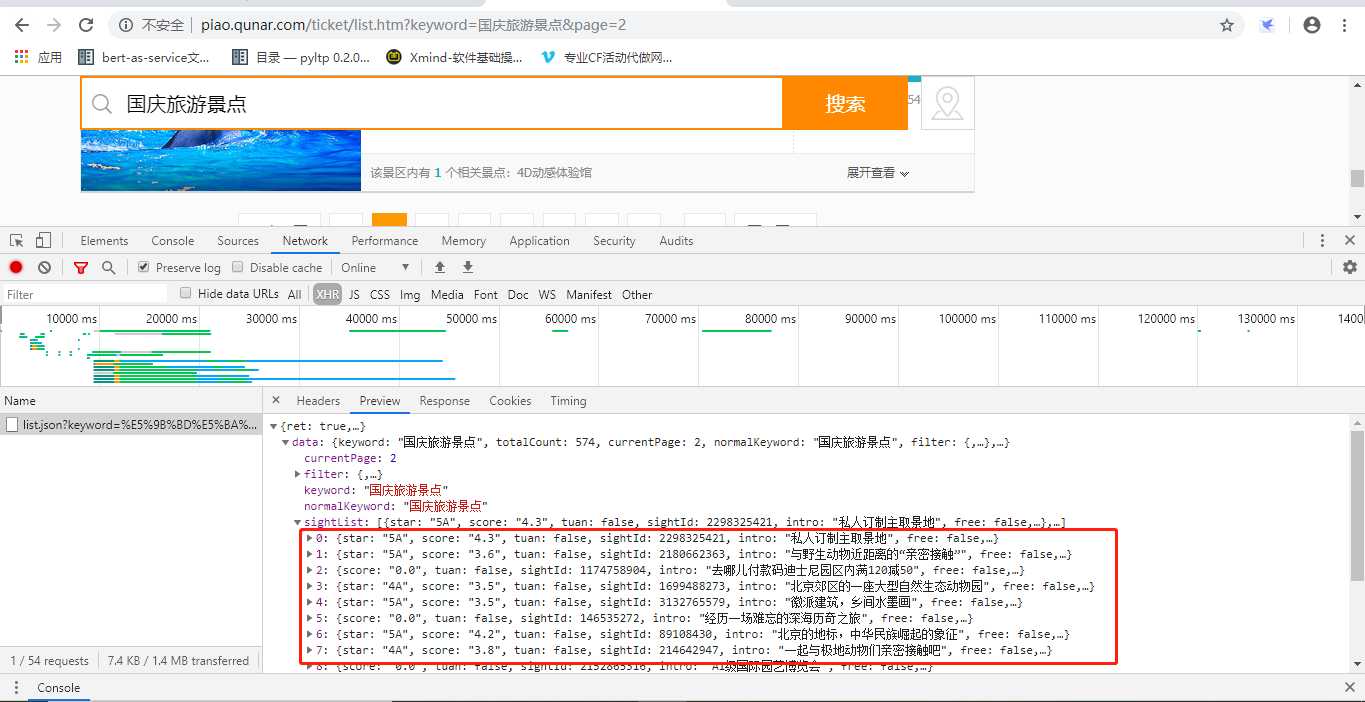
我们可以在Headers中获取到请求的接口URL。
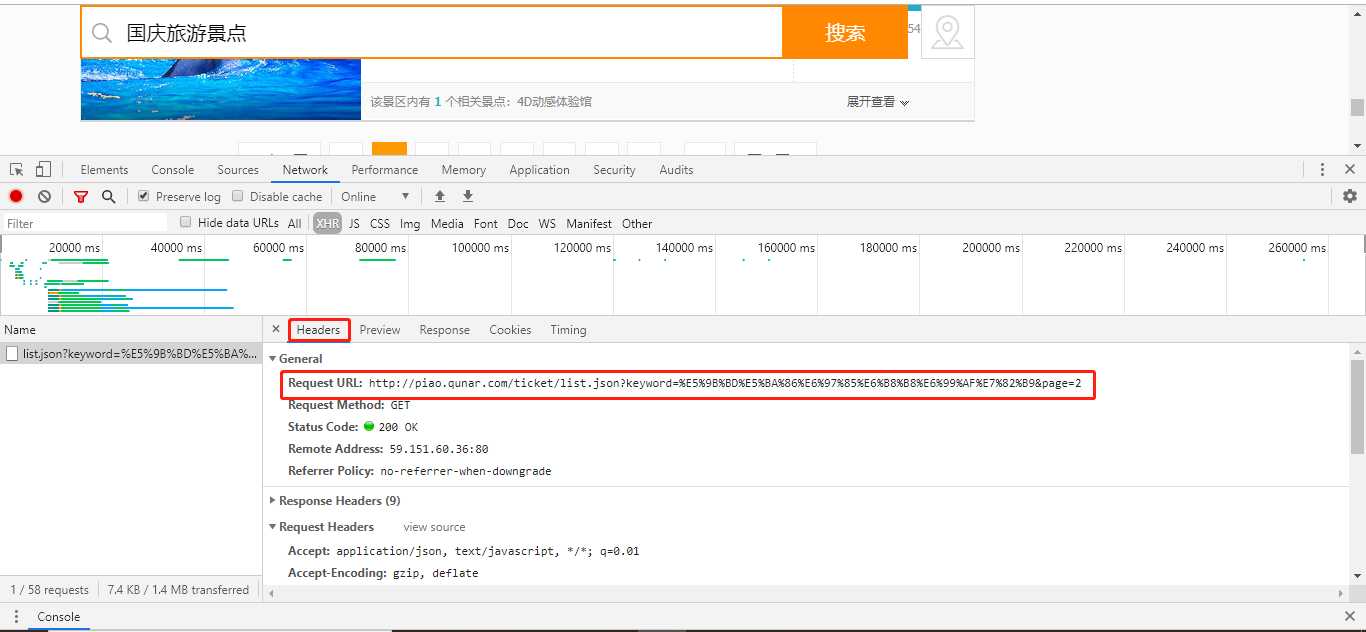
最后我们还是通过requests写一个get请求就可以了。
import requests def spider_qunaer(): url = ‘http://piao.qunar.com/ticket/list.json?keyword=%E5%9B%BD%E5%BA%86%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9&page=2‘ kv = { # 安全起见,这里将浏览器的请求头信息全部搬了过来。 ‘Accept‘: ‘application/json, text/javascript, */*; q=0.01‘, ‘Accept-Encoding‘: ‘gzip, deflate‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Connection‘: ‘keep-alive‘, ‘Cookie‘: ‘QN1=000030002eb41a2c64507881; QN300=organic; QN205=organic; QN277=organic; csrfToken=guhvJ2UJ1S4JkRAEVVNKXqbexa4jr5lt; QN57=15696544141780.5581713141626528; _i=ueHd8gCnQ4-Xw7_X4lIWdXKBeRXX; _vi=XP2sC7e0MzBdRRW7FdRZOsOPXwsELGnAOhxlvjUk0axSb0VgxK5ed_tCVXy7Do_Hs18hUDMbEp0KJlk3szcH4x4NMsCp8FOa-NNtb_5lNw863q5BUECid5aLk0CTpYlYxknlalntWSAeee7jg11ixyFGiBhcBJQEVtrTCt757OCe; QN269=8BC04422E1BE11E9BCEAFA163E89CFE1; Hm_lvt_15577700f8ecddb1a927813c81166ade=1569654418; fid=10739e17-bb75-4c11-ba8d-2ab6b55fa9e8; QN63=%E5%9B%BD%E5%BA%86%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9%7C%E5%9B%BD%E5%BA%86%E5%8E%BB%E5%93%AA%E5%84%BF; JSESSIONID=A946FF2222DB69A818A7AE88D0919C70; QN267=07847690024d33702e; QN58=1569654414177%7C1569654475972%7C4; Hm_lpvt_15577700f8ecddb1a927813c81166ade=1569654476; QN271=6211ab7c-59f8-442d-9234-ef456f77452b‘, ‘Host‘: ‘piao.qunar.com‘, ‘Referer‘: ‘http://piao.qunar.com/ticket/list.htm?keyword=%E5%9B%BD%E5%BA%86%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9&page=2‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36‘, ‘X-Requested-With‘: ‘XMLHttpRequest‘} try: result = requests.get(url, headers = kv) result.raise_for_status() print(result.text) except Exception as e: print(e) if __name__ == ‘__main__‘: spider_qunaer()
