一提到语言这个词语,自然会想到的是像英语、汉语等这样的自然语言,因为它是人和人交换信息不可缺少的工具。而今天计算机遍布了我们生活的每一个角落,除了人和人的相互交流之外,我们必须和计算机角落。用什么的什么样的方式和计算机做最直接的交流呢?人们自然想到的是最古老也最方便的方式——语言,而C语言就是人和计算机交流的一种语言。语言是用来交流沟通的。有一方说,有另一方听,必须有两方参与,这是语言最重要的功能:
•说的一方传递信息,听的一方接收信息;
•说的一方下达指令,听的一方遵循命令做事情。
语言是人和人交流,C语言是人和机器交流。只是,人可以不听另外一个人,但是,计算机是无条件服从。语言有独特的语法规则和定义,双方必须遵循这些规则和定义才能实现真正的交流。
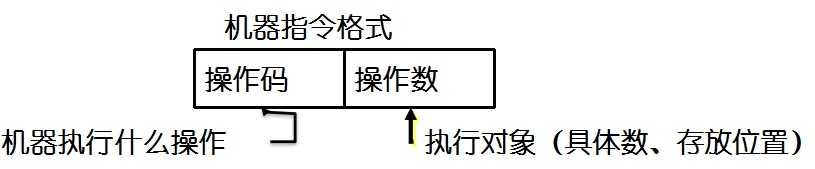
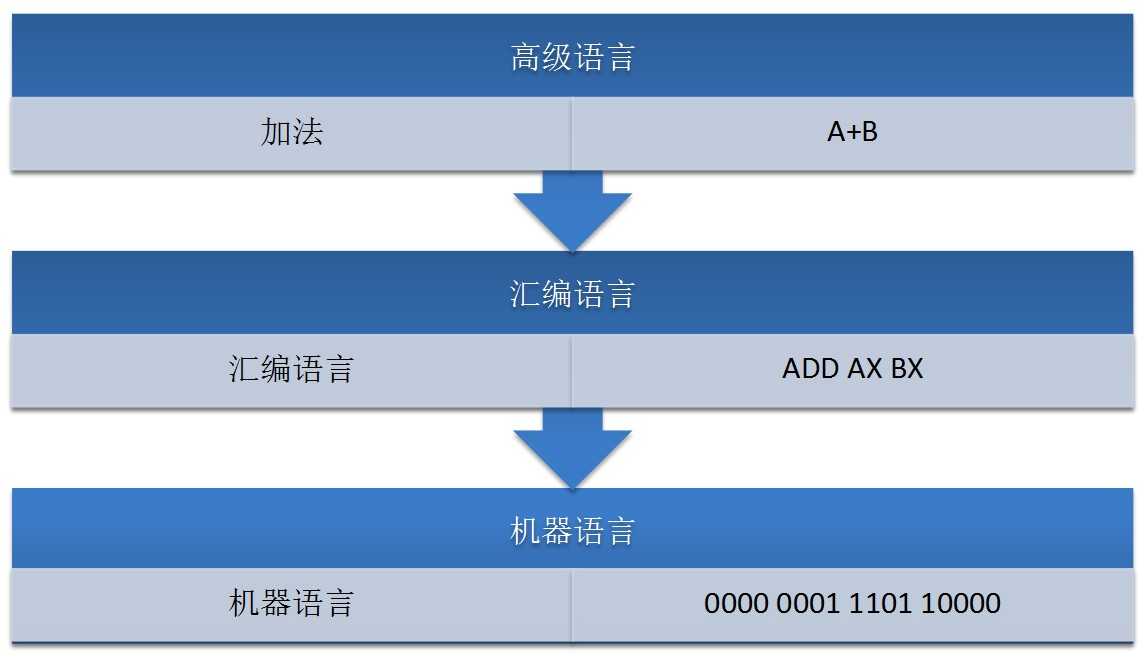
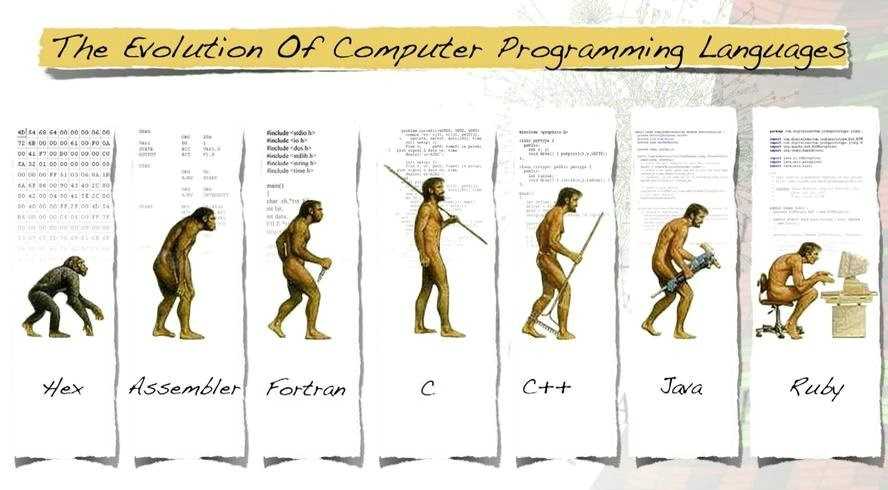
计算机的大脑或者说心脏就是CPU,它控制着整个计算机的运作。每种CPU,都有自己的指令系统。这个指令系统,就是该CPU的机器语言。机器语言是一组由0和1系列组成的指令码,这些指令码,是CPU制作厂商规定出来的,然后发布出来,请程序员遵守。要让计算机干活,就得用机器语言(二级制数)去命令它。这样的命令,不是一条两条,而是上百条。而且不同型号的计算机其机器语言是不相通的,按着一种计算机的机器指令编制的程序,不能在另一种计算机上执行。
机器语言编程是不是很令人烦恼呢,终于出现了汇编语言,就是一些标识符取代0与1。一门人类可以比较轻松认识的编程语言。只是这门语言计算机并不认识,所以人类还不能用这门语言命令计算机做事情。这正如如何才能让中国人说的话美国人明白呢?——翻译!所以,有一类专门的程序,既认识机器语言,又认识汇编语言,也就是编译器,将标识符换成0与1,知道怎么把汇编语言翻译成机器语言。
汇编语言和机器语言都是面向机器的,机器不同,语言也不同。既然有办法让汇编语言翻译成机器语言,难道就不能把其他更人性化的语言翻译成机器语言?1954年,Fortran语言出现了,其后相继出现了其他的类似语言。这批语言,使程序员摆脱了计算机硬件的限制,把主要精力放在了程序设计上,不在关注低层的计算机硬件。这类语言,称为高级语言。同样的,高级语言要被计算机执行,也需要一个翻译程序将其翻译成机器语言,这就是编译程序,简称编译器。这类高级语言解决问题的方法是分析出解决问题所需要的步骤,把程序看作是数据被加工的过程。基于这类方法的程序设计语言成为面向过程的语言。C语言就是这种面向过程的程序设计语言。
C语言的应用极其广泛,从网站后台,到底层操作系统,从多媒体应用到大型网络游戏,均可使用C语言来开发:

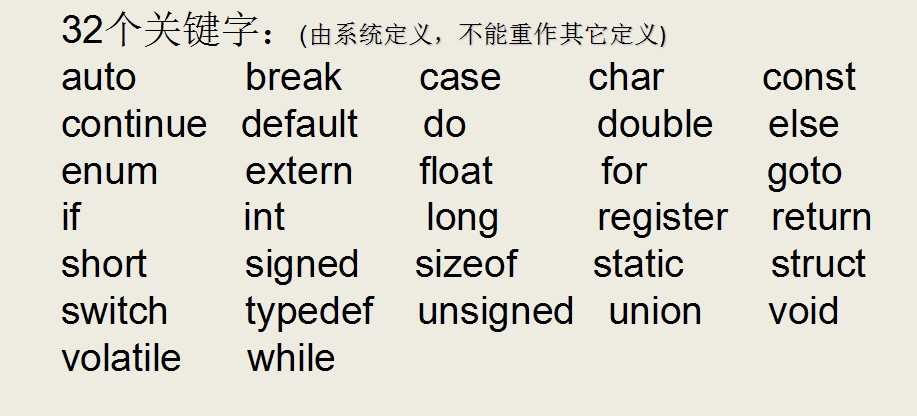
C语言仅有32个关键字,9种控制语句,34种运算符,却能完成无数的功能:


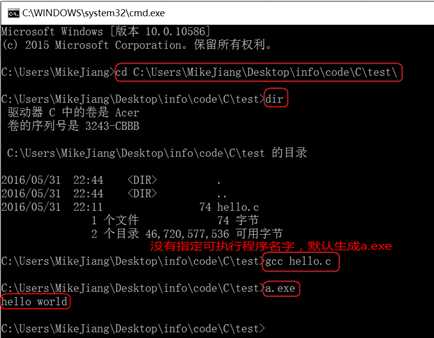
#include <stdio.h>
int main(void)
{
//这是第一个C语言代码
printf("hello world\n");
return 0;
//C语言的源代码文件是一个普通的文本文件,但扩展名必须是.c。
}
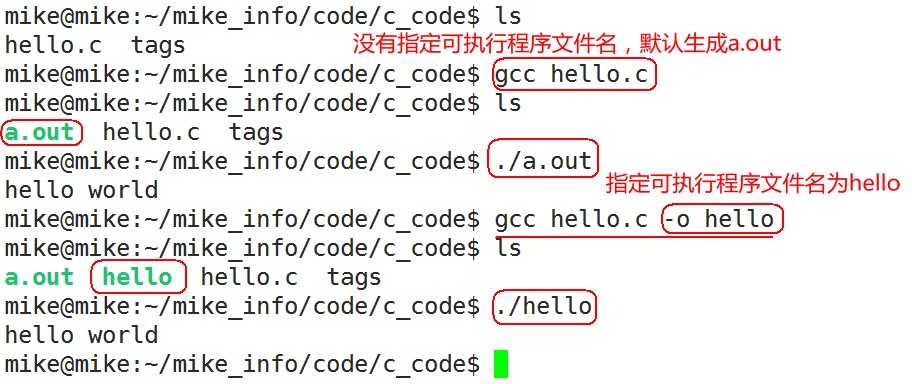
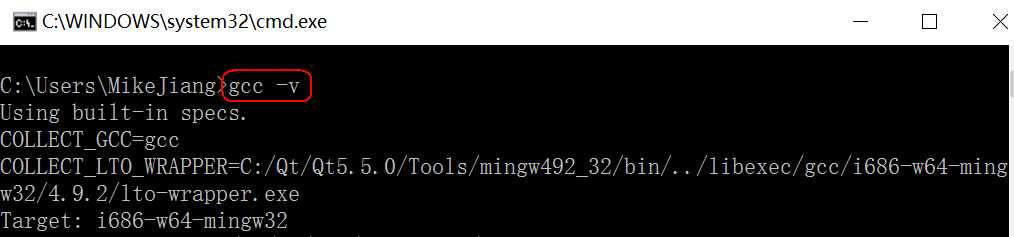
编辑器(如vi、记事本)是指我用它来写程序的(编辑代码),而我们写的代码语句,电脑是不懂的,我们需要把它转成电脑能懂的语句,编译器就是这样的转化工具。就是说,我们用编辑器编写程序,由编译器编译后才可以运行!编译器是将易于编写、阅读和维护的高级计算机语言翻译为计算机能解读、运行的低级机器语言的程序。gcc(GNU Compiler Collection,GNU 编译器套件),是由 GNU 开发的编程语言编译器。gcc原本作为GNU操作系统的官方编译器,现已被大多数类Unix操作系统(如Linux、BSD、Mac OS X等)采纳为标准的编译器,gcc同样适用于微软的Windows。gcc最初用于编译C语言,随着项目的发展gcc已经成为了能够编译C、C++、Java、Ada、fortran、Object C、Object C++、Go语言的编译器大家族。
编译命令格式:
gcc [-option1] ... <filename> g++ [-option1] ... <filename>
gcc、g++编译常用选项说明:
|
选项 |
含义 |
|
-o file |
指定生成的输出文件名为file |
|
-E |
只进行预处理 |
|
-S(大写) |
只进行预处理和编译 |
|
-c(小写) |
只进行预处理、编译和汇编 |
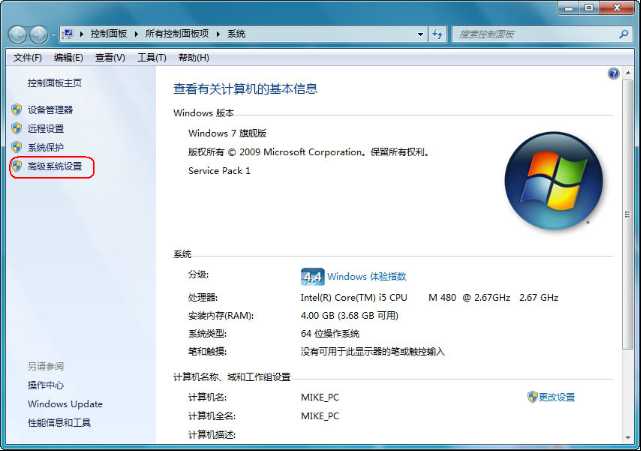
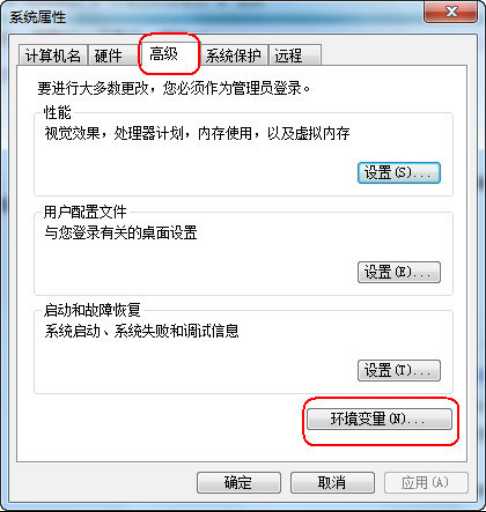
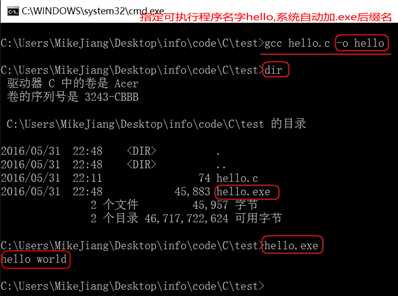
windows命令行界面下,默认是没有gcc编译器,我们需要配置一下环境。由于我们安装了Qt,Qt是一个集成开发环境,内部集成gcc编译器,配置一下环境变量即可使用gcc。
C:\Qt\Qt5.5.0\Tools\mingw492_32\bin

计算机(右击)-> 属性:
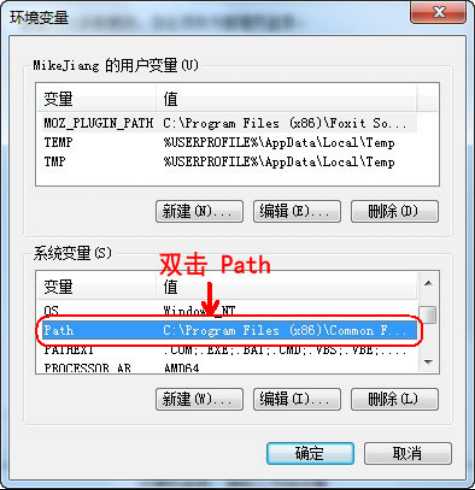
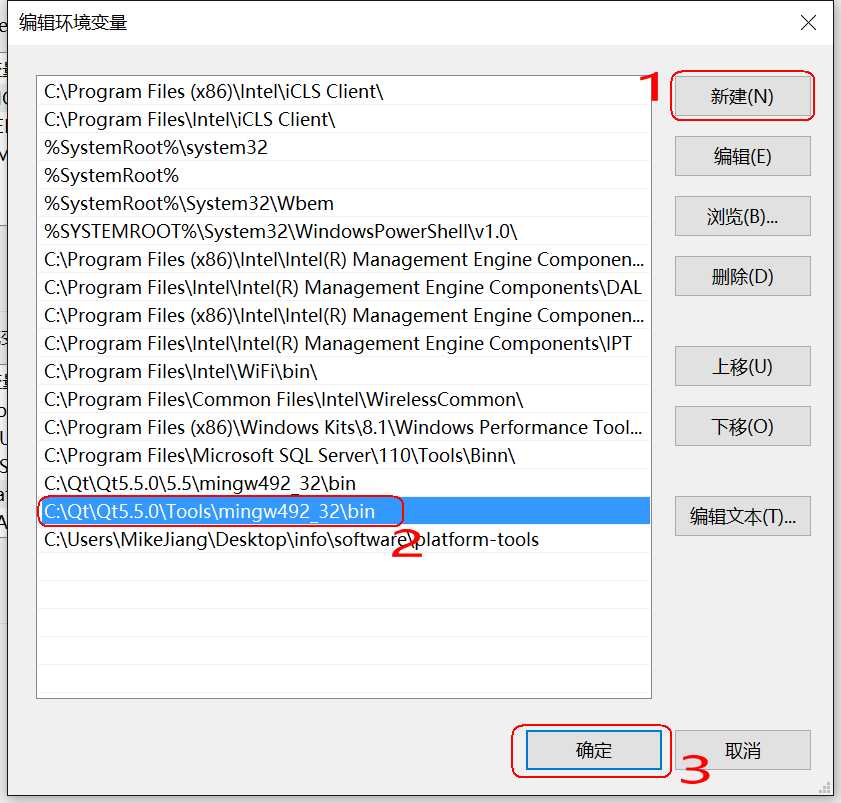
如果是win7,双击Path后,把拷贝的路径追加到后面,路径之间需要英文” ; ”分隔:
如果是win10,界面做得友好一下,新建添加路径即可:
Linux编译后的可执行程序只能在Linux运行,Windows编译后的程序只能在Windows下运行。
64位的Linux编译后的程序只能在64位Linux下运行,32位Linux编译后的程序只能在32位的Linux运行。
64位的Windows编译后的程序只能在64位Windows下运行,32位Windows编译后的程序可以在64位的Windows运行。
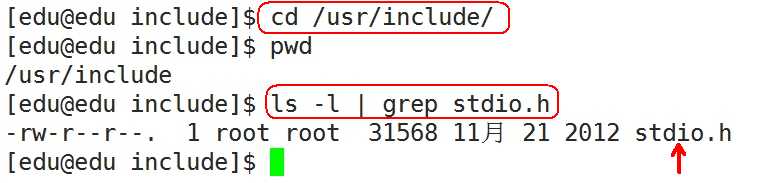
#include< > 与 #include ""的区别:
stdio.h是在操作系统的系统目录下:
#include <stdlib.h>
int system(const char *command);
功能:在已经运行的程序中执行另外一个外部程序
参数:外部可执行程序名字
返回值:
成功:不同系统返回值不一样
失败:通常是 - 1
示例代码:
#include <stdio.h>
#include <stdlib.h>
int main()
{
//system("calc"); //windows平台
system("ls"); //Linux平台, 需要头文件#include <stdlib.h>
return 0;
}
C语言所有的库函数调用,只能保证语法是一致的,但不能保证执行结果是一致的,同样的库函数在不同的操作系统下执行结果可能是一样的,也可能是不一样的。
在学习Linux发展史时,我们得知Linux的发展离不开POSIX标准,只要符合这个标准的函数,在不同的系统下执行的结果就可以一致。
Unix和linux很多库函数都是支持POSIX的,但Windows支持的比较差。
如果将Unix代码移植到Linux一般代价很小,如果把Windows代码移植到Unix或者Linux就比较麻烦。
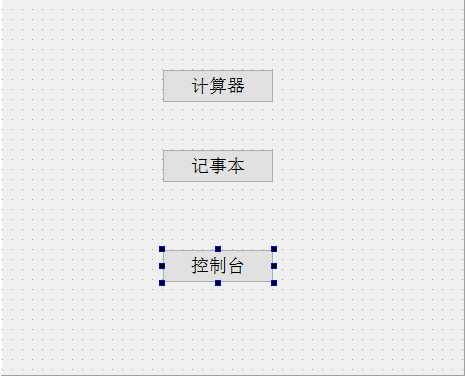
void Widget::on_pushButton_clicked()
{
