NumPy是Python中科学计算的基本软件包。它是一个Python库,提供多维数组对象,各种派生对象(例如蒙版数组和矩阵)
以及各种例程,用于对数组进行快速操作,包括数学,逻辑,形状处理,排序,选择,I / O ,离散傅立叶变换,基本线性代数,基本统计运算,随机模拟等等。
NumPy包的核心是ndarray对象。这封装了均匀数据类型的n维数组,为了提高性能,许多操作都在编译后的代码中执行。NumPy数组和标准Python序列之间有几个重要的区别:
向量化描述了代码中没有任何显式的循环,索引等操作-当然,这些事情发生在优化的预编译C代码中的“幕后”。向量化代码具有许多优点,其中包括:
for循环。广播是一个术语,用于描述操作的隐式逐元素行为。一般而言,在NumPy中,所有运算,不仅是算术运算,而且是逻辑,按位,函数等,均以这种逐个元素的隐式方式进行操作,即广播。而且,在上面的示例中,a并且b可以是相同形状的多维数组,或者是标量和数组,甚至可以是形状不同的两个数组,条件是较小的数组可以“扩展”到较大的形状。最终广播是明确的。有关广播的详细“规则”,请参见numpy.doc.broadcasting。
NumPy完全支持面向对象的方法,再次从ndarray开始。例如,ndarray是一个类,具有许多方法和属性。它的许多方法都由最外层的NumPy命名空间中的函数反映,从而允许程序员以他们喜欢的任何范式进行编码。这种灵活性使NumPy数组方言和NumPy ndarray类成为了Python中使用的多维数据交换的事实上的语言。
特点:快速、方便、科学计算库
import numpy as np
#创建数组
a = np.array([1,2,3,4,5])
b = np.array(range(1,6))
c = np.arange(1,6)#b和c相比,方便
print(a,b,a)
#上面创建a,b,c都相同,都是创建了一个一维数组

a = np.array([2,3,4,5,6])
print(type(a))

print(a.dtype)
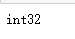
# a = np.array([1,0,2,0],dtype=np.bool)#或者使用dtype="?" a = np.array([1,0,2,0],dtype="?")#或者使用dtype="?" print(a)
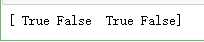
# a.astype("i1")#或者使用a.astype(np.int8)
a.astype(np.int8)
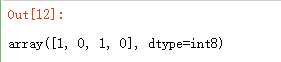
import random
#生成一维10个数的数组
a = np.array([random.random() for i in range(10)])
print(a)
print(type(a))
print(a.dtype)

#保留几位小数
b = np.round(a,2)
print(b)

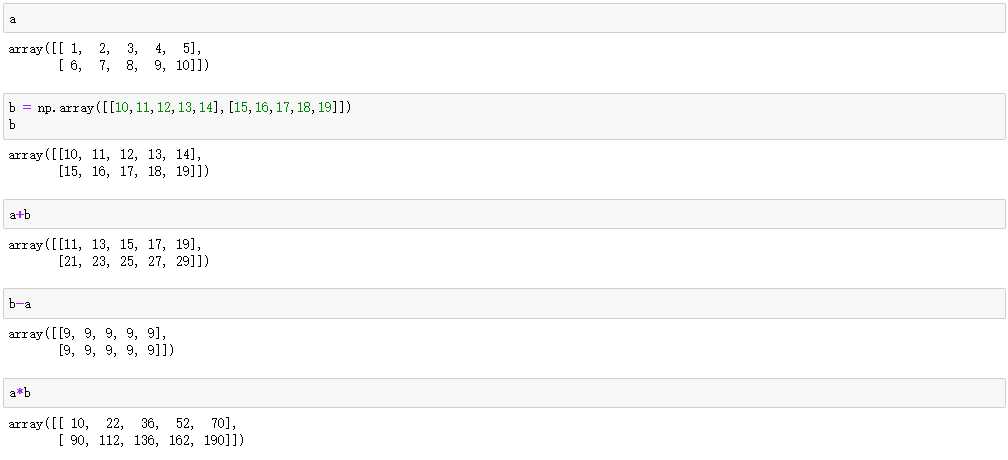
a = np.array([[1,2,3,4,5],[6,7,8,9,10]])
a

b = a.reshape(5,2)
print(b)
print(a)#可以看出修改形状,不是在a的基础上修改
#是备份修改的

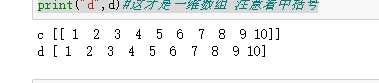
c = b.reshape(1,10)##注意这不是一维数组,这是二维
print("c",c)
d = b.reshape((10,))
print("d",d)#这才是一维数组 注意看中括号
b.flatten()#这个是一维的
b.reshape(1,10)#这个是二维的