既然数据拿到了,那就看看数据结构,然后提取自己想要的属性吧。
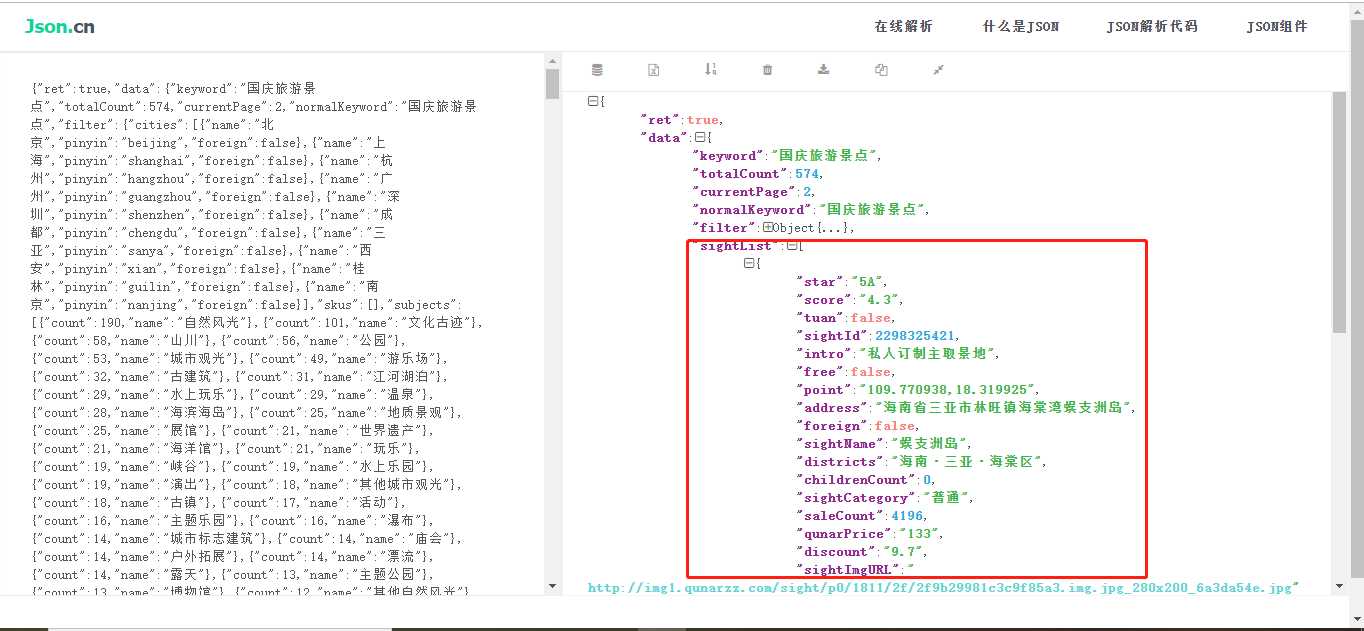
这个json结构也是比较简单,我们可以清晰的看到我们所需要的数据在‘sightList’里。
这里提取了:id、名称、星级、评分、门票价格、销量、地区、坐标、简介这些信息,基本有效信息都保存起来!
def get_place_info(response_json): ‘‘‘ 解析json,获取想要的字段 :param response_json: :return: ‘‘‘ place_list = [] # 定义一个列表,等会将景点等信息都存到列表中 sight_list = response_json[‘data‘][‘sightList‘] for sight in sight_list: goods = { ‘id‘: sight[‘sightId‘], # 景点id ‘name‘: sight[‘sightName‘], # 景点名称 ‘star‘: sight.get(‘star‘, None), # 星级,这里使用get获取,防止触发keyerror ‘score‘: sight.get(‘score‘, 0), # 评分 ‘price‘: sight.get(‘qunarPrice‘, 0), # 价格 ‘sale‘: sight.get(‘saleCount‘, 0), # 销量 ‘districts‘: sight.get(‘districts‘, None), # 省,市,区 ‘point‘: sight.get(‘point‘, None), # 坐标 ‘intro‘: sight.get(‘intro‘, None), # 简介 ‘free‘: sight.get(‘free‘, True), # 是否免费 ‘address‘: sight.get(‘address‘, None) # 具体地址 } place_list.append(goods) return place_list
需要的数据提取出来之后,我们就可以将他们保存起来。这里我们使用pandas库保存excel文件。
没有安装pandas库的同学安装一下。pip install pandas
def save_excel(place_list): ‘‘‘ 将json数据存储为excel文件 :param place_list: :return: ‘‘‘ # pandas没有对excel追加模式,只能先读后写 if os.path.exists(PLACE_EXCEL_PATH): df = pd.read_excel(PLACE_EXCEL_PATH) df = df.append(place_list) else: df = pd.DataFrame(place_list) writer = pd.ExcelWriter(PLACE_EXCEL_PATH) df.to_excel(excel_writer=writer, columns=[‘id‘, ‘name‘, ‘star‘, ‘score‘, ‘price‘, ‘sale‘, ‘districts‘, ‘point‘, ‘intro‘, ‘free‘, ‘address‘], encoding=‘utf-8‘,sheet_name=‘去哪儿热门景点‘) writer.save() writer.close()
这里单页数据的处理就完成了,爬取、解析、保存三步走。
批量爬取也很简单,细心的同学应该已经发现了,我们刚才爬取单页数据是第二页的数据。
我们可以看看第一页的url是什么?