//system("calc"); //需要头文件:#include <stdlib.h>
WinExec("calc", SW_NORMAL); //需要头文件:#include <windows.h>
}
void Widget::on_pushButton_2_clicked()
{
system("notepad");
}
void Widget::on_pushButton_3_clicked()
{
system("mmc");
}
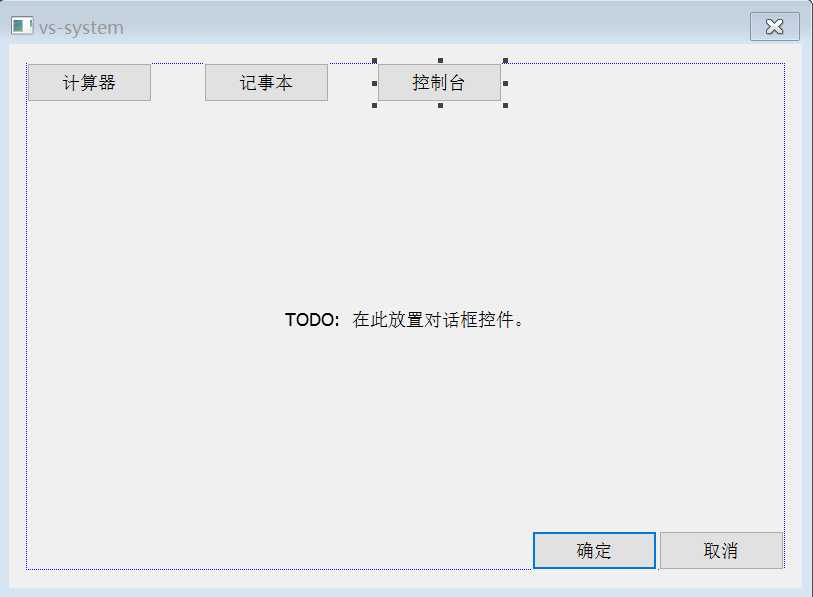
void CvssystemDlg::OnBnClickedButton1()
{
// TODO: 在此添加控件通知处理程序代码
//WinExec("calc", SW_NORMAL); 需要头文件:#include <windows.h>
system("calc"); //需要头文件:#include <stdlib.h>
}
void CvssystemDlg::OnBnClickedButton2()
{
// TODO: 在此添加控件通知处理程序代码
//WinExec("notepad", SW_NORMAL);
system("notepad");
}
C代码编译成可执行程序经过4步:
1)预处理:宏定义展开、头文件展开、条件编译等,同时将代码中的注释删除,这里并不会检查语法
2)编译:检查语法,将预处理后文件编译生成汇编文件
3)汇编:将汇编文件生成目标文件(二进制文件)
4)链接:C语言写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终的可执行程序中去
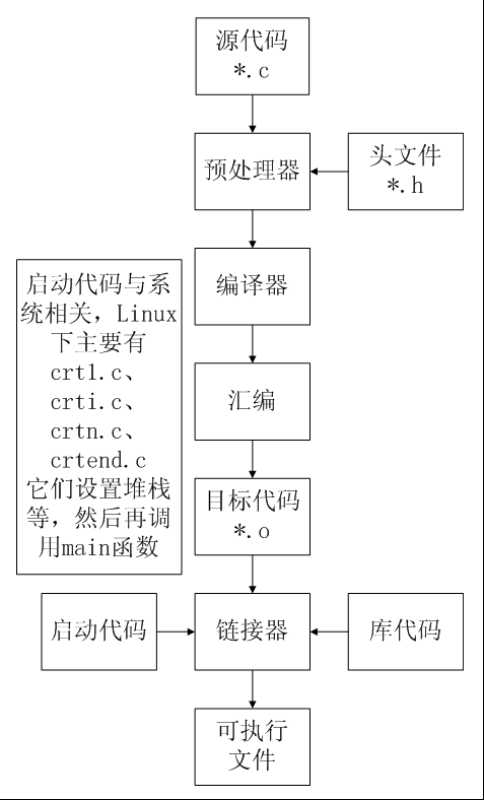
预处理:gcc -E hello.c -o hello.i
编 译:gcc -S hello.i -o hello.s
汇 编:gcc -c hello.s -o hello.o
链 接:gcc hello.o -o hello_elf
|
选项 |
含义 |
|
-E |
只进行预处理 |
|
-S(大写) |
只进行预处理和编译 |
|
-c(小写) |
只进行预处理、编译和汇编 |
|
-o file |
指定生成的输出文件名为 file |
|
文件后缀 |
含义 |
|
.c |
C 语言文件 |
|
.i |
预处理后的 C 语言文件 |
|
.s |
编译后的汇编文件 |
|
.o |
编译后的目标文件 |

gcc hello.c -o demo(还是经过:预处理、编译、汇编、链接的过程):

1)Linux平台下,ldd(“l”为字母) 可执行程序:

2)Windows平台下,需要相应软件(Depends.exe):
|
8位 |
16位 |
32位 |
64位 |
|
A |
AX |
EAX |
RAX |
|
B |
BX |
EBX |
RBX |
|
C |
CX |
ECX |
RCX |
|
D |
DX |
EDX |
RDX |
按与CPU远近来分,离得最近的是寄存器,然后缓存(CPU缓存),最后内存。
CPU计算时,先预先把要用的数据从硬盘读到内存,然后再把即将要用的数据读到寄存器。于是 CPU<--->寄存器<--->内存,这就是它们之间的信息交换。
那为什么有缓存呢?因为如果老是操作内存中的同一址地的数据,就会影响速度。于是就在寄存器与内存之间设置一个缓存。
因为从缓存提取的速度远高于内存。当然缓存的价格肯定远远高于内存,不然的话,机器里就没有内存的存在。
由此可以看出,从远近来看:CPU〈---〉寄存器〈---> 缓存 <---> 内存。
#include <stdio.h>
int main()
{
//定义整型变量a, b, c
int a;
int b;
int c;
__asm
{
mov a, 3 //3的值放在a对应内存的位置
mov b, 4 //4的值放在a对应内存的位置
mov eax, a //把a内存的值放在eax寄存器
add eax, b //eax和b相加,结果放在eax
mov c, eax //eax的值放在c中
}
printf("%d\n", c);//把c的值输出
return 0;//成功完成
}
#include <stdio.h>
int main(void)
{
//定义整型变量a, b, c
int a;
int b;
int c;
a = 3;
b = 4;
c = a + b;
printf("%d\n", c);//把c的值输出
return 0;//成功完成
}
1)设置断点F9
2)选择反汇编按钮
3)根据汇编代码分析程序
集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。
Qt Creator是跨平台的 Qt IDE, Qt Creator 是 Qt 被 Nokia 收购后推出的一款新的轻量级集成开发环境(IDE)。此 IDE 能够跨平台运行,支持的系统包括 Linux(32 位及 64 位)、Mac OS X 以及 Windows。根据官方描述,Qt Creator 的设计目标是使开发人员能够利用 Qt 这个应用程序框架更加快速及轻易的完成开发任务。
|
快捷键 |
含义 |
|
Ctrl + i |
自动格式化代码 |
|
Ctrl + / |
注释/取消注释 |
|
Alt + Enter |
自动完成类函数定义 |
|
F4 |
.h 文件和对应.cpp 文件切换 |
|
F9 |
设置断点 |
|
F5 |
调试运行 |
|
Ctrl + r |
编译,但不调试运行 |
|
Ctrl + b |
编译,不运行 |
|
F10 |
next调试 |
|
F11 |
step调试 |
Microsoft Visual Studio(简称VS)是美国微软公司的开发工具包系列产品。VS是一个基本完整的开发工具集,它包括了整个软件生命周期中所需要的大部分工具,如UML工具、代码管控工具、集成开发环境(IDE)等等,所写的目标代码适用于微软支持的所有平台。Visual Studio是目前最流行的Windows平台应用程序的集成开发环境。
|
快捷键 |
含义 |
|
Ctrl + k,Ctrl + f |
自动格式化代码 |
|
Ctrl + k,Ctrl + c |
注释代码 |
|
Ctrl + k,Ctrl + u |
取消注释代码 |
|
F9 |
设置断点 |
|
F5 |
调试运行 |
|
Ctrl + F5 |
不调试运行 |
|
Ctrl + Shift + b |
编译,不运行 |
|
F10 |
next调试 |
|
F11 |
step调试 |
由于微软在VS2013中不建议再使用C的传统库函数scanf,strcpy,sprintf等,所以直接使用这些库函数会提示C4996错误:
VS建议采用带_s的函数,如scanf_s、strcpy_s,但这些并不是标准C函数。
要想继续使用此函数,需要在源文件中添加以下指令就可以避免这个错误提示:
#define _CRT_SECURE_NO_WARNINGS //这个宏定义最好要放到.c文件的第一行 #pragma warning(disable:4996) //或者使用这个
数据类型的作用:编译器预算对象(变量)分配的内存空间大小
常量:
|
整型常量 |
100,200,-100,0 |
|
实型常量 |
3.14 , 0.125,-3.123 |
|
字符型常量 |
‘a’,‘b’,‘1’,‘\n’ |
|
字符串常量 |
“a”,“ab”,“12356” |
变量:
标识符命名规则:
变量特点:
#include <stdio.h>
int main(void)
{
//extern 关键字只做声明,不能做任何定义,后面还会学习,这里先了解
//声明一个变量a,a在这里没有建立存储空间
extern int a;