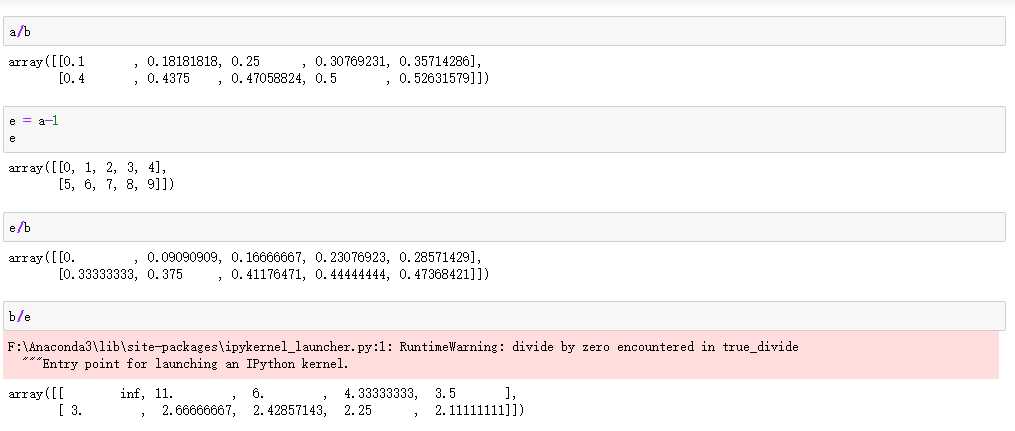

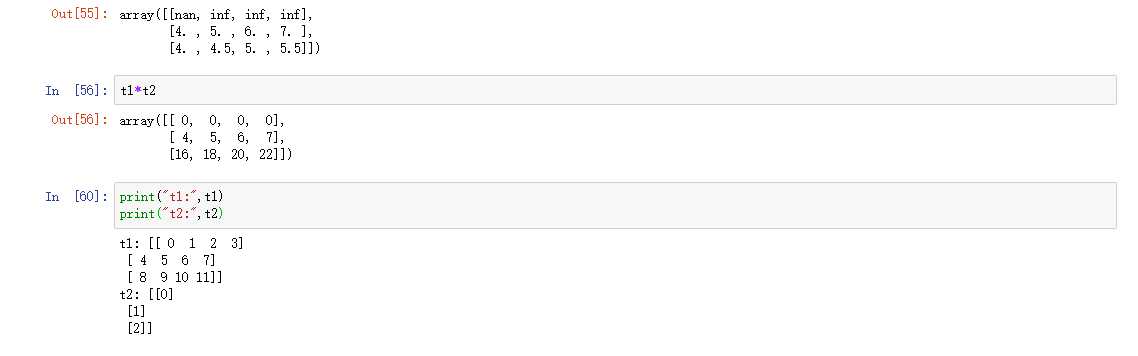
在上面可以看出结果中有inf这个标志,这是无穷大的意思,是无穷大单词的缩写。
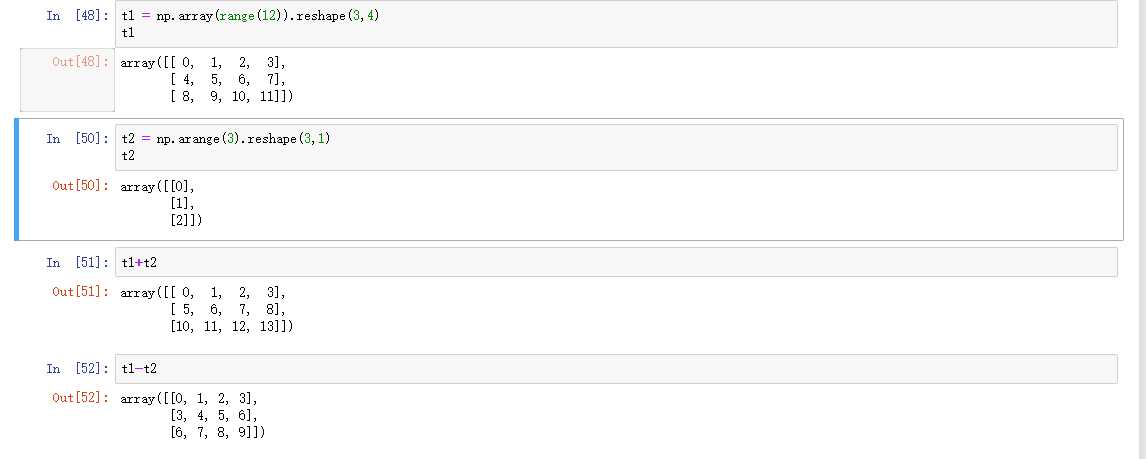
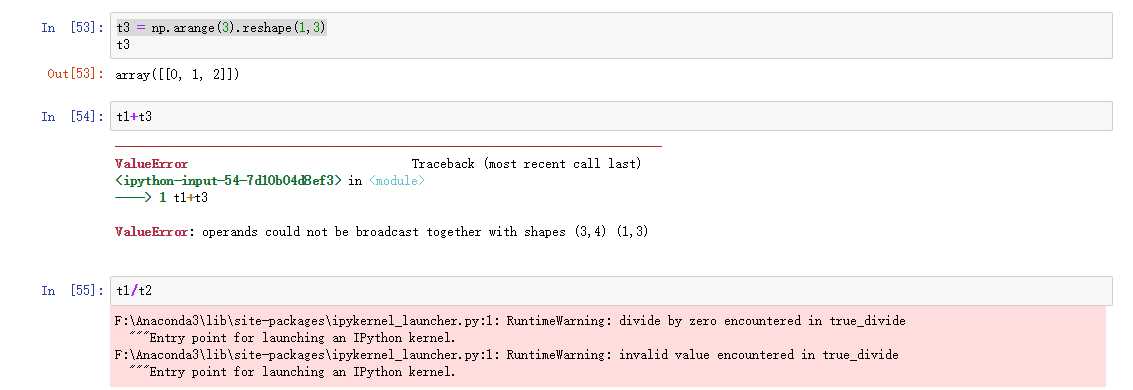
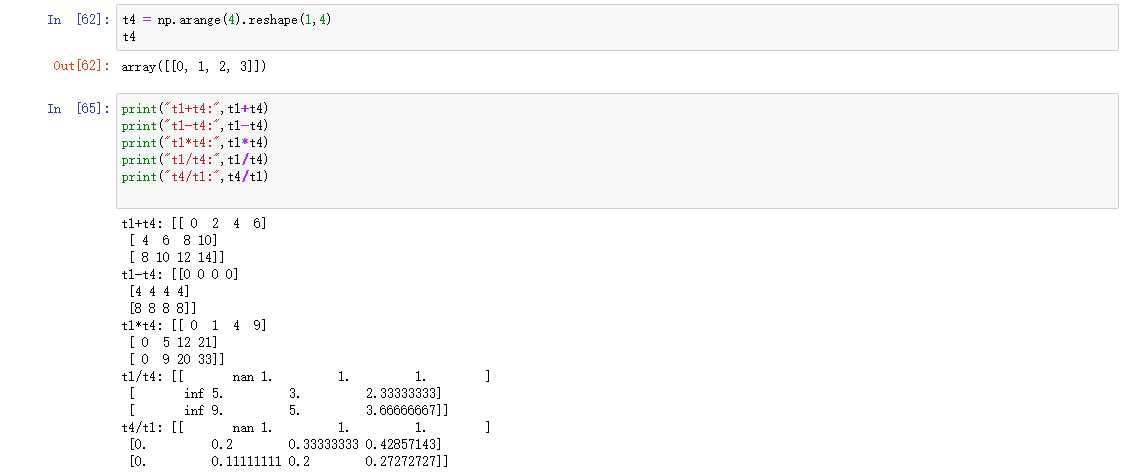
怎么理解呢? 可以把维度指的是shape所对应的数字个数那么问题来了: shape为(3,3,3)的数组能够和(3,2)的数组进行计算么?