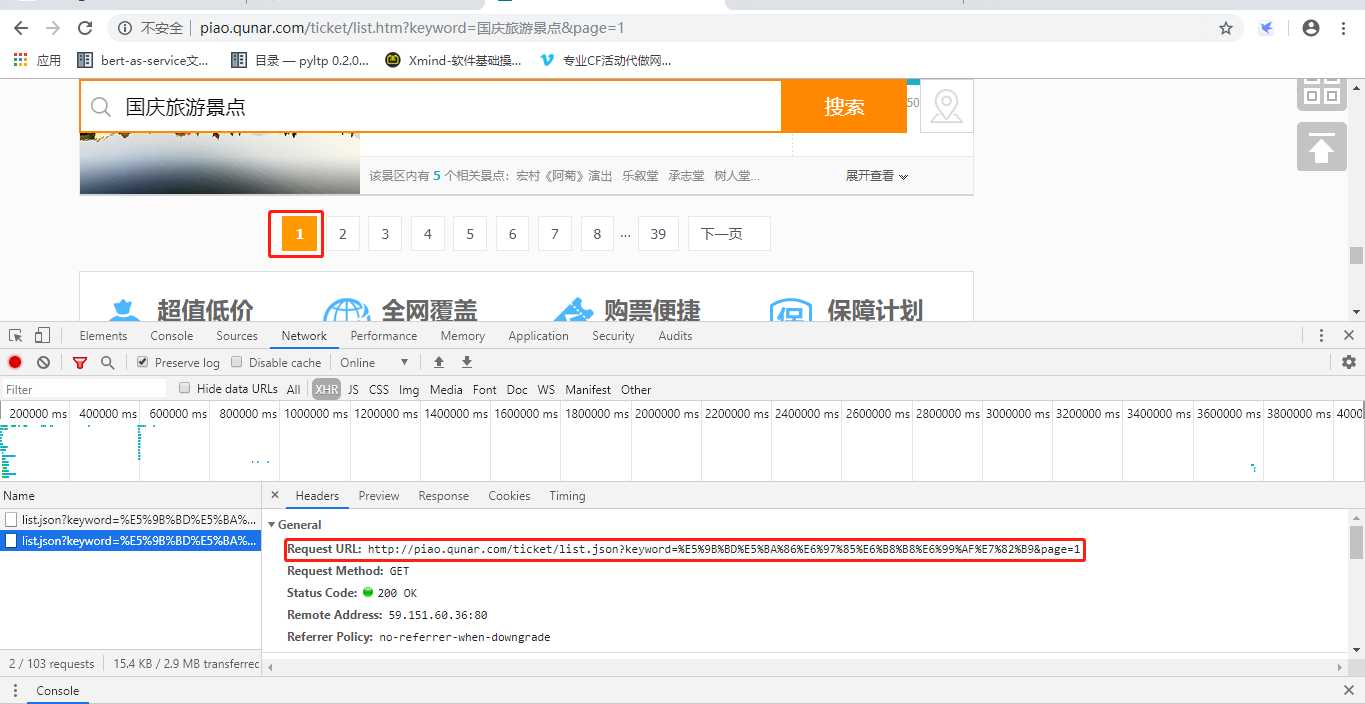
不难发现,前面你的内容都一样,page的参数不一样。这样我们在外层写一个for循环,把页数传入就可以实现批量爬取。
def path_spider_place(keyword): ‘‘‘ 批量爬取去哪儿景点 :param keyword: 搜索关键字 :return: ‘‘‘ # 写入数据前先清空之前数据 if os.path.exists(PLACE_EXCEL_PATH): os.remove(PLACE_EXCEL_PATH) for i in range(1, 40): # 发现有39页,或者可以判断爬取数据返回值 print(f‘正在爬取{keyword} 第{i}页‘) spider_qunaer(keyword, i) # 设置一个时间间隔 time.sleep(random.randint(2, 5)) print(‘爬取完成‘)

import os import random import time import requests import pandas as pd PLACE_EXCEL_PATH = ‘qunaer.xlsx‘ def spider_qunaer(keyword, i): url = f‘http://piao.qunar.com/ticket/list.json?keyword={keyword}&page={i}‘ kv = { # 安全起见,这里将浏览器的请求头信息全部搬了过来。 ‘Accept‘: ‘application/json, text/javascript, */*; q=0.01‘, ‘Accept-Encoding‘: ‘gzip, deflate‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Connection‘: ‘keep-alive‘, ‘Cookie‘: ‘QN1=000030002eb41a2c64507881; QN300=organic; QN205=organic; QN277=organic; csrfToken=guhvJ2UJ1S4JkRAEVVNKXqbexa4jr5lt; QN57=15696544141780.5581713141626528; _i=ueHd8gCnQ4-Xw7_X4lIWdXKBeRXX; _vi=XP2sC7e0MzBdRRW7FdRZOsOPXwsELGnAOhxlvjUk0axSb0VgxK5ed_tCVXy7Do_Hs18hUDMbEp0KJlk3szcH4x4NMsCp8FOa-NNtb_5lNw863q5BUECid5aLk0CTpYlYxknlalntWSAeee7jg11ixyFGiBhcBJQEVtrTCt757OCe; QN269=8BC04422E1BE11E9BCEAFA163E89CFE1; Hm_lvt_15577700f8ecddb1a927813c81166ade=1569654418; fid=10739e17-bb75-4c11-ba8d-2ab6b55fa9e8; QN63=%E5%9B%BD%E5%BA%86%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9%7C%E5%9B%BD%E5%BA%86%E5%8E%BB%E5%93%AA%E5%84%BF; JSESSIONID=A946FF2222DB69A818A7AE88D0919C70; QN267=07847690024d33702e; QN58=1569654414177%7C1569654475972%7C4; Hm_lpvt_15577700f8ecddb1a927813c81166ade=1569654476; QN271=6211ab7c-59f8-442d-9234-ef456f77452b‘, ‘Host‘: ‘piao.qunar.com‘, ‘Referer‘: ‘http://piao.qunar.com/ticket/list.htm?keyword=%E5%9B%BD%E5%BA%86%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9&page=2‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36‘, ‘X-Requested-With‘: ‘XMLHttpRequest‘} try: result = requests.get(url, headers=kv) result.raise_for_status() place_list = get_place_info(result.json()) save_excel(place_list) except Exception as e: print(e) def get_place_info(response_json): ‘‘‘ 解析json,获取想要的字段 :param response_json: :return: ‘‘‘ place_list = [] # 定义一个列表,等会将景点等信息都存到列表中 sight_list = response_json[‘data‘][‘sightList‘] for sight in sight_list: goods = { ‘id‘: sight[‘sightId‘], # 景点id ‘name‘: sight[‘sightName‘], # 景点名称 ‘star‘: sight.get(‘star‘, None), # 星级,这里使用get获取,防止触发keyerror ‘score‘: sight.get(‘score‘, 0), # 评分 ‘price‘: sight.get(‘qunarPrice‘, 0), # 价格 ‘sale‘: sight.get(‘saleCount‘, 0), # 销量 ‘districts‘: sight.get(‘districts‘, None), # 省,市,区 ‘point‘: sight.get(‘point‘, None), # 坐标 ‘intro‘: sight.get(‘intro‘, None), # 简介 ‘free‘: sight.get(‘free‘, True), # 是否免费 ‘address‘: sight.get(‘address‘, None) # 具体地址 } place_list.append(goods) return place_list def save_excel(place_list): ‘‘‘ 将json数据存储为excel文件 :param place_list: :return: ‘‘‘ # pandas没有对excel追加模式,只能先读后写 if os.path.exists(PLACE_EXCEL_PATH): df = pd.read_excel(PLACE_EXCEL_PATH) df = df.append(place_list) else: df = pd.DataFrame(place_list) writer = pd.ExcelWriter(PLACE_EXCEL_PATH) df.to_excel(excel_writer=writer, columns=[‘id‘, ‘name‘, ‘star‘, ‘score‘, ‘price‘, ‘sale‘, ‘districts‘, ‘point‘, ‘intro‘, ‘free‘, ‘address‘], encoding=‘utf-8‘,sheet_name=‘去哪儿热门景点‘) writer.save() writer.close() def path_spider_place(keyword): ‘‘‘ 批量爬取去哪儿景点 :param keyword: 搜索关键字 :return: ‘‘‘ # 写入数据前先清空之前数据 if os.path.exists(PLACE_EXCEL_PATH): os.remove(PLACE_EXCEL_PATH) for i in range(1, 40): # 发现有39页,或者可以判断爬取数据返回值 print(f‘正在爬取{keyword} 第{i}页‘) spider_qunaer(keyword, i) # 设置一个时间间隔 time.sleep(random.randint(2, 5)) print(‘爬取完成‘) if __name__ == ‘__main__‘: path_spider_place(‘国庆旅游景点‘)
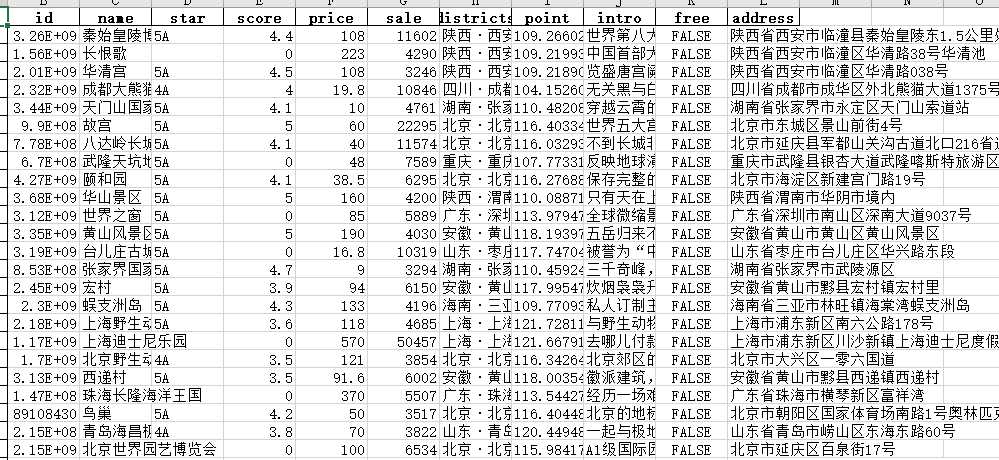
数据都下载完毕后,就要思考如何去利用分析这些数据了
import pandas as pd
import re
from matplotlib import pyplot as plt
from matplotlib import font_manager
import numpy as np
# 去哪儿热门景点excel文件保存路径
PLACE_EXCEL_PATH = ‘qunaer.xlsx‘
# 读取数据
DF = pd.read_excel(PLACE_EXCEL_PATH)
font = font_manager.FontProperties(fname=r"C:\Windows\Fonts\msyhbd.ttc") def analysis_sale(): ‘‘‘ 分析门票销量 :return: ‘‘‘ # 引入全局变量 global DF df = DF.copy() df = df.sort_values(by=‘sale‘, ascending=False) name = df[‘name‘][0:20] sale = df[‘sale‘][0:20] plt.figure(figsize=(20, 8), dpi=80) plt.barh(range(len(sale)), sale, height=0.3) plt.yticks(range(len(name)), name, fontproperties=font) plt.title(‘去哪儿“十一”门票销量前20‘,fontproperties=font) plt.ylabel("景点名称", fontproperties=font) plt.xlabel("销量", fontproperties=font) plt.grid(alpha=0.3) plt.savefig(‘jingqu.jpg‘) plt.show() if __name__ == ‘__main__‘: analysis_sale()
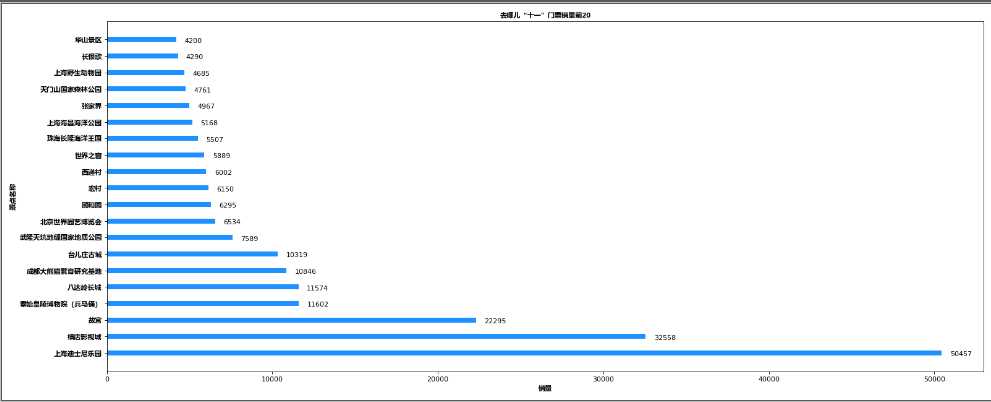
import pandas as pd import re from matplotlib import pyplot as plt from matplotlib import font_manager import numpy as np from pyecharts import options as opts from pyecharts.charts import Bar # 去哪儿热门景点excel文件保存路径 PLACE_EXCEL_PATH = ‘qunaer.xlsx‘ # 读取数据 DF = pd.read_excel(PLACE_EXCEL_PATH, index_col=0) # 百度热力图模板 HOT_MAP_TEMPLATE_PATH = ‘hot_map_template.html‘ # 生成的国庆旅游景点热力图 PLACE_HOT_MAP_PATH = ‘place_hot_map.html‘ # 字体 font = font_manager.FontProperties(fname=r"C:\Windows\Fonts\msyhbd.ttc") def analysis_sale(): ‘‘‘ 分析门票销量 :return: ‘‘‘ # 引入全局变量 global DF df = DF.copy() place_sale = df.pivot_table(values=‘sale‘, index=‘name‘).reset_index().sort_values(by=‘sale‘, ascending=False)[0:20] print(place_sale) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(20, 8)) # 画条形图 barh = plt.barh(place_sale[‘name‘].values, place_sale[‘sale‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_sale[‘sale‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘销量‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点门票销量TOP20‘, font1) f.savefig(‘1.png‘, bbox_inches=‘tight‘) f.show()
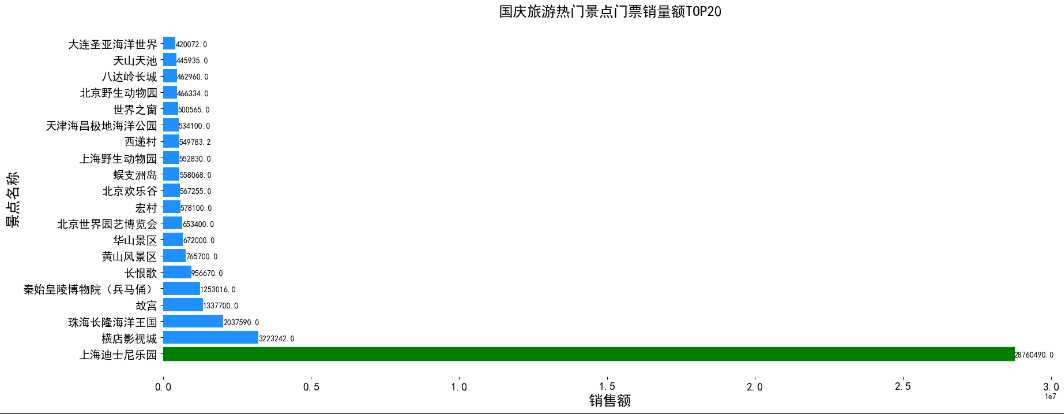
销售额=单价*销量,我们可以将每行的price和sale相乘算出销售额
def analysis_amout(): """ 分析销售额 :return: """ # 引入全局数据 global DF df = DF.copy() amount_list = [] for index, row in df.iterrows(): try: # 销售额 amount = row[‘price‘] * row[‘sale‘] except: amount = 0 amount_list.append(amount) df[‘amount‘] = amount_list # 生成一个名称和销量的透视表 place_amount = df.pivot_table(index=‘name‘, values=‘amount‘).reset_index().sort_values(‘amount‘, ascending=False)[0:20] print(place_amount) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(20, 8)) # 画条形图 barh = plt.barh(place_amount[‘name‘].values, place_amount[‘amount‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_amount[‘amount‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘销售额‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点门票销量额TOP20‘, font1) f.savefig(‘2.png‘, bbox_inches=‘tight‘) f.show()
