1、df = pd.read_csv(‘/home/greg/桌面/uk_rain_2014.csv‘, sep=‘,‘,header=0)
# 默认第一行为列名,列名不读入
第一个是文件名,
第二个是分隔符,也就是两列之间的分隔符,默认是‘,‘,
第三个参数也就是文件每一列的命名,如果没有列名可设置为header=None
从限定分隔符文本中导入数据,read_tabel
从excel中读入数据,read_excel
2、构造数据
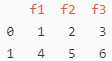
df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=[‘f1‘, ‘f2‘, ‘f3‘])
按列生成:df = pd.DataFrame({‘user_id‘:[1,2,3], ‘item_id‘:[12,34,56]})

3、输出到文件
df.to_csv(‘~/桌面/test.csv‘, index=False, sep=‘,‘)
4、读取单元格内容
_csv_files = pd.read_csv(csv_file, encoding=‘utf-8‘)
file_name = _csv_files.iloc[index,0] # index是行,0是列
5、
原文:https://www.cnblogs.com/zhengbiqing/p/11300195.html