a = 10; //err, 没有空间,就不可以赋值
int b = 10; //定义一个变量b,b的类型为int,b赋值为10
return 0;
}
从广义的角度来讲声明中包含着定义,即定义是声明的一个特例,所以并非所有的声明都是定义:
一般的情况下,把建立存储空间的声明称之为“定义”,而把不需要建立存储空间的声明称之为“声明”。
#include <stdio.h>
#define MAX 10 //声明了一个常量,名字叫MAX,值是10,常量的值一旦初始化不可改
int main(void)
{
int a; //定义了一个变量,其类型为int,名字叫a
const int b = 10; //定义一个const常量,名为叫b,值为10
//b = 11; //err,常量的值不能改变
//MAX = 100; //err,常量的值不能改变
a = MAX;//将abc的值设置为MAX的值
a = 123;
printf("%d\n", a); //打印变量a的值
return 0;
}
进制也就是进位制,是人们规定的一种进位方法。 对于任何一种进制—X进制,就表示某一位置上的数运算时是逢X进一位。 十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。
|
十进制 |
二进制 |
八进制 |
十六进制 |
|
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
|
2 |
10 |
2 |
2 |
|
3 |
11 |
3 |
3 |
|
4 |
100 |
4 |
4 |
|
5 |
101 |
5 |
5 |
|
6 |
110 |
6 |
6 |
|
7 |
111 |
7 |
7 |
|
8 |
1000 |
10 |
8 |
|
9 |
1001 |
11 |
9 |
|
10 |
1010 |
12 |
A |
|
11 |
1011 |
13 |
B |
|
12 |
1100 |
14 |
C |
|
13 |
1101 |
15 |
D |
|
14 |
1110 |
16 |
E |
|
15 |
1111 |
17 |
F |
|
16 |
10000 |
20 |
10 |
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”。
当前的计算机系统使用的基本上是二进制系统,数据在计算机中主要是以补码的形式存储的。
|
术语 |
含义 |
|
bit(比特) |
一个二进制代表一位,一个位只能表示0或1两种状态。数据传输是习惯以“位”(bit)为单位。 |
|
Byte(字节) |
一个字节为8个二进制,称为8位,计算机中存储的最小单位是字节。数据存储是习惯以“字节”(Byte)为单位。 |
|
WORD(双字节) |
2个字节,16位 |
|
DWORD |
两个WORD,4个字节,32位 |
|
1b |
1bit,1位 |
|
1B |
1Byte,1字节,8位 |
|
1k,1K |
1024 |
|
1M(1兆) |
1024k, 1024*1024 |
|
1G |
1024M |
|
1T |
1024G |
|
1Kb(千位) |
1024bit,1024位 |
|
1KB(千字节) |
1024Byte,1024字节 |
|
1Mb(兆位) |
1024Kb = 1024 * 1024bit |
|
1MB(兆字节) |
1024KB = 1024 * 1024Byte |
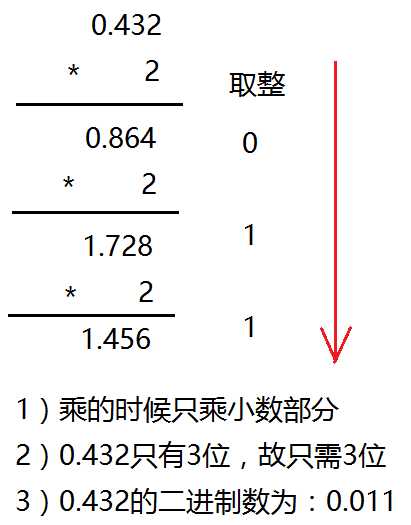
十进制转化二进制的方法:用十进制数除以2,分别取余数和商数,商数为0的时候,将余数倒着数就是转化后的结果。

十进制的小数转换成二进制:小数部分和2相乘,取整数,不足1取0,每次相乘都是小数部分,顺序看取整后的数就是转化后的结果。
八进制,Octal,缩写OCT或O,一种以8为基数的计数法,采用0,1,2,3,4,5,6,7八个数字,逢八进1。一些编程语言中常常以数字0开始表明该数字是八进制。
八进制的数和二进制数可以按位对应(八进制一位对应二进制三位),因此常应用在计算机语言中。
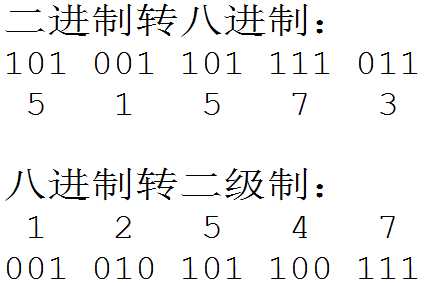
十进制转化八进制的方法:
用十进制数除以8,分别取余数和商数,商数为0的时候,将余数倒着数就是转化后的结果。

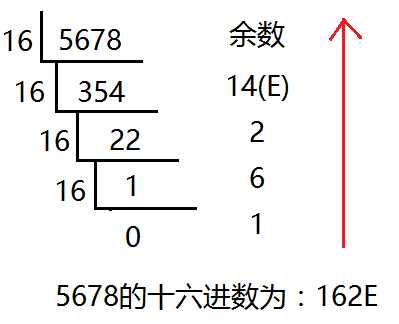
十六进制(英文名称:Hexadecimal),同我们日常生活中的表示法不一样,它由0-9,A-F组成,字母不区分大小写。与10进制的对应关系是:0-9对应0-9,A-F对应10-15。
十六进制的数和二进制数可以按位对应(十六进制一位对应二进制四位),因此常应用在计算机语言中。

十进制转化十六进制的方法:
用十进制数除以16,分别取余数和商数,商数为0的时候,将余数倒着数就是转化后的结果。
|
十进制 |
以正常数字1-9开头,如123 |
|
八进制 |
以数字0开头,如0123 |
|
十六进制 |
以0x开头,如0x123 |
|
二进制 |
C语言不能直接书写二进制数 |
#include <stdio.h>
int main(void)
{
int a = 123; //十进制方式赋值
int b = 0123; //八进制方式赋值, 以数字0开头
int c = 0xABC; //十六进制方式赋值
//如果在printf中输出一个十进制数那么用%d,八进制用%o,十六进制是%x
printf("十进制:%d\n",a );
printf("八进制:%o\n", b); //%o,为字母o,不是数字
printf("十六进制:%x\n", c);
return 0;
}
一个数的原码(原始的二进制码)有如下特点:
下面数值以1字节的大小描述:
|
十进制数 |
原码 |
|
+15 |
0000 1111 |
|
-15 |
1000 1111 |
|
+0 |
0000 0000 |
|
-0 |
1000 0000 |
原码表示法简单易懂,与带符号数本身转换方便,只要符号还原即可,但当两个正数相减或不同符号数相加时,必须比较两个数哪个绝对值大,才能决定谁减谁,才能确定结果是正还是负,所以原码不便于加减运算。
|
十进制数 |
反码 |
|
+15 |
0000 1111 |
|
-15 |
1111 0000 |
|
+0 |
0000 0000 |
|
-0 |
1111 1111 |
反码运算也不方便,通常用来作为求补码的中间过渡。
在计算机系统中,数值一律用补码来存储。
补码特点:
|
十进制数 |
补码 |
|
+15 |
0000 1111 |
|
-15 |
1111 0001 |
|
+0 |
0000 0000 |
|
-0 |
0000 0000 |
#include <stdio.h>
int main(void)
{
int a = -15;
printf("%x\n", a);
//结果为 fffffff1
//fffffff1对应的二进制:1111 1111 1111 1111 1111 1111 1111 0001
//符号位不变,其它取反:1000 0000 0000 0000 0000 0000 0000 1110
//上面加1:1000 0000 0000 0000 0000 0000 0000 1111 最高位1代表负数,就是-15
return 0;
}
示例1:用8位二进制数分别表示+0和-0
|
十进制数 |
原码 |
|
+0 |
0000 0000 |
|
-0 |
1000 0000 |
|
十进制数 |
反码 |
|
+0 |
0000 0000 |
|
-0 |
1111 1111 |
不管以原码方式存储,还是以反码方式存储,0也有两种表示形式。为什么同样一个0有两种不同的表示方法呢?