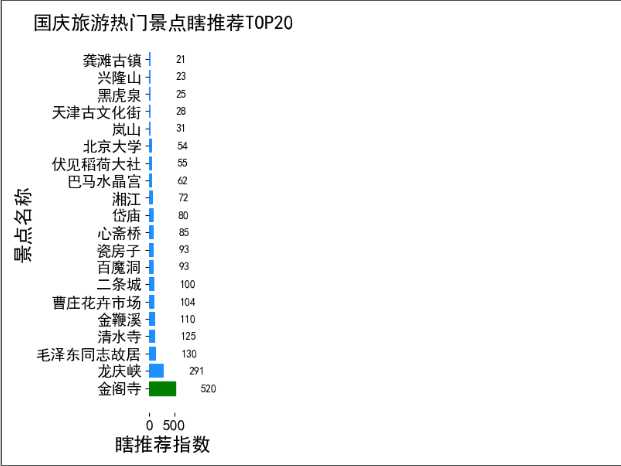
应该推荐怎样的景点呢?高评分、销量少、价格便宜。
推荐系数和评分成正比,和销量、价格成反比,所以猪哥设计了一个最简单的算法:
瞎推荐系数=评分/(销量价格) * 1000
def analysis_recommend(): """ 瞎推荐排行榜: 高评分、销量低、价格便宜 :return: """ global DF df = DF.copy() recommend_list = [] for index, row in df.iterrows(): try: # 瞎推荐系数算法 recommend = int((row[‘score‘] * 1000) / (row[‘price‘] * row[‘sale‘])) except ZeroDivisionError: recommend = 0 recommend_list.append(recommend) df[‘recommend‘] = recommend_list place_amount = df.pivot_table(index=‘name‘, values=‘recommend‘).reset_index().sort_values(‘recommend‘, ascending=False)[0:20] print(place_amount) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(8,6)) # 画条形图 barh = plt.barh(place_amount[‘name‘].values, place_amount[‘recommend‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_amount[‘recommend‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘瞎推荐指数‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点瞎推荐TOP20‘, font1) f.savefig(‘3.png‘, bbox_inches=‘tight‘) f.show()
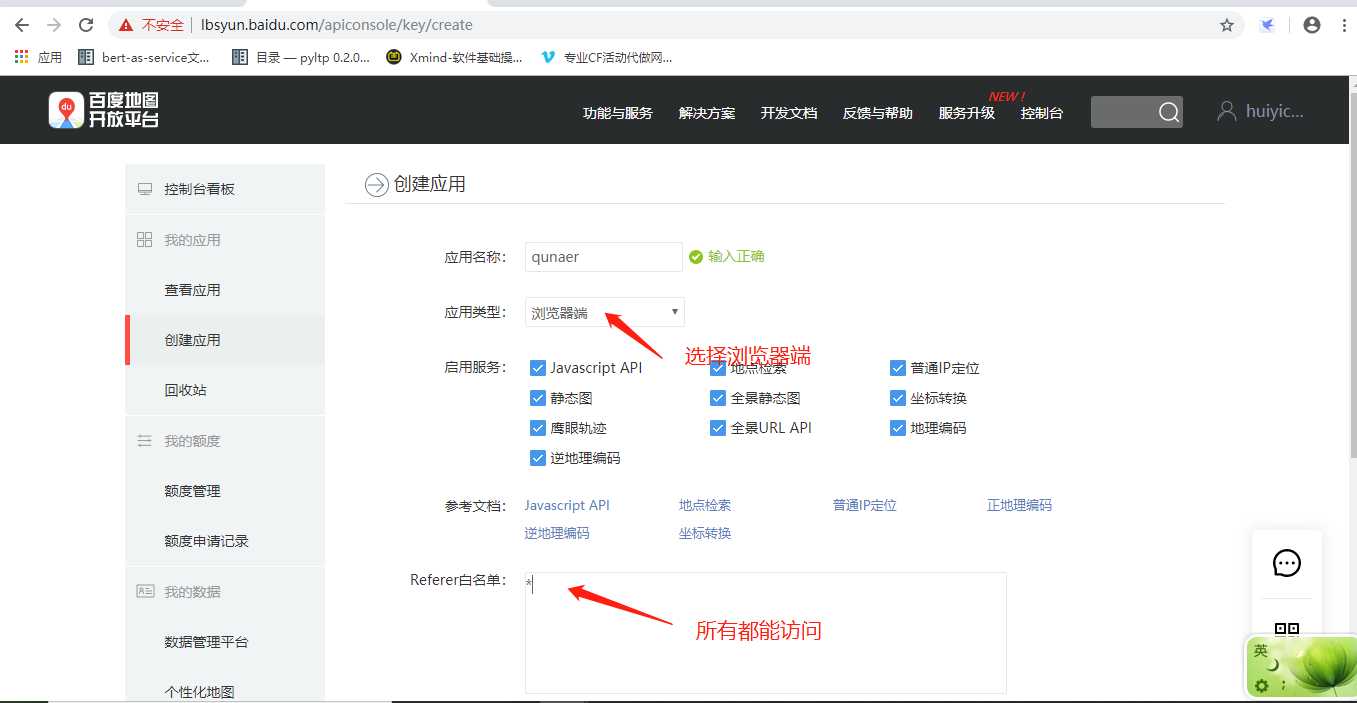
用百度地图开放api(免费)做一个热力图,你首先要做的就是申请一个百度地图开放平台的应用,操作很简单,如何申请可以 直接百度。
需要注意的是:在申请应用的时候类型一定要选浏览器
可以下载一个百度热力图的demo的html,在html中把ak码换成自己的。
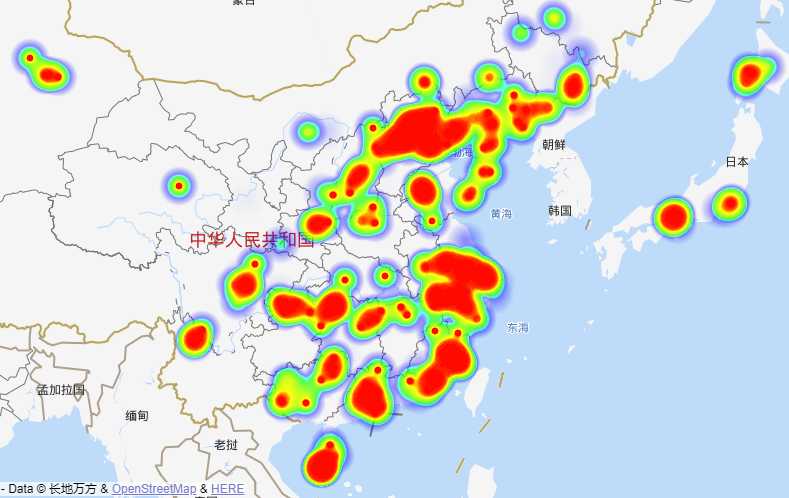
def analysis_point_sale(): """ 生成热力图,使用百度地图api :return: """ # 引入全局数据 global DF df = DF.copy() point_sale_list = [] for index, row in df.iterrows(): # 构建坐标数据 lng, lat = row[‘point‘].split(‘,‘) count = row[‘sale‘] point_sale = {‘lng‘: float(lng), ‘lat‘: float(lat), ‘count‘: count} point_sale_list.append(point_sale) print(point_sale_list) data = f‘var points ={str(point_sale_list)};‘ # 替换模板中的坐标数据 with open(HOT_MAP_TEMPLATE_PATH, ‘r‘, encoding="utf-8") as f1, open(PLACE_HOT_MAP_PATH, ‘w‘, encoding="utf-8") as f2: s = f1.read() # 替换数据 s2 = s.replace(‘%data%‘, data) f2.write(s2) f1.close() f2.close()
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta name="viewport" content="initial-scale=1.0, user-scalable=no" /> <script type="text/javascript" src="//api.map.baidu.com/api?v=2.0&ak=你申请的ak码"></script> <script type="text/javascript" src="//api.map.baidu.com/library/Heatmap/2.0/src/Heatmap_min.js"></script> <title>热力图功能示例</title> <style type="text/css"> ul,li{list-style: none;margin:0;padding:0;float:left;} html{height:100%} body{height:100%;margin:0px;padding:0px;font-family:"微软雅黑";} #container{height:500px;width:100%;} #r-result{width:100%;} </style> </head> <body> <div id="container"></div> <div id="r-result"> <input type="button" onclick="openHeatmap();" value="显示热力图"/><input type="button" onclick="closeHeatmap();" value="关闭热力图"/> </div> </body> </html> <script type="text/javascript"> var map = new BMap.Map("container"); // 创建地图实例 var point = new BMap.Point(116.418261, 39.921984); map.centerAndZoom(point, 15); // 初始化地图,设置中心点坐标和地图级别 map.enableScrollWheelZoom(); // 允许滚轮缩放 // 将下面参数替换为你的坐标数据 %data% // 下面是百度默认给的模板数据,可以打开看看效果 // var points =[ // {"lng":116.418261,"lat":39.921984,"count":50000}, // {"lng":116.423332,"lat":39.916532,"count":51000}, // {"lng":116.419787,"lat":39.930658,"count":15000}, // {"lng":116.418455,"lat":39.920921,"count":4000}, // {"lng":116.418843,"lat":39.915516,"count":100000}, // {"lng":116.42546,"lat":39.918503,"count":6}, // {"lng":116.423289,"lat":39.919989,"count":18}, // {"lng":116.418162,"lat":39.915051,"count":80}, // {"lng":116.422039,"lat":39.91782,"count":11}, // {"lng":116.41387,"lat":39.917253,"count":7}, // {"lng":116.41773,"lat":39.919426,"count":42}, // {"lng":116.421107,"lat":39.916445,"count":4}, // {"lng":116.417521,"lat":39.917943,"count":27}, // {"lng":116.419812,"lat":39.920836,"count":23}, // {"lng":116.420682,"lat":39.91463,"count":60}, // {"lng":116.415424,"lat":39.924675,"count":8}, // {"lng":116.419242,"lat":39.914509,"count":15}, // {"lng":116.422766,"lat":39.921408,"count":25}, // {"lng":116.421674,"lat":39.924396,"count":21}, // {"lng":116.427268,"lat":39.92267,"count":1}, // {"lng":116.417721,"lat":39.920034,"count":51}, // {"lng":116.412456,"lat":39.92667,"count":7}, // {"lng":116.420432,"lat":39.919114,"count":11}, // {"lng":116.425013,"lat":39.921611,"count":35}, // {"lng":116.418733,"lat":39.931037,"count":22}, // {"lng":116.419336,"lat":39.931134,"count":4}, // {"lng":116.413557,"lat":39.923254,"count":5}, // {"lng":116.418367,"lat":39.92943,"count":3}, // {"lng":116.424312,"lat":39.919621,"count":100}, // {"lng":116.423874,"lat":39.919447,"count":87}, // {"lng":116.424225,"lat":39.923091,"count":32}, // {"lng":116.417801,"lat":39.921854,"count":44}, // {"lng":116.417129,"lat":39.928227,"count":21}, // {"lng":116.426426,"lat":39.922286,"count":80}, // {"lng":116.421597,"lat":39.91948,"count":32}, // {"lng":116.423895,"lat":39.920787,"count":26}, // {"lng":116.423563,"lat":39.921197,"count":17}, // {"lng":116.417982,"lat":39.922547,"count":17}, // {"lng":116.426126,"lat":39.921938,"count":25}, // {"lng":116.42326,"lat":39.915782,"count":100}, // {"lng":116.419239,"lat":39.916759,"count":39}, // {"lng":116.417185,"lat":39.929123,"count":11}, // {"lng":116.417237,"lat":39.927518,"count":9}, // {"lng":116.417784,"lat":39.915754,"count":47}, // {"lng":116.420193,"lat":39.917061,"count":52}, // {"lng":116.422735,"lat":39.915619,"count":100}, // {"lng":116.418495,"lat":39.915958,"count":46}, // {"lng":116.416292,"lat":39.931166,"count":9}, // {"lng":116.419916,"lat":39.924055,"count":8}, // {"lng":116.42189,"lat":39.921308,"count":11}, // {"lng":116.413765,"lat":39.929376,"count":3}, // {"lng":116.418232,"lat":39.920348,"count":50}, // {"lng":116.417554,"lat":39.930511,"count":15}, // {"lng":116.418568,"lat":39.918161,"count":23}, // {"lng":116.413461,"lat":39.926306,"count":3}, // {"lng":116.42232,"lat":39.92161,"count":13}, // {"lng":116.4174,"lat":39.928616,"count":6}, // {"lng":116.424679,"lat":39.915499,"count":21}, // {"lng":116.42171,"lat":39.915738,"count":29}, // {"lng":116.417836,"lat":39.916998,"count":99}, // {"lng":116.420755,"lat":39.928001,"count":10}, // {"lng":116.414077,"lat":39.930655,"count":14}, // {"lng":116.426092,"lat":39.922995,"count":16}, // {"lng":116.41535,"lat":39.931054,"count":15}, // {"lng":116.413022,"lat":39.921895