答案是不能的,在任意维度没有相同的,是不能进行运算的。
shape为(3,3,2)的数组能够和(3,2)的数组进行计算么? 有什么好处呢?
可以进行运算,存在维度相同,换句话来说理解有点难,那么可以想出一维与二维进行运算的条件也就是这个意思。
举个例子:每列的数据减去列的平均值的结果
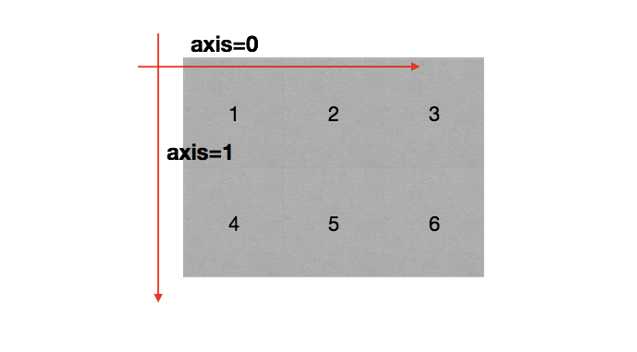
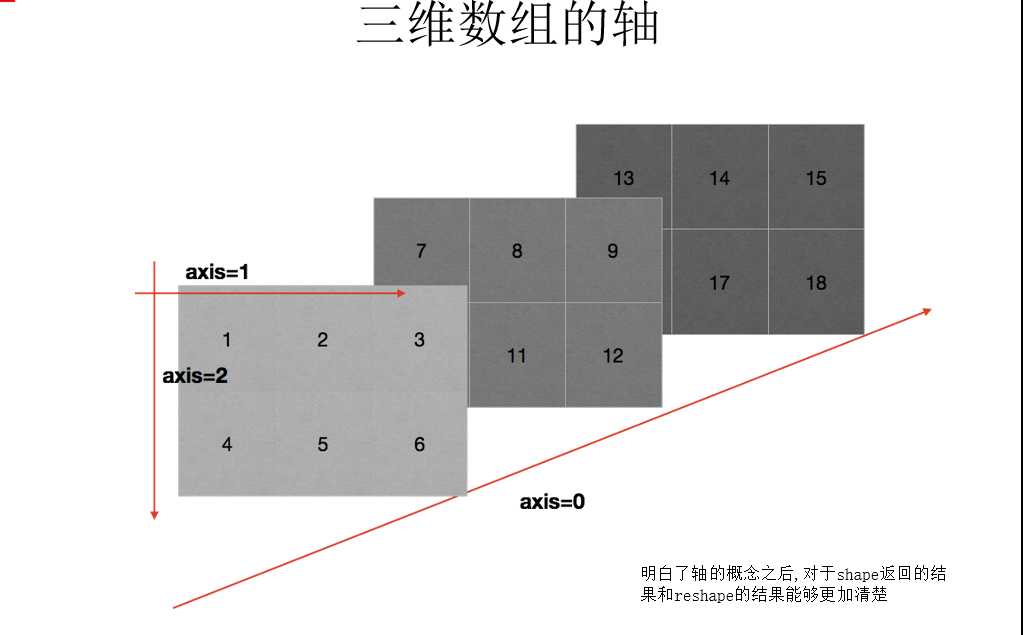
在numpy中可以理解为方向,使用0, 1,2...数字表示,对于一个- -维数组,只有一个0轴,对于2维数组(shape (2, 2)),有0轴和1轴,对于三维数组(shape(2,2,3)), 有0, 1, 2轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
那么问题来了:
在前面的知识,轴在哪里?
回顾np. arange (0, 10). reshape (2, 5)), reshpe中2表示0轴长度(包含数据的条数)为2, 1轴长度为5, 2*5-共10个数据
二维数组的轴:
三维数组的轴:
原文:https://www.cnblogs.com/lishuntao/p/11607983.html