但是如果以补码方式存储,补码统一了零的编码:
|
十进制数 |
补码 |
|
+0 |
0000 0000 |
|
-0 |
10000 0000由于只用8位描述,最高位1丢弃,变为0000 0000 |
示例2:计算9-6的结果
以原码方式相加:
|
十进制数 |
原码 |
|
9 |
0000 1001 |
|
-6 |
1000 0110 |
结果为-15,不正确。
以补码方式相加:
|
十进制数 |
补码 |
|
9 |
0000 1001 |
|
-6 |
1111 1010 |
最高位的1溢出,剩余8位二进制表示的是3,正确。
在计算机系统中,数值一律用补码来存储,主要原因是:
#include <stdio.h>
int main()
{
int a;
int b = sizeof(a);//sizeof得到指定值占用内存的大小,单位:字节
printf("b = %d\n", b);
size_t c = sizeof(a);
printf("c = %u\n", c);//用无符号数的方式输出c的值
return 0;
}
|
打印格式 |
含义 |
|
%d |
输出一个有符号的10进制int类型 |
|
%o(字母o) |
输出8进制的int类型 |
|
%x |
输出16进制的int类型,字母以小写输出 |
|
%X |
输出16进制的int类型,字母以大写写输出 |
|
%u |
输出一个10进制的无符号数 |
#include <stdio.h>
int main()
{
int a = 123; //定义变量a,以10进制方式赋值为123
int b = 0567; //定义变量b,以8进制方式赋值为0567
int c = 0xabc; //定义变量c,以16进制方式赋值为0xabc
printf("a = %d\n", a);
printf("8进制:b = %o\n", b);
printf("10进制:b = %d\n", b);
printf("16进制:c = %x\n", c);
printf("16进制:c = %X\n", c);
printf("10进制:c = %d\n", c);
unsigned int d = 0xffffffff; //定义无符号int变量d,以16进制方式赋值
printf("有符号方式打印:d = %d\n", d);
printf("无符号方式打印:d = %u\n", d);
return 0;
}
#include <stdio.h>
int main()
{
int a;
printf("请输入a的值:");
//不要加“\n”
scanf("%d", &a);
printf("a = %d\n", a); //打印a的值
return 0;
}
|
数据类型 |
占用空间 |
|
short(短整型) |
2字节 |
|
int(整型) |
4字节 |
|
long(长整形) |
Windows为4字节,Linux为4字节(32位),8字节(64位) |
|
long long(长长整形) |
8字节 |
注意:
|
整型常量 |
所需类型 |
|
10 |
代表int类型 |
|
10l, 10L |
代表long类型 |
|
10ll, 10LL |
代表long long类型 |
|
10u, 10U |
代表unsigned int类型 |
|
10ul, 10UL |
代表unsigned long类型 |
|
10ull, 10ULL |
代表unsigned long long类型 |
|
打印格式 |
含义 |
|
%hd |
输出short类型 |
|
%d |
输出int类型 |
|
%l |
输出long类型 |
|
%ll |
输出long long类型 |
|
%hu |
输出unsigned short类型 |
|
%u |
输出unsigned int类型 |
|
%lu |
输出unsigned long类型 |
|
%llu |
输出unsigned long long类型 |
#include <stdio.h>
int main()
{
short a = 10;
int b = 10;
long c = 10l; //或者10L
long long d = 10ll; //或者10LL
printf("sizeof(a) = %u\n", sizeof(a));
printf("sizeof(b) = %u\n", sizeof(b));
printf("sizeof(c) = %u\n", sizeof(c));
printf("sizeof(c) = %u\n", sizeof(d));
printf("short a = %hd\n", a);
printf("int b = %d\n", b);
printf("long c = %ld\n", c);
printf("long long d = %lld\n", d);
unsigned short a2 = 20u;
unsigned int b2 = 20u;
unsigned long c2= 20ul;
unsigned long long d2 = 20ull;
printf("unsigned short a = %hu\n", a2);
printf("unsigned int b = %u\n", b2);
printf("unsigned long c = %lu\n", c2);
printf("unsigned long long d = %llu\n", d2);
return 0;
}
有符号数是最高位为符号位,0代表正数,1代表负数。

#include <stdio.h>
int main()
{
signed int a = -1089474374; //定义有符号整型变量a
printf("%X\n", a); //结果为 BF0FF0BA
//B F 0 F F 0 B A
//1011 1111 0000 1111 1111 0000 1011 1010
return 0;
}
无符号数最高位不是符号位,而就是数的一部分,无符号数不可能是负数。

#include <stdio.h>
int main()
{
unsigned int a = 3236958022; //定义无符号整型变量a
printf("%X\n", a); //结果为 C0F00F46
return 0;
}
当我们写程序要处理一个不可能出现负值的时候,一般用无符号数,这样可以增大数的表达最大值。
|
数据类型 |
占用空间 |
取值范围 |
|
short |
2字节 |
-32768 到 32767 (-215 ~ 215-1) |
|
int |
4字节 |
-2147483648 到 2147483647 (-231 ~ 231-1) |
|
long |
4字节 |
-2147483648 到 2147483647 (-231 ~ 231-1) |
|
unsigned short |
2字节 |
0 到 65535 (0 ~ 216-1) |
|
unsigned int |
4字节 |
0 到 4294967295 (0 ~ 232-1) |
|
unsigned long |
4字节 |
0 到 4294967295 (0 ~ 232-1) |
字符型变量用于存储一个单一字符,在 C 语言中用 char 表示,其中每个字符变量都会占用 1 个字节。在给字符型变量赋值时,需要用一对英文半角格式的单引号(‘ ‘)把字符括起来。
字符变量实际上并不是把该字符本身放到变量的内存单元中去,而是将该字符对应的 ASCII 编码放到变量的存储单元中。char的本质就是一个1字节大小的整型。
#include <stdio.h>
int main()
{
char ch = ‘a‘;
printf("sizeof(ch) = %u\n", sizeof(ch));
printf("ch[%%c] = %c\n", ch); //打印字符
printf("ch[%%d] = %d\n", ch); //打印‘a’ ASCII的值
char A = ‘A‘;
char a = ‘a‘;
printf("a = %d\n", a); //97
printf("A = %d\n", A); //65
printf("A = %c\n", ‘a‘ - 32); //小写a转大写A
printf("a = %c\n", ‘A‘ + 32); //大写A转小写a
ch = ‘ ‘;
printf("空字符:%d\n", ch); //空字符ASCII的值为32
printf("A = %c\n", ‘a‘ - ‘ ‘); //小写a转大写A
printf("a = %c\n", ‘A‘ + ‘ ‘); //大写A转小写a
return 0;
}
#include <stdio.h>
int main()
{
char ch;
printf("请输入ch的值:");
//不要加“\n”
scanf("%c", &ch);
printf("ch = %c\n", ch); //打印ch的字符
return 0;
}
|
ASCII值 |
控制字符 |
ASCII值 |
字符 |
ASCII值 |
字符 |
ASCII值 |
字符 |
|
0 |
NUT |
32 |
(space) |
64 |
@ |
96 |
、 |
|
1 |
SOH |
33 |
! |
65 |
A |
97 |
a |
|
2 |
STX |
34 |
" |
66 |
B |
98 |
b |
|
3 |
ETX |
35 |
# |
67 |
C |
99 |
c |
|
4 |
EOT |
36 |
$ |
68 |
D |
100 |
d |
|
5 |
ENQ |
37 |
% |
69 |
E |
101 |
e |
|
6 |
ACK |
38 |
& |
70 |
F |
102 |
f |
|
7 |
BEL |
39 |
, |
71 |
G |
103 |
g |
|
8 |
BS |
40 |
( |
72 |
H |
104 |
h |
|
9 |
HT |
41 |
) |
73 |
I |
105 |
i |
|
10 |
LF |
42 |
* |
74 |
J |
106 |
j |
|
11 |
VT |
43 |
+ |
75 |
K |
107 |
k |
|
12 |
FF |
44 |
, |
76 |
L |
108 |
l |
|
13 |
CR |
45 |
- |
77 |
M |
109 |
m |
|
14 |
SO |
46 |
. |
78 |
N |
110 |
n |
|
15 |
SI |
47 |
/ |
79 |
O |
111 |
o |
|
16 |
DLE |
48 |
0 |
80 |
P |
112 |
p |
|
17 |
DCI |
49 |
1 |
81 |
Q |
113 |
q |
|
18 |
DC2 |
50 |
2 |
82 |
R |
114 |
r |
|
19 |
DC3 |
51 |
3 |
83 |
S |
115 |
s |
|
20 |
DC4 |
52 |
4 |
84 |
T |
116 |
t |
|
21 |
NAK |
53 |
5 |
85 |
U |
117 |
u |
|
22 |
SYN |
54 |
6 |
86 |
V |
118 |
v |
|
23 |
TB |
55 |
7 |
87 |
W |
119 |
w |
|
24 |
CAN |
56 |
8 |
88 |
X |
120 |
x |
|
25 |
EM |
57 |
9 |
89 |
Y |
121 |
y |
|
26 |
SUB |
58 |
: |
90 |
Z |
122 |
z |
|
27 |
ESC |
59 |
; |
91 |
[ |
123 |
{ |
|
28 |
FS |
60 |
< |
92 |
/ |
124 |
| |
|
29 |
GS |
61 |
= |
93 |
] |
125 |
} |
|
30 |
RS |
62 |
> |
94 |
^ |
126 |
` |
|
31 |
US |
63 |
? |
95 |
_ |
127 |
DEL |
ASCII 码大致由以下两部分组成:
|
转义字符 |
含义 |
ASCII码值(十进制) |
|
\a |
警报 |
007 |
|
\b |
退格(BS) ,将当前位置移到前一列 |
008 |
|
\f |
换页(FF),将当前位置移到下页开头 |
012 |
|
\n |
换行(LF) ,将当前位置移到下一行开头 |
010 |
|
\r |
回车(CR) ,将当前位置移到本行开头 |
013 |
|
\t |
水平制表(HT) (跳到下一个TAB位置) |
009 |
|
\v |
垂直制表(VT) |
011 |
|
\\ |
代表一个反斜线字符"\" |
092 |
|
\‘ |
代表一个单引号(撇号)字符 |
039 |
|
\" |
代表一个双引号字符 |
034 |
|
\? |
代表一个问号 |
063 |
|
\0 |
数字0 |
000 |
|
\ddd |
8进制转义字符,d范围0~7 |
3位8进制 |
|
\xhh |
16进制转义字符,h范围0~9,a~f,A~F |
3位16进制 |
注意:红色字体标注的为不可打印字符。
#include <stdio.h>
int main()
{
printf("abc");
printf("\refg\n"); //\r切换到句首, \n为换行键
printf("abc");
printf("\befg\n");//\b为退格键, \n为换行键
printf("%d\n", ‘\123‘);// ‘\123‘为8进制转义字符,0123对应10进制数为83
printf("%d\n", ‘\x23‘);// ‘\x23‘为16进制转义字符,0x23对应10进制数为35
return 0;
}
当超过一个数据类型能够存放最大的范围时,数值会溢出。
有符号位最高位溢出的区别:符号位溢出会导致数的正负发生改变,但最高位的溢出会导致最高位丢失。
|
数据类型 |
占用空间 |
取值范围 |
|
char |
1字节 |
-128到 127(-27 ~ 27-1) |
|
unsigned char |
1字节 |
0 到 255(0 ~ 28-1) |
#include <stdio.h>
int main()
{
char ch;
//符号位溢出会导致数的正负发生改变
ch = 0x7f + 2; //127+2
printf("%d\n", ch);
// 0111 1111