,"count":13}, // {"lng":116.415551,"lat":39.913373,"count":17}, // {"lng":116.421191,"lat":39.926572,"count":1}, // {"lng":116.419612,"lat":39.917119,"count":9}, // {"lng":116.418237,"lat":39.921337,"count":54}, // {"lng":116.423776,"lat":39.921919,"count":26}, // {"lng":116.417694,"lat":39.92536,"count":17}, // {"lng":116.415377,"lat":39.914137,"count":19}, // {"lng":116.417434,"lat":39.914394,"count":43}, // {"lng":116.42588,"lat":39.922622,"count":27}, // {"lng":116.418345,"lat":39.919467,"count":8}, // {"lng":116.426883,"lat":39.917171,"count":3}, // {"lng":116.423877,"lat":39.916659,"count":34}, // {"lng":116.415712,"lat":39.915613,"count":14}, // {"lng":116.419869,"lat":39.931416,"count":12}, // {"lng":116.416956,"lat":39.925377,"count":11}, // {"lng":116.42066,"lat":39.925017,"count":38}, // {"lng":116.416244,"lat":39.920215,"count":91}, // {"lng":116.41929,"lat":39.915908,"count":54}, // {"lng":116.422116,"lat":39.919658,"count":21}, // {"lng":116.4183,"lat":39.925015,"count":15}, // {"lng":116.421969,"lat":39.913527,"count":3}, // {"lng":116.422936,"lat":39.921854,"count":24}, // {"lng":116.41905,"lat":39.929217,"count":12}, // {"lng":116.424579,"lat":39.914987,"count":57}, // {"lng":116.42076,"lat":39.915251,"count":70}, // {"lng":116.425867,"lat":39.918989,"count":8}]; if(!isSupportCanvas()){ alert(‘热力图目前只支持有canvas支持的浏览器,您所使用的浏览器不能使用热力图功能~‘) } //详细的参数,可以查看heatmap.js的文档 https://github.com/pa7/heatmap.js/blob/master/README.md //参数说明如下: /* visible 热力图是否显示,默认为true * opacity 热力的透明度,1-100 * radius 势力图的每个点的半径大小 * gradient {JSON} 热力图的渐变区间 . gradient如下所示 * { .2:‘rgb(0, 255, 255)‘, .5:‘rgb(0, 110, 255)‘, .8:‘rgb(100, 0, 255)‘ } 其中 key 表示插值的位置, 0~1. value 为颜色值. */ heatmapOverlay = new BMapLib.HeatmapOverlay({"radius":20}); map.addOverlay(heatmapOverlay); heatmapOverlay.setDataSet({data:points,max:100}); //是否显示热力图 function openHeatmap(){ heatmapOverlay.show(); } function closeHeatmap(){ heatmapOverlay.hide(); } closeHeatmap(); function setGradient(){ /*格式如下所示: { 0:‘rgb(102, 255, 0)‘, .5:‘rgb(255, 170, 0)‘, 1:‘rgb(255, 0, 0)‘ }*/ var gradient = {}; var colors = document.querySelectorAll("input[type=‘color‘]"); colors = [].slice.call(colors,0); colors.forEach(function(ele){ gradient[ele.getAttribute("data-key")] = ele.value; }); heatmapOverlay.setOptions({"gradient":gradient}); } //判断浏览区是否支持canvas function isSupportCanvas(){ var elem = document.createElement(‘canvas‘); return !!(elem.getContext && elem.getContext(‘2d‘)); } </script>
import pandas as pd import re from matplotlib import pyplot as plt from matplotlib import font_manager import numpy as np from pyecharts import options as opts from pyecharts.charts import Bar # 去哪儿热门景点excel文件保存路径 PLACE_EXCEL_PATH = ‘qunaer.xlsx‘ # 读取数据 DF = pd.read_excel(PLACE_EXCEL_PATH, index_col=0) # 百度热力图模板 HOT_MAP_TEMPLATE_PATH = ‘hot_map_template.html‘ # 生成的国庆旅游景点热力图 PLACE_HOT_MAP_PATH = ‘place_hot_map.html‘ # 字体 font = font_manager.FontProperties(fname=r"C:\Windows\Fonts\msyhbd.ttc") def analysis_sale(): ‘‘‘ 分析门票销量 :return: ‘‘‘ # 引入全局变量 global DF df = DF.copy() place_sale = df.pivot_table(values=‘sale‘, index=‘name‘).reset_index().sort_values(by=‘sale‘, ascending=False)[0:20] print(place_sale) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(20, 