1.交叉熵:交叉熵刻画了两个概率分布之间的距离,它是分类问题中使用比较广的一种损失函数。通过q来表示p的交叉熵为:
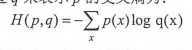
Softmax将神经网络前向传播得到的结果变成概率分布,原始神经网络的输出被用作置信度来生成新的输出,而新的输出满足概率分布的所有要求。
交叉熵函数不是对称的,H(p,q)!=H(q,p),他刻画的是通过概率分布q来表达概率分布p的困难程度。因为正确答案是希望得到的结果,所以当交叉熵作为神经网络的损失函数是,p代表的是正确答案,q代表的是预测值。交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
tensorflow实现交叉熵代码:
其中y_代表正确结果,y代表预测结果。tf.clip_by_value()函数的意思是,小于1e-10的数全换成1e-10,大于1的数全换成1。tensorflow中*的意思是对应相同位置的数项乘,不是矩阵的乘法。
因为交叉熵一般会与softmax回归一起使用,所以tensorflow对这两个功能进行了统一封装:
通过这个命令就可以得到使用了Softmax回归之后的交叉熵。
在只有一个正确答案的分类问题中,tensorflow提供了tf.nn.sparse_softmax_cross_entropy_with_logits函数来进一步加速计算过程。
2.损失函数---------经典损失函数--------均方误差(MSE,mean squared error):
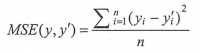
其中yi为一个batch中第i个数据的正确答案,而yi‘为神经网络给出的预测值。tensorflow实现代码: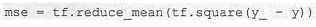
3.损失函数---------自定义函数-----
tf.greater(A,B) 返回A>B的结果,布尔值
tf.select(C,A,B) C为真时(True),返回A值,为假(False)时返回B值。
这两个函数都是在元素级别进行
原文:https://www.cnblogs.com/Turing-dz/p/11609833.html