//+2后 1000 0001,这是负数补码,其原码为 1111 1111,结果为-127
//最高位的溢出会导致最高位丢失
unsigned char ch2;
ch2 = 0xff+1; //255+1
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0000, char只有8位最高位的溢出,结果为0000 0000,十进制为0
ch2 = 0xff + 2; //255+1
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0001, char只有8位最高位的溢出,结果为0000 0001,十进制为1
return 0;
}
实型变量也可以称为浮点型变量,浮点型变量是用来存储小数数值的。在C语言中, 浮点型变量分为两种: 单精度浮点数(float)、 双精度浮点数(double), 但是double型变量所表示的浮点数比 float 型变量更精确。
|
数据类型 |
占用空间 |
有效数字范围 |
|
float |
4字节 |
7位有效数字 |
|
double |
8字节 |
15~16位有效数字 |
由于浮点型变量是由有限的存储单元组成的,因此只能提供有限的有效数字。在有效位以外的数字将被舍去,这样可能会产生一些误差。
不以f结尾的常量是double类型,以f结尾的常量(如3.14f)是float类型。
#include <stdio.h>
int main()
{
//传统方式赋值
float a = 3.14f; //或3.14F
double b = 3.14;
printf("a = %f\n", a);
printf("b = %lf\n", b);
//科学法赋值
a = 3.2e3f; //3.2*1000 = 32000,e可以写E
printf("a1 = %f\n", a);
a = 100e-3f; //100*0.001 = 0.1
printf("a2 = %f\n", a);
a = 3.1415926f;
printf("a3 = %f\n", a); //结果为3.141593
return 0;
}
|
限定符 |
含义 |
|
extern |
声明一个变量,extern声明的变量没有建立存储空间。 extern int a; |
|
const |
定义一个常量,常量的值不能修改。 const int a = 10; |
|
volatile |
防止编译器优化代码 |
|
register |
定义寄存器变量,提高效率。register是建议型的指令,而不是命令型的指令,如果CPU有空闲寄存器,那么register就生效,如果没有空闲寄存器,那么register无效。 |
字符串常量与字符常量的不同:
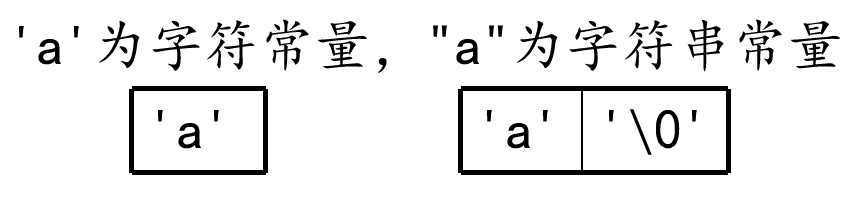
每个字符串的结尾,编译器会自动的添加一个结束标志位‘\0‘,即 "a" 包含两个字符‘a‘和’\0’。
printf是输出一个字符串,putchar输出一个char。
printf格式字符:
|
打印格式 |
对应数据类型 |
含义 |
|
%d |
int |
接受整数值并将它表示为有符号的十进制整数 |
|
%hd |
short int |
短整数 |
|
%hu |
unsigned short |
无符号短整数 |
|
%o |
unsigned int |
无符号8进制整数 |
|
%u |
unsigned int |
无符号10进制整数 |
|
%x,%X |
unsigned int |
无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF |
|
%f |
float |
单精度浮点数 |
|
%lf |
double |
双精度浮点数 |
|
%e,%E |
double |
科学计数法表示的数,此处"e"的大小写代表在输出时用的"e"的大小写 |
|
%c |
char |
字符型。可以把输入的数字按照ASCII码相应转换为对应的字符 |
|
%s |
char * |
字符串。输出字符串中的字符直至字符串中的空字符(字符串以‘\0‘结尾,这个‘\0‘即空字符) |
|
%p |
void * |
以16进制形式输出指针 |
|
%% |
% |
输出一个百分号 |
printf附加格式:
|
字符 |
含义 |
|
l(字母l) |
附加在d,u,x,o前面,表示长整数 |
|
- |
左对齐 |
|
m(代表一个整数) |
数据最小宽度 |
|
0(数字0) |
将输出的前面补上0直到占满指定列宽为止不可以搭配使用- |
|
m.n(代表一个整数) |
m指域宽,即对应的输出项在输出设备上所占的字符数。n指精度,用于说明输出的实型数的小数位数。对数值型的来说,未指定n时,隐含的精度为n=6位。 |
#include <stdio.h>
int main()
{
int a = 100;
printf("a = %d\n", a);//格式化输出一个字符串
printf("%p\n", &a);//输出变量a在内存中的地址编号
printf("%%d\n");
char c = ‘a‘;
putchar(c);//putchar只有一个参数,就是要输出的char
long a2 = 100;
printf("%ld, %lx, %lo\n", a2, a2, a2);
long long a3 = 1000;
printf("%lld, %llx, %llo\n", a3, a3, a3);
int abc = 10;
printf("abc = ‘%6d‘\n", abc);
printf("abc = ‘%-6d‘\n", abc);
printf("abc = ‘%06d‘\n", abc);
printf("abc = ‘%-06d‘\n", abc);
double d = 12.3;
printf("d = \‘ %-10.3lf \‘\n", d);
return 0;
}
#include <stdio.h>
int main()
{
char ch1;
char ch2;
char ch3;
int a;
int b;
printf("请输入ch1的字符:");
ch1 = getchar();
printf("ch1 = %c\n", ch1);
getchar(); //测试此处getchar()的作用
printf("请输入ch2的字符:");
ch2 = getchar();
printf("\‘ch2 = %ctest\‘\n", ch2);
getchar(); //测试此处getchar()的作用
printf("请输入ch3的字符:");
scanf("%c", &ch3);//这里第二个参数一定是变量的地址,而不是变量名
printf("ch3 = %c\n", ch3);
printf("请输入a的值:");
scanf("%d", &a);
printf("a = %d\n", a);
printf("请输入b的值:");
scanf("%d", &b);
printf("b = %d\n", b);
return 0;
}
|
运算符类型 |
作用 |
|
算术运算符 |
用于处理四则运算 |
|
赋值运算符 |
用于将表达式的值赋给变量 |
|
比较运算符 |
用于表达式的比较,并返回一个真值或假值 |
|
逻辑运算符 |
用于根据表达式的值返回真值或假值 |
|
位运算符 |
用于处理数据的位运算 |
|
sizeof运算符 |
用于求字节数长度 |
|
运算符 |
术语 |
示例 |
结果 |
|
+ |
正号 |
+3 |
3 |
|
- |
负号 |
-3 |
-3 |
|
+ |
加 |
10 + 5 |
15 |
|
- |
减 |
10 - 5 |
5 |
|
* |
乘 |
10 * 5 |
50 |
|
/ |
除 |
10 / 5 |
2 |
|
% |
取模(取余) |
10 % 3 |
1 |
|
++ |
前自增 |
a=2; b=++a; |
a=3; b=3; |
|
++ |
后自增 |
a=2; b=a++; |
a=3; b=2; |
|
-- |
前自减 |
a=2; b=--a; |
a=1; b=1; |
|
-- |
后自减 |
a=2; b=a--; |
a=1; b=2; |
|
运算符 |
术语 |
示例 |
结果 |
|
= |
赋值 |
a=2; b=3; |
a=2; b=3; |
|
+= |
加等于 |
a=0; a+=2; |
a=2; |
|
-= |
减等于 |
a=5; a-=3; |
a=2; |
|
*= |
乘等于 |
a=2; a*=2; |
a=4; |
|
/= |
除等于 |
a=4; a/=2; |
a=2; |
|
%= |
模等于 |
a=3; a%2; |
a=1; |
C 语言的比较运算中, “真”用数字“1”来表示, “假”用数字“0”来表示。
|
运算符 |
术语 |
示例 |
结果 |
|
== |
相等于 |
4 == 3 |
0 |
|
!= |
不等于 |
4 != 3 |
1 |
|
< |
小于 |
4 < 3 |
0 |
|
> |
大于 |
4 > 3 |
1 |
|
<= |
小于等于 |
4 <= 3 |
0 |
|
>= |
大于等于 |
4 >= 1 |
1 |
|
运算符 |
术语 |
示例 |
结果 |
|
! |
非 |
!a |
如果a为假,则!a为真; 如果a为真,则!a为假。 |
|
&& |
与 |
a && b |
如果a和b都为真,则结果为真,否则为假。 |
|
|| |
或 |
a || b |
如果a和b有一个为真,则结果为真,二者都为假时,结果为假。 |
|
优先级 |
运算符 |
名称或含义 |
使用形式 |
结合方向 |
说明 |
|
1 |
[] |
数组下标 |
数组名[常量表达式] |
左到右 |
-- |
|
() |
圆括号 |
(表达式)/函数名(形参表) |
-- |
||
|
. |
成员选择(对象) |
对象.成员名 |
-- |
||
|
-> |
成员选择(指针) |
对象指针->成员名 |
-- |
||
|
|
|||||
|
2 |
- |
负号运算符 |
-表达式 |
右到左 |
单目运算符 |
|
~ |
按位取反运算符 |
~表达式 |
|||
|
++ |
自增运算符 |
++变量名/变量名++ |
|||
|
-- |
自减运算符 |
--变量名/变量名-- |
|||
|
* |
取值运算符 |
*指针变量 |
|||
|
& |
取地址运算符 |
&变量名 |
|||
|
! |
逻辑非运算符 |
!表达式 |
|||
|
(类型) |
强制类型转换 |
(数据类型)表达式 |
-- |
||
|
sizeof |
长度运算符 |
sizeof(表达式) |
-- |
||
|
|
|||||
|
3 |
/ |
除 |
表达式/表达式 |
左到右 |
双目运算符 |
|
* |
乘 |
表达式*表达式 |
|||
|
% |
余数(取模) |
整型表达式%整型表达式 |
|||
|
4 |
+ |
加 |
表达式+表达式 |
左到右 |
双目运算符 |
|
- |
减 |
表达式-表达式 |
|||
|
5 |
<< |
左移 |
变量<<表达式 |
左到右 |
双目运算符 |
|
>> |
右移 |
变量>>表达式 |
|||
|
|
|||||
|
6 |
> |
大于 |
表达式>表达式 |
左到右 |
双目运算符 |
|
>= |
大于等于 |
表达式>=表达式 |
|||
|
< |
小于 |
表达式<表达式 |
|||
|
<= |
小于等于 |
表达式<=表达式 |
|||
|
7 |
== |
等于 |
表达式==表达式 |
左到右 |
双目运算符 |
|
!= |
不等于 |
表达式!= 表达式 |
|||
|
|
|||||
|
8 |
& |
按位与 |
表达式&表达式 |
左到右 |
双目运算符 |
|
9 |
^ |
按位异或 |
表达式^表达式 |
左到右 |
双目运算符 |
|
10 |
| |
按位或 |
表达式|表达式 |
左到右 |
双目运算符 |
|
11 |
&& |
逻辑与 |
表达式&&表达式 |
左到右 |
双目运算符 |
|
12 |
|| |
逻辑或 |
表达式||表达式 |
左到右 |
双目运算符 |
|
|
|||||
|
13 |
?: |
条件运算符 |
表达式1? 表达式2: 表达式3 |
右到左 |
三目运算符 |
|
|
|||||
|
14 |
= |
赋值运算符 |
变量=表达式 |
右到左 |
-- |
|
/= |
除后赋值 |
变量/=表达式 |
-- |
||
|
*= |
乘后赋值 |
变量*=表达式 |
-- |
||
|
%= |
取模后赋值 |
变量%=表达式 |
-- |
||
|
+= |
加后赋值 |
变量+=表达式 |
-- |
||
|
-= |
减后赋值 |
变量-=表达式 |
-- |
||
|
<<= |
左移后赋值 |
变量<<=表达式 |
-- |
||
|
>>= |
右移后赋值 |
变量>>=表达式 |
-- |
||
|
&= |
按位与后赋值 |
变量&=表达式 |
-- |
||
|
^= |
按位异或后赋值 |
变量^=表达式 |
-- |
||
|
|= |
按位或后赋值 |
变量|=表达式 |
-- |
||
|
|
|||||
|
15 |
, |
逗号运算符 |
表达式,表达式,… |
左到右 |
-- |
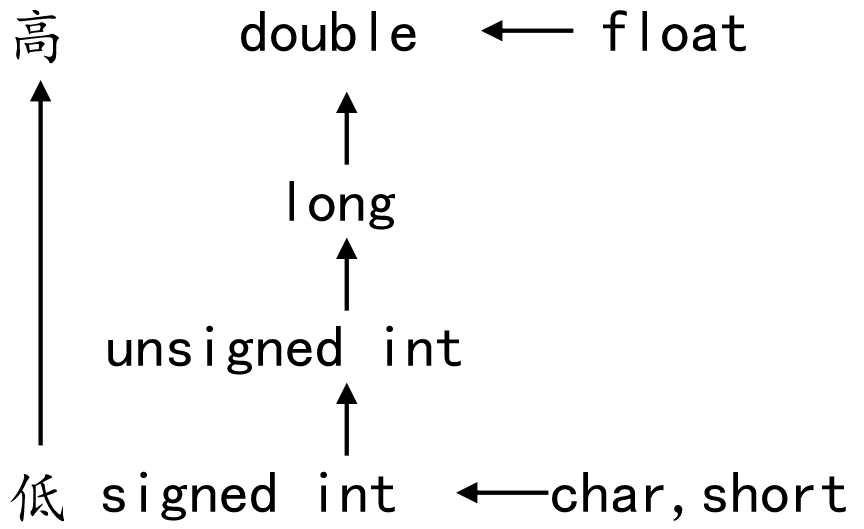
数据有不同的类型,不同类型数据之间进行混合运算时必然涉及到类型的转换问题。
转换的方法有两种:
类型转换的原则:占用内存字节数少(值域小)的类型,向占用内存字节数多(值域大)的类型转换,以保证精度不降低。
#include <stdio.h>
int main()
{
int num = 5;
printf("s1=%d\n", num / 2);
printf("s2=%lf\n", num / 2.0);
return 0;
}
强制类型转换指的是使用强制类型转换运算符,将一个变量或表达式转化成所需的类型,其基本语法格式如下所示:
(类型说明符) (表达式)
#include <stdio.h>
int main()
{
float x = 0;
int i = 0;
x = 3.6f;
i = x; //x为实型, i为整型,直接赋值会有警告
i = (int)x; //使用强制类型转换
printf("x=%f, i=%d\n", x, i);