8)) # 画条形图 barh = plt.barh(place_sale[‘name‘].values, place_sale[‘sale‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_sale[‘sale‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘销量‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点门票销量TOP20‘, font1) f.savefig(‘1.png‘, bbox_inches=‘tight‘) f.show() def analysis_amout(): """ 分析销售额 :return: """ # 引入全局数据 global DF df = DF.copy() amount_list = [] for index, row in df.iterrows(): try: # 销售额 amount = row[‘price‘] * row[‘sale‘] except: amount = 0 amount_list.append(amount) df[‘amount‘] = amount_list # 生成一个名称和销量的透视表 place_amount = df.pivot_table(index=‘name‘, values=‘amount‘).reset_index().sort_values(‘amount‘, ascending=False)[0:20] print(place_amount) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(20, 8)) # 画条形图 barh = plt.barh(place_amount[‘name‘].values, place_amount[‘amount‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_amount[‘amount‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘销售额‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点门票销量额TOP20‘, font1) f.savefig(‘2.png‘, bbox_inches=‘tight‘) f.show() def analysis_recommend(): """ 瞎推荐排行榜: 高评分、销量低、价格便宜 :return: """ global DF df = DF.copy() recommend_list = [] for index, row in df.iterrows(): try: # 瞎推荐系数算法 recommend = int((row[‘score‘] * 1000) / (row[‘price‘] * row[‘sale‘])) except ZeroDivisionError: recommend = 0 recommend_list.append(recommend) df[‘recommend‘] = recommend_list place_amount = df.pivot_table(index=‘name‘, values=‘recommend‘).reset_index().sort_values(‘recommend‘, ascending=False)[0:20] print(place_amount) plt.rcParams[‘font.sans-serif‘] = ‘simhei‘ # 设置字体大小 font1 = {‘family‘: ‘simhei‘, ‘weight‘: ‘normal‘, ‘size‘: 18, } f, ax = plt.subplots(figsize=(8,6)) # 画条形图 barh = plt.barh(place_amount[‘name‘].values, place_amount[‘recommend‘].values, color=‘dodgerblue‘) barh[0].set_color(‘green‘) # 给条形图添加数据标注 for y, x in enumerate(place_amount[‘recommend‘].values): plt.text(x + 500, y - 0.2, "%s" % x) # 删除所有边框 ax.spines[‘right‘].set_visible(False) ax.spines[‘top‘].set_visible(False) ax.spines[‘bottom‘].set_visible(False) ax.spines[‘left‘].set_visible(False) plt.tick_params(labelsize=14) plt.xlabel(‘瞎推荐指数‘, font1) plt.ylabel(‘景点名称‘, font1) plt.title(‘国庆旅游热门景点瞎推荐TOP20‘, font1) f.savefig(‘3.png‘, bbox_inches=‘tight‘) f.show() def analysis_point_sale(): """ 生成热力图,使用百度地图api :return: """ # 引入全局数据 global DF df = DF.copy() point_sale_list = [] for index, row in df.iterrows(): # 构建坐标数据 lng, lat = row[‘point‘].split(‘,‘) count = row[‘sale‘] point_sale = {‘lng‘: float(lng), ‘lat‘: float(lat), ‘count‘: count} point_sale_list.append(point_sale) print(point_sale_list) data = f‘var points ={str(point_sale_list)};‘ # 替换模板中的坐标数据 with open(HOT_MAP_TEMPLATE_PATH, ‘r‘, encoding="utf-8") as f1, open(PLACE_HOT_MAP_PATH, ‘w‘, encoding="utf-8") as f2: s = f1.read() # 替换数据 s2 = s.replace(‘%data%‘, data) f2.write(s2) f1.close() f2.close() if __name__ == ‘__main__‘: # analysis_sale() #analysis_amout() #analysis_recommend() analysis_point_sale()
用Python分析国庆旅游景点,告诉你哪些地方好玩、便宜、人又少
原文:https://www.cnblogs.com/huiyichanmian/p/11604702.html
