这次就边学边总结吧,不等到最后啦
Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
Ch3. Memory Hierarchy
1. Physical Memory
SRAM:CPU缓存(比如PentiumII的外置二级缓存芯片)
DRAM:内存芯片,需要Dynamic刷新。
- 从概念上分为:Channel > DIMM > Rank > Chip > Bank > Row/Column
- Channel:一个主板上可能有多个插槽,用来插多根内存。这些槽位分成两组或多组,组内共享物理信号线。这样的一组数据信号线、对应几个槽位、对应几根内存条称为一个channel,一个通道。
- DIMM是主板上的一个内存插槽
- Rank是一组内存芯片的集合。当芯片位宽x芯片数=64bits(内存总位宽)时,这些芯片就组成一个Rank。一般是一个芯片位宽8bit,然后内存每面8个芯片,那么这一面就构成一个Rank。(为了提高容量,有些双面内存条就有两个rank。在DDR总线上可以用一根地址线来区分当前要访问的是哪一组)
- Chip是内存条上的一个芯片
- Bank:假设一个chip的位宽是8bit,那么这个芯片就包括8个bank。每个bank可以理解成一个二维数组bool[row][column]。这样通过指定row和column,就可以从所有bank中一共取出8bit的数据。
- Row/Column:上面说过啦……
以淘宝某廉价内存条南亚易胜 Elixir DDR3 1600 4G 2R*8 PC3-12800S 1.5V 笔记本内存 双面16颗粒为例:
这个内存一共双面16芯片,芯片型号为N2CB2G80BN,查datasheet可知每个芯片有8 Internal memory banks,位宽也是8bit。这样每一面的8个芯片就构成一个Rank,整个内存条一共两个Rank。
那么CPU是如何读取内存的呢?• CPU一次需要访问64bit的数据(也叫做一个字)。那么对于上面这根内存,一个Rank可以提供8bit per chip * 8 chips per Rank = 64bit的带宽,就正好对接上啦。每个chip的同一bank(bank=k )的同一地点(row=i, col=j)都会被读出8bit,那么8个chip就会同时读出64bit,然后由memory controllers传送给cpu。如图:
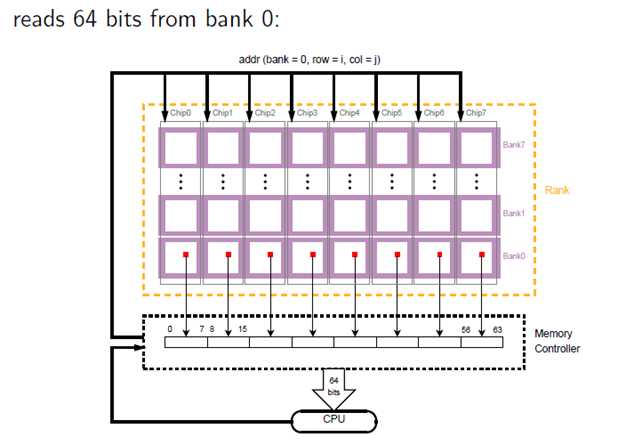
为了保证和CPU的沟通(要满64bit),一个内存至少要有一个RANK。但是为了保证大容量,DDR3内存经常是采用一个内存两个RANK的架构,一般也就是双面16颗粒。(过去也有用几个模组组成一个RANK的情况。比如EDO内存的带宽只有32bit,但586及以上cpu的数据总线都是64bit,所以就需要成对使用)
Ref:
https://zhuanlan.zhihu.com/p/33479194
https://blog.51cto.com/10914132/1733629
https://zhuanlan.zhihu.com/p/25863918
http://lzz5235.github.io/2015/04/21/memory.html
2. Locality(PPT P12/HI P253)
Programs tend to reuse data and instructions near those they have used recently, or that were recently referenced themselves.
- Temporal locality: Recently referenced items are likely to be referenced in the near future.
- Spatial locality: Items with nearby addresses tend to be referenced close together in time.
利用局部性原理,可以将存储器组织成存储器层次结构。相邻两层之间数据交换的单位叫做块(block)
3. Cache(PPT P15 / HI P254)
以块为单位从level k+1 cache到 level k
- Cache hit: level k中有目标块
- Cache miss: 块在level k中没有,要从level k+1中读进来
- Placement policy: where can the new block be placed in level k? E.g., b mod 4
- Replacement policy: which block should be evicted from level k? E.g., LRU
4. Question about caching
1,2: Where can a block be placed in the upper level? • How is a block found if it is in the upper level? (PPT P17 / HI P259)
地址映像方式:内存中block地址与cache中block地址的对应方式(内存和cache中一个块的大小都相等)。缓存中这个block又叫做cacheline。
cache分成多个组,每个组分成多个行,cacheline是cache的基本单位,从主存向cache迁移数据按照cacheline为单位替换。
- 全相连:主存中的一块可以映象到Cache中的任意一块。在cache中维护一个目录表,记录主存块号对应的cache块号
- 直接相联:主存储器中一块只能映象到Cache的一个特定的块中。(HI P260-P264)
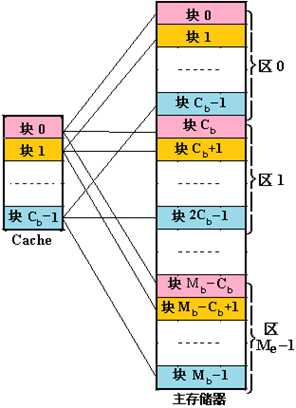
- N路组相连:主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同(主存中每组N个块,cache分为N个组)。组间采用直接映射,组内采用全相联映射(a block goes any frame in exactly one set,主存中一个组内的N个块可映射到cache中某特定组内N个块中的任意一个)。如图是一个Cb组相连的cache:
Ref:
https://blog.csdn.net/onlyoncelove/article/details/80426874
https://zhuanlan.zhihu.com/p/60843893
https://zhuanlan.zhihu.com/p/37749443
3: Which block should be replaced on a miss? (PPT P22)
3种cache miss:
- Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses.
- Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved.
- Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses.
Least recently used — LRU
Not most recently used — NMRU
4: What happens on a write(PPT P29)
计算
Virtual Memory P41
计算机体系结构总结
原文:https://www.cnblogs.com/pdev/p/11617051.html