return 0;
}
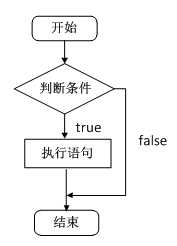
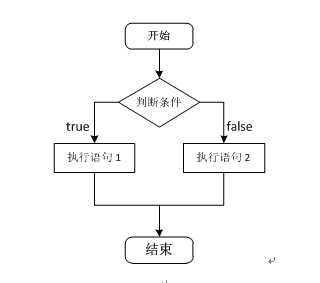
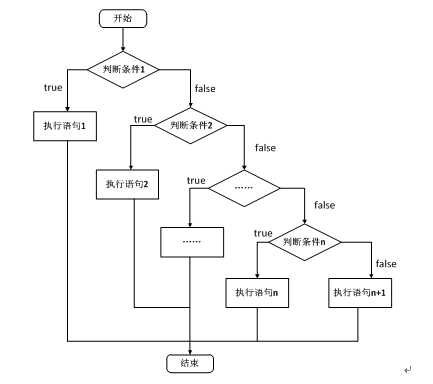
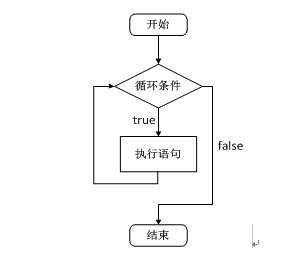
C语言支持最基本的三种程序运行结构:顺序结构、选择结构、循环结构。
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
if (a > b)
{
printf("%d\n", a);
}
return 0;
}
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
if (a > b)
{
printf("%d\n", a);
}
else
{
printf("%d\n", b);
}
return 0;
}
#include <stdio.h>
int main()
{
unsigned int a;
scanf("%u", &a);
if (a < 10)
{
printf("个位\n");
}
else if (a < 100)
{
printf("十位\n");
}
else if (a < 1000)
{
printf("百位\n");
}
else
{
printf("很大\n");
}
return 0;
}
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
int c;
if (a > b)
{
c = a;
}
else
{
c = b;
}
printf("c1 = %d\n", c);
a = 1;
b = 2;
c = ( a > b ? a : b );
printf("c2 = %d\n", c);
return 0;
}
#include <stdio.h>
int main()
{
char c;
c = getchar();
switch (c) //参数只能是整型变量
{
case ‘1‘:
printf("OK\n");
break;//switch遇到break就中断了
case ‘2‘:
printf("not OK\n");
break;
default://如果上面的条件都不满足,那么执行default
printf("are u ok?\n");
}
return 0;
}
#include <stdio.h>
int main()
{
int a = 20;
while (a > 10)
{
scanf("%d", &a);
printf("a = %d\n", a);
}
return 0;
}
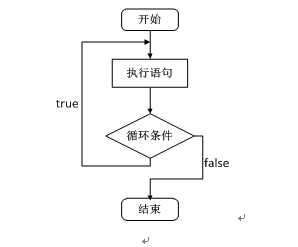
#include <stdio.h>
int main()
{
int a = 1;
do
{
a++;
printf("a = %d\n", a);
} while (a < 10);
return 0;
}
#include <stdio.h>
int main()
{
int i;
int sum = 0;
for (i = 0; i <= 100; i++)
{
sum += i;
}
printf("sum = %d\n", sum);
return 0;
}
循环语句之间可以相互嵌套:
#include <stdio.h>
int main(void)
{
int num = 0;
int i, j, k;
for (i = 0; i < 10; i++)
{
for (j = 0; j < 10; j++)
{
for (k = 0; k < 10; k++)
{
printf("hello world\n");
num++;
}
}
}
printf("num = %d\n", num);
return 0;
}
在switch条件语句和循环语句中都可以使用break语句:
#include <stdio.h>
int main()
{
int i = 0;
while (1)
{
i++;
printf("i = %d\n", i);
if (i == 10)
{
break; //跳出while循环
}
}
int flag = 0;
int m = 0;
int n = 0;
for (m = 0; m < 10; m++)
{
for (n = 0; n < 10; n++)
{
if (n == 5)
{
flag = 1;
break; //跳出for (n = 0; n < 10; n++)
}
}
if (flag == 1)
{
break; //跳出for (m = 0; m < 10; m++)
}
}
return 0;
}
在循环语句中,如果希望立即终止本次循环,并执行下一次循环,此时就需要使用continue语句。
#include<stdio.h>
int main()
{
int sum = 0; //定义变量sum
for (int i = 1; i <= 100; i++)
{
if (i % 2 == 0) //如果i是一个偶数,执行if语句中的代码
{
continue; //结束本次循环
}
sum += i; //实现sum和i的累加
}
printf("sum = %d\n", sum);
return 0;
}
#include <stdio.h>
int main()
{
goto End; //无条件跳转到End的标识
printf("aaaaaaaaa\n");
End:
printf("bbbbbbbb\n");
return 0;
}
在程序设计中,为了方便处理数据把具有相同类型的若干变量按有序形式组织起来——称为数组。
数组就是在内存中连续的相同类型的变量空间。同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中的地址是连续的。
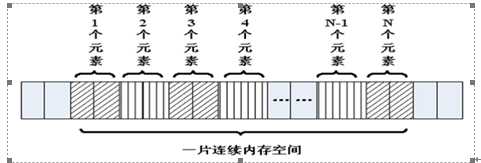
数组属于构造数据类型:
l 一个数组可以分解为多个数组元素:这些数组元素可以是基本数据类型或构造类型。
int a[10]; struct Stu boy[10];
l 按数组元素类型的不同,数组可分为:数值数组、字符数组、指针数组、结构数组等类别。
int a[10];
char s[10];
char *p[10];
通常情况下,数组元素下标的个数也称为维数,根据维数的不同,可将数组分为一维数组、二维数组、三维数组、四维数组等。通常情况下,我们将二维及以上的数组称为多维数组。
#include <stdio.h>
int main(void)
{
int a[10];//定义了一个数组,名字叫a,有10个成员,每个成员都是int类型
//a[0]…… a[9],没有a[10]
//没有a这个变量,a是数组的名字,但不是变量名,它是常量
a[0] = 0;
//……
a[9] = 9;
int i = 0;
for (i = 0; i < 10; i++)
{
a[i] = i; //给数组赋值
}
//遍历数组,并输出每个成员的值
for (i = 0; i < 10; i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
在定义数组的同时进行赋值,称为初始化。全局数组若不初始化,编译器将其初始化为零。局部数组若不初始化,内容为随机值。
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };//定义一个数组,同时初始化所有成员变量
int a[10] = { 1, 2, 3 };//初始化前三个成员,后面所有元素都设置为0
int a[10] = { 0 };//所有的成员都设置为0
//[]中不定义元素个数,定义时必须初始化
int a[] = { 1, 2, 3, 4, 5 };//定义了一个数组,有5个成员
数组名是一个地址的常量,代表数组中首元素的地址。
#include <stdio.h>
int main()
{
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };//定义一个数组,同时初始化所有成员变量
printf("a = %p\n", a);
printf("&a[0] = %p\n", &a[0]);
int n = sizeof(a); //数组占用内存的大小,10个int类型,10 * 4 = 40
int n0 = sizeof(a[0]);//数组第0个元素占用内存大小,第0个元素为int,4
int i = 0;
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
#include <stdio.h>
int main()
{
int a[] = { 1, -2, 3,- 4, 5, -6, 7, -8, -9, 10 };//定义一个数组,同时初始化所有成员变量
int i = 0;
int max = a[0];
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
if (a[i] > max)
{
max = a[i];
}
}
printf("数组中最大值为:%d\n", max);
return 0;
}
#include <stdio.h>
int main()
{
int a[] = { 1, -2, 3,- 4, 5, -6, 7, -8, -9, 10 };//定义一个数组,同时初始化所有成员变量
int i = 0;
int j = sizeof(a) / sizeof(a[0]) -1;
int tmp;
while (i < j)
{
tmp = a[i];
a[i] = a[j];
a[j] = tmp;
i++;
j--;
}
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
#include <stdio.h>
int main()
{
int a[] = { 1, -2, 3,- 4, 5, -6, 7, -8, -9, 10 };//定义一个数组,同时初始化所有成员变量
int i = 0;
int j = 0;
int n = sizeof(a) / sizeof(a[0]);
int tmp;
//1、流程
//2、试数
for (i = 0; i < n-1; i++)
{
for (j = 0; j < n - i -1 ; j++)//内循环的目的是比较相邻的元素,把大的放到后面
{
if (a[j] > a[j + 1])
{
tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
}
}
}
for (i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
二维数组定义的一般形式是:
类型说明符 数组名[常量表达式1][常量表达式2]
其中常量表达式1表示第一维下标的长度,常量表达式2 表示第二维下标的长度。
int a[3][4];
#include <stdio.h>
int main()
{
//定义了一个二维数组,名字叫a
//由3个一维数组组成,这个一维数组是int [4]
//这3个一维数组的数组名分别为a[0],a[1],a[2]
int a[3][4];
a[0][0] = 0;
//……
a[2][3] = 12;
//给数组每个元素赋值
int i = 0;
int j = 0;
int num = 0;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 4; j++)
{
a[i][j] = num++;
}
}
//遍历数组,并输出每个成员的值
for (i = 0; i < 3; i++)
{
for (j = 0; j < 4; j++)
{
printf("%d, ", a[i][j]);
}
printf("\n");
}
return 0;
}
//分段赋值 int a[3][4] = {{ 1, 2, 3, 4 },{ 5, 6, 7, 8, },{ 9, 10, 11, 12 }};
int a[3][4] =
{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8, },
{ 9, 10, 11, 12 }
};
//连续赋值
int a[3][4] = { 1, 2, 3, 4 , 5, 6, 7, 8, 9, 10, 11, 12 };
//可以只给部分元素赋初值,未初始化则为0
int a[3][4] = { 1, 2, 3, 4 };
//所有的成员都设置为0
int a[3][4] = {0};
//[]中不定义元素个数,定义时必须初始化
int a[][4] = { 1, 2, 3, 4, 5, 6, 7, 8};
数组名是一个地址的常量,代表数组中首元素的地址。
#include <stdio.h>
int main()
{
//定义了一个二维数组,名字叫a
//二维数组是本质上还是一维数组,此一维数组有3个元素
//每个元素又是一个一维数组int[4]
int a[3][4] = { 1, 2, 3, 4 , 5, 6, 7, 8, 9, 10, 11, 12 };
//数组名为数组首元素地址,二维数组的第0个元素为一维数组
//第0个一维数组的数组名为a[0]
printf("a = %p\n", a);
printf("a[0] = %p\n", a[0]);
//测二维数组所占内存空间,有3个一维数组,每个一维数组的空间为4*4
//sizeof(a) = 3 * 4 * 4 = 48
printf("sizeof(a) = %d\n", sizeof(a));
//测第0个元素所占内存空间,a[0]为第0个一维数组int[4]的数组名,4*4=16
printf("sizeof(a[0]) = %d\n", sizeof(a[0]) );
//测第0行0列元素所占内存空间,第0行0列元素为一个int类型,4字节
printf("sizeof(a[0][0]) = %d\n", sizeof(a[0][0]));
//求二维数组行数
printf("i = %d\n", sizeof(a) / sizeof(a[0]));
// 求二维数组列数
printf("j = %d\n", sizeof(a[0]) / sizeof(a[0][0]));
//求二维数组行*列总数
printf("n = %d\n", sizeof(a) / sizeof(a[0][0]));
return 0;
}
#include <stdio.h>
int main(void)
{
//二维数组: 五行、三列
//行代表人: 老大到老五
//列代表科目:语、数、外
float a[5][3] = { { 80, 75, 56 }, { 59, 65, 71 }, { 59, 63, 70 }, { 85, 45, 90 }, { 76, 77, 45 } };
int i, j, person_low[3] = { 0 };
float s = 0, lesson_aver[3] = { 0 };
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
s = s + a[j][i];
if (a[j][i] < 60)
{
person_low[i]++;
}
}
lesson_aver[i] = s / 5;
s = 0;
}
printf("各科的平均成绩:\n");
for (i = 0; i < 3; i++)
{
printf("%.2f\n", lesson_aver[i]);
}
printf("各科不及格的人数:\n");
for (i = 0; i < 3; i++)
{
printf("%d\n", person_low[i]);
}
return 0;
}
多维数组的定义与二维数组类似,其语法格式具体如下:
数组类型修饰符 数组名 [n1][n2]…[nn]; int a[3][4][5];
定义了一个三维数组,数组的名字是a,数组的长度为3,每个数组的元素又是一个二维数组,这个二维数组的长度是4,并且这个二维数组中的每个元素又是一个一维数组,这个一维数组的长度是5,元素类型是int。
#include <stdio.h>
int main(void)
{
//int a[3][4][5] ;//定义了一个三维数组,有3个二维数组int[4][5]
int a[3][4][5] = { { { 1, 2, 3, 4, 5 }, { 6, 7, 8, 9, 10 }, { 0 }, { 0 } }, { { 0 }, { 0 }, { 0 }, { 0 } }, { { 0 }, { 0 }, { 0 }, { 0 } } };
int i, j, k;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 4; j++)
{
for (k = 0; k < 5; k++)
{
//添加访问元素代码
printf("%d, ", a[i][j][k]);
}
printf("\n");
}
}
return 0;
}
#include <stdio.h>
int main(void)
{
char c1[] = { ‘c‘, ‘ ‘, ‘p‘, ‘r‘, ‘o‘, ‘g‘ }; //普通字符数组
printf("c1 = %s\n", c1); //乱码,因为没有’\0’结束符
//以‘\0’(‘\0’就是数字0)结尾的字符数组是字符串
char c2[] = { ‘c‘, ‘ ‘, ‘p‘, ‘r‘, ‘o‘, ‘g‘, ‘\0‘};
printf("c2 = %s\n", c2);
//字符串处理以‘\0’(数字0)作为结束符,后面的‘h‘, ‘l‘, ‘l‘, ‘e‘, ‘o‘不会输出
char c3[] = { ‘c‘, ‘ ‘, ‘p‘, ‘r‘, ‘o‘, ‘g‘, ‘\0‘, ‘h‘, ‘l‘, ‘l‘, ‘e‘, ‘o‘, ‘\0‘};
printf("c3 = %s\n", c3);
return 0;
}
#include <stdio.h>
// C语言没有字符串类型,通过字符数组模拟
// C语言字符串,以字符‘\0’, 数字0
int main(void)
{
//不指定长度, 没有0结束符,有多少个元素就有多长
char buf[] = { ‘a‘, ‘b‘, ‘c‘ };
printf("buf = %s\n", buf); //乱码
//指定长度,后面没有赋值的元素,自动补0
char buf2[100] = { ‘a‘, ‘b‘, ‘c‘ };
printf("buf2 = %s\n", buf2);
//所有元素赋值为0
char buf3[100] = { 0 };
//char buf4[2] = { ‘1‘, ‘2‘, ‘3‘ };//数组越界
char buf5[50] = { ‘1‘, ‘a‘, ‘b‘, ‘0‘, ‘7‘ };
printf("buf5 = %s\n", buf5);
char buf6[50] = { ‘1‘, ‘a‘, ‘b‘, 0, ‘7‘ };
printf("buf6 = %s\n", buf6);
char buf7[50] = { ‘1‘, ‘a‘, ‘b‘, ‘\0‘, ‘7‘ };
printf("buf7 = %s\n", buf7);
//使用字符串初始化,编译器自动在后面补0,常用
char buf8[] = "agjdslgjlsdjg";
//‘\0‘后面最好不要连着数字,有可能几个数字连起来刚好是一个转义字符
//‘\ddd‘八进制字义字符,‘\xdd‘十六进制转移字符
// \012相当于\n
char str[] = "\012abc";
printf("str == %s\n", str);
return 0;
}
由于字符串采用了‘\0‘标志,字符串的输入输出将变得简单方便。
#include <stdio.h>
int main(void)
{
char str[100];
printf("input string1 : \n");
scanf("%s", str);//scanf(“%s”,str)默认以空格分隔
printf("output:%s\n", str);
return 0;
}
#include <stdio.h>
int main(void)
{
char str1[] = "abcdef";
char str2[] = "123456";
char dst[100];
int i = 0;
while (str1[i] != 0)
{
dst[i] = str1[i];
i++;
}
int j = 0;
while (str2[j] != 0)
{
dst[i + j] = str2[j];
j++;
}
dst[i + j] = 0; //字符串结束符
printf("dst = %s\n", dst);
return 0;
}
当调用函数时,需要关心5要素:
#include <time.h>
time_ttime(time_t *t);
功能:获取当前系统时间
参数:常设置为NULL
返回值:当前系统时间, time_t 相当于long类型,单位为毫秒
#include <stdlib.h>
voidsrand(unsignedintseed);
功能:用来设置rand()产生随机数时的随机种子
参数:如果每次seed相等,rand()产生随机数相等
返回值:无
#include <stdlib.h>
intrand(void);
功能:返回一个随机数值
参数:无
返回值:随机数
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int main()
{
time_t tm = time(NULL);//得到系统时间
srand((unsigned int)tm);//随机种子只需要设置一次即可
int r = rand();
printf("r = %d\n", r);
return 0;
}
#include <stdio.h>
char *gets(char *s);
功能:从标准输入读入字符,并保存到s指定的内存空间,直到出现换行符或读到文件结尾为止。
参数:
s:字符串首地址
返回值:
成功:读入的字符串
失败:NULL
gets(str)与scanf(“%s”,str)的区别:
(1)gets(str)允许输入的字符串含有空格
(2)scanf(“%s”,str)不允许含有空格
注意:由于scanf()和gets()无法知道字符串s大小,必须遇到换行符或读到文件结尾为止才接收输入,因此容易导致字符数组越界(缓冲区溢出)的情况。
char str[100];
printf("请输入str: ");
gets(str);
printf("str = %s\n", str);
#include <stdio.h>
char *fgets(char *s, intsize, FILE *stream);
功能:从stream指定的文件内读入字符,保存到s所指定的内存空间,直到出现换行字符、读到文件结尾或是已读了size - 1个字符为止,最后会自动加上字符 ‘\0‘ 作为字符串结束。
参数:
s:字符串
size:指定最大读取字符串的长度(size - 1)
stream:文件指针,如果读键盘输入的字符串,固定写为stdin
返回值:
成功:成功读取的字符串
读到文件尾或出错: NULL
fgets()在读取一个用户通过键盘输入的字符串的时候,同时把用户输入的回车也做为字符串的一部分。通过scanf和gets输入一个字符串的时候,不包含结尾的“\n”,但通过fgets结尾多了“\n”。fgets()函数是安全的,不存在缓冲区溢出的问题。
char str[100];
printf("请输入str: ");
fgets(str, sizeof(str), stdin);
printf("str = \"%s\"\n", str);
#include <stdio.h>
intputs(constchar *s);
功能:标准设备输出s字符串,在输出完成后自动输出一个‘\n‘。
参数:
s:字符串首地址
返回值:
成功:非负数
失败:-1
#include <stdio.h>
int main()
{
printf("hello world");
puts("hello world");
return 0;
}
#include <stdio.h>
int fputs(constchar * str, FILE * stream);
功能:将str所指定的字符串写入到stream指定的文件中, 字符串结束符 ‘\0‘ 不写入文件。
参数:
str:字符串
stream:文件指针,如果把字符串输出到屏幕,固定写为stdout
返回值:
成功:0
失败:-1
fputs()是puts()的文件操作版本,但fputs()不会自动输出一个‘\n‘。
printf("hello world");
puts("hello world");
fputs("hello world", stdout);
#include <string.h>
size_tstrlen(constchar *s);
功能:计算指定指定字符串s的长度,不包含字符串结束符‘\0’
参数:
s:字符串首地址
返回值:字符串s的长度,size_t为unsigned int类型
char str[] = "abcdefg";
int n = strlen(str);
printf("n = %d\n", n);
#include <string.h>
char *strcpy(char *dest, constchar *src);
功能:把src所指向的字符串复制到dest所指向的空间中,‘\0‘也会拷贝过去
参数:
dest:目的字符串首地址
src:源字符首地址
返回值:
成功:返回dest字符串的首地址
失败:NULL
注意:如果参数dest所指的内存空间不够大,可能会造成缓冲溢出的错误情况。
char dest[20] = "123456789";
char src[] = "hello world";
strcpy(dest, src);
printf("%s\n", dest);
#include <string.h>
char *strncpy(char *dest, constchar *src, size_tn);
功能:把src指向字符串的前n个字符复制到dest所指向的空间中,是否拷贝结束符看指定的长度是否包含‘\0‘。
参数:
dest:目的字符串首地址
src:源字符首地址
n:指定需要拷贝字符串个数
返回值:
成功:返回dest字符串的首地址
失败:NULL
char dest[20] ;
char src[] = "hello world";
strncpy(dest, src, 5);
printf("%s\n", dest);
dest[5] = ‘\0‘;
printf("%s\n", dest);
#include <string.h>
char *strcat(char *dest, constchar *src);
功能:将src字符串连接到dest的尾部,‘\0’也会追加过去
参数:
dest:目的字符串首地址
src:源字符首地址
返回值:
成功:返回dest字符串的首地址
失败:NULL
char str[20] = "123";
char *src = "hello world";
printf("%s\n", strcat(str, src));
#include <string.h>
char *strncat(char *dest, constchar *src, size_tn);
功能:将src字符串前n个字符连接到dest的尾部,‘\0’也会追加过去
参数:
dest:目的字符串首地址
src:源字符首地址
n:指定需要追加字符串个数
返回值:
成功:返回dest字符串的首地址
失败:NULL
char str[20] = "123";
char *src = "hello world";
printf("%s\n", strncat(str, src, 5));
#include <string.h>
intstrcmp(constchar *s1, constchar *s2);
功能:比较 s1 和 s2 的大小,比较的是字符ASCII码大小。
参数:
s1:字符串1首地址
s2:字符串2首地址
返回值:
相等:0
大于:>0
小于:<0
char *str1 = "hello world";
char *str2 = "hello mike";
if (strcmp(str1, str2) == 0)
{
printf("str1==str2\n");
}
else if (strcmp(str1, str2) > 0)
{
printf("str1>str2\n");
}
else
{
printf("str1<str2\n");
}
#include <string.h> intstrncmp(constchar *s1, constchar *s2, size_tn); 功能:比较 s1 和 s2 前n个字符的大小,比较的是字符ASCII码大小。
参数: s1:字符串1首地址 s2:字符串2首地址 n:指定比较字符串的数量 返回值: 相等:0 大于: > 0 小于: < 0 char *str1 = "hello world"; char *str2 = "hello mike"; if (strncmp(str1, str2, 5) == 0) { printf("str1==str2\n"); } else if (strcmp(str1, "hello world") > 0) { printf("str1>str2\n"); } else { printf("str1<str2\n"); }
#include <stdio.h>
intsprintf(char *_CRT_SECURE_NO_WARNINGS, constchar *format, ...);
功能:根据参数format字符串来转换并格式化数据,然后将结果输出到str指定的空间中,直到出现字符串结束符 ‘\0‘ 为止。
参数:
str:字符串首地址
format:字符串格式,用法和printf()一样
返回值:
成功:实际格式化的字符个数
失败: - 1
char dst[100] = { 0 };
int a = 10;
char src[] = "hello world";
printf("a = %d, src = %s", a, src);
printf("\n");
int len = sprintf(dst, "a = %d, src = %s", a, src);
printf("dst = \" %s\"\n", dst);
printf("len = %d\n", len);
#include <stdio.h>
intsscanf(constchar *str, constchar *format, ...);
功能:从str指定的字符串读取数据,并根据参数format字符串来转换并格式化数据。
参数:
str:指定的字符串首地址
format:字符串格式,用法和scanf()一样
返回值:
成功:参数数目,成功转换的值的个数
失败: - 1
char src[] = "a=10, b=20";
int a;
int b;
sscanf(src, "a=%d, b=%d", &a, &b);
printf("a:%d, b:%d\n", a, b);
#include <string.h>
char *strchr(const char *s, int c);
功能:在字符串s中查找字母c出现的位置
参数:
s:字符串首地址
c:匹配字母(字符)
返回值:
成功:返回第一次出现的c地址
失败:NULL
char src[] = "ddda123abcd";
char *p = strchr(src, ‘a‘);
printf("p = %s\n", p);
#include <string.h>
char *strstr(constchar *haystack, constchar *needle);
功能:在字符串haystack中查找字符串needle出现的位置
参数:
haystack:源字符串首地址
needle:匹配字符串首地址
返回值:
成功:返回第一次出现的needle地址
失败:NULL
char src[] = "ddddabcd123abcd333abcd";
char *p = strstr(src, "abcd");
printf("p = %s\n", p);
#include <string.h>
char *strtok(char *str, constchar *delim);
功能:来将字符串分割成一个个片段。当strtok()在参数s的字符串中发现参数delim中包含的分割字符时, 则会将该字符改为\0 字符,当连续出现多个时只替换第一个为\0。
参数:
str:指向欲分割的字符串
delim:为分割字符串中包含的所有字符
返回值:
成功:分割后字符串首地址
失败:NULL
// 在第一次调用时:strtok()必需给予参数s字符串
// 往后的调用则将参数s设置成NULL,每次调用成功则返回指向被分割出片段的指针
char a[100] = "adc*fvcv*ebcy*hghbdfg*casdert";
char *s = strtok(a, "*");//将"*"分割的子串取出
while (s != NULL)
{
printf("%s\n", s);
s = strtok(NULL, "*");
}
#include <stdlib.h>
intatoi(constchar *nptr);
功能:atoi()会扫描nptr字符串,跳过前面的空格字符,直到遇到数字或正负号才开始做转换,而遇到非数字或字符串结束符(‘\0‘)才结束转换,并将结果返回返回值。
参数:
nptr:待转换的字符串
返回值:
成功转换后整数
类似的函数有:
// atof():把一个小数形式的字符串转化为一个浮点数。
// atol():将一个字符串转化为long类型
char str1[] = "-10";
int num1 = atoi(str1);
printf("num1 = %d\n", num1);
char str2[] = "0.123";
double num2 = atof(str2);
printf("num2 = %lf\n", num2);
C 程序是由函数组成的,我们写的代码都是由主函数 main()开始执行的。函数是 C 程序的基本模块,是用于完成特定任务的程序代码单元。
从函数定义的角度看,函数可分为系统函数和用户定义函数两种:
6.1.2 函数的作用
// 1. 函数的使用可以省去重复代码的编写,降低代码重复率
// 求两数的最大值
int max(int a, int b)
{
if (a > b){
return a;
}
else{
return b;
}
}
int main()
{
// 操作1 ……
// ……
int a1 = 10, b1 = 20, c1 = 0;
c1 = max(a1, b1); // 调用max()
// 操作2 ……
// ……
int a2 = 11, b2 = 21, c2 = 0;
c2 = max(a2, b2); // 调用max()
// ……
return 0;
}
// 2. 函数可以让程序更加模块化,从而有利于程序的阅读,修改和完善
假如我们编写一个实现以下功能的程序:读入一行数字;对数字进行排序;找到它们的平均值;打印出一个柱状图。如果我们把这些操作直接写在main()里,这样可能会给用户感觉代码会有点凌乱。但,假如我们使用函数,这样可以让程序更加清晰、模块化:
#include <stdio.h>
int main()
{
float list[50];
// 这里只是举例,函数还没有实现
readlist(list, 50);
sort(list, 50);
average(list, 50);
bargraph(list, 50);
return 0;
}
这里我们可以这么理解,程序就像公司,公司是由部门组成的,这个部门就类似于C程序的函数。默认情况下,公司就是一个大部门( 只有一个部门的情况下 ),相当于C程序的main()函数。如果公司比较小( 程序比较小 ),因为任务少而简单,一个部门即可( main()函数 )胜任。但是,如果这个公司很大( 大型应用程序 ),任务多而杂,如果只是一个部门管理( 相当于没有部门,没有分工 ),我们可想而知,公司管理、运营起来会有多混乱,不是说这样不可以运营,只是这样不完美而已,如果根据公司要求分成一个个部门( 根据功能封装一个一个函数 ),招聘由行政部门负责,研发由技术部门负责等,这样就可以分工明确,结构清晰,方便管理,各部门之间还可以相互协调。
函数定义的一般形式:
返回类型 函数名(形式参数列表)
{
数据定义部分;
执行语句部分;
}
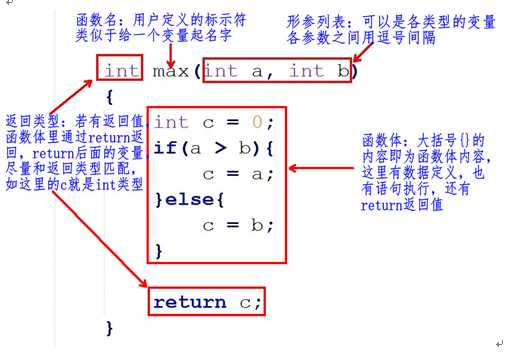
理论上是可以随意起名字,最好起的名字见名知意,应该让用户看到这个函数名字就知道这个函数的功能。注意,函数名的后面有个圆换号(),代表这个为函数,不是普通的变量名。
在定义函数时指定的形参,在未出现函数调用时,它们并不占内存中的存储单元,因此称它们是形式参数或虚拟参数,简称形参,表示它们并不是实际存在的数据,所以,形参里的变量不能赋值。
void max(int a = 10, int b = 20) // error, 形参不能赋值
{
}
在定义函数时指定的形参,必须是,类型+变量的形式:
//1: right, 类型+变量
void max(int a, int b)
{
}
//2: error, 只有类型,没有变量
void max(int, int)
{
}
//3: error, 只有变量,没有类型
int a, int b;
void max(a, b)
{
}
在定义函数时指定的形参,可有可无,根据函数的需要来设计,如果没有形参,圆括号内容为空,或写一个void关键字:
// 没形参, 圆括号内容为空
void max()
{
}
// 没形参, 圆括号内容为void关键字
void max(void)
{
}
花括号{ }里的内容即为函数体的内容,这里为函数功能实现的过程,这和以前的写代码没太大区别,以前我们把代码写在main()函数里,现在只是把这些写到别的函数里。
函数的返回值是通过函数中的return语句获得的,return后面的值也可以是一个表达式。
int max() // 函数的返回值为int类型
{
int a = 10;
return a;// 返回值a为int类型,函数返回类型也是int,匹配
}
double max() // 函数的返回值为double类型
{
int a = 10;
return a;// 返回值a为int类型,它会转为double类型再返回
}
注意:如果函数返回的类型和return语句中表达式的值不一致,而它又无法自动进行类型转换,程序则会报错。
c)return语句的另一个作用为中断return所在的执行函数,类似于break中断循环、switch语句一样。
int max()
{
return 1;// 执行到,函数已经被中断,所以下面的return 2无法被执行到
return 2;// 没有执行
}
d)如果函数带返回值,return后面必须跟着一个值,如果函数没有返回值,函数名字的前面必须写一个void关键字,这时候,我们写代码时也可以通过return中断函数(也可以不用),只是这时,return后面不带内容( 分号“;”除外)。
void max()// 最好要有void关键字
{
return; // 中断函数,这个可有可无
}
定义函数后,我们需要调用此函数才能执行到这个函数里的代码段。这和main()函数不一样,main()为编译器设定好自动调用的主函数,无需人为调用,我们都是在main()函数里调用别的函数,一个 C 程序里有且只有一个main()函数。
#include <stdio.h>
void print_test()
{
printf("this is for test\n");
}
int main()
{
print_test(); // print_test函数的调用
return 0;
}
1) 进入main()函数
2) 调用print_test()函数:
3) print_test()函数执行完( 这里打印一句话 ),main()才会继续往下执行,执行到return 0, 程序执行完毕。
如果是调用无参函数,则不能加上“实参”,但括号不能省略。
// 函数的定义
void test()
{
}
int main()
{
// 函数的调用
test(); // right, 圆括号()不能省略
test(250); // error, 函数定义时没有参数
return 0;
}
a)如果实参表列包含多个实参,则各参数间用逗号隔开。
// 函数的定义
void test(int a, int b)
{
}
int main()
{
int p = 10, q = 20;
test(p, q); // 函数的调用
return 0;
}
b)实参与形参的个数应相等,类型应匹配(相同或赋值兼容)。实参与形参按顺序对应,一对一地传递数据。

c)实参可以是常量、变量或表达式,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。所以,这里的变量是在圆括号( )外面定义好、赋好值的变量。
// 函数的定义
void test(int a, int b)
{
}
int main()
{
// 函数的调用
int p = 10, q = 20;
test(p, q); // right
test(11, 30 - 10); // right
test(int a, int b); // error, 不应该在圆括号里定义变量
return 0;
}
a)如果函数定义没有返回值,函数调用时不能写void关键字,调用函数时也不能接收函数的返回值。
// 函数的定义
void test()
{
}
int main()
{
// 函数的调用
test(); // right
void test(); // error, void关键字只能出现在定义,不可能出现在调用的地方
int a = test(); // error, 函数定义根本就没有返回值
return 0;
}
b)如果函数定义有返回值,这个返回值我们根据用户需要可用可不用,但是,假如我们需要使用这个函数返回值,我们需要定义一个匹配类型的变量来接收。
// 函数的定义, 返回值为int类型
int test()
{
}
int main()
{
// 函数的调用
int a = test(); // right, a为int类型
int b;
b = test(); // right, 和上面等级
char *p = test(); // 虽然调用成功没有意义, p为char *, 函数返回值为int, 类型不匹配
// error, 必须定义一个匹配类型的变量来接收返回值
// int只是类型,没有定义变量
int = test();
// error, 必须定义一个匹配类型的变量来接收返回值
// int只是类型,没有定义变量
int test();
return 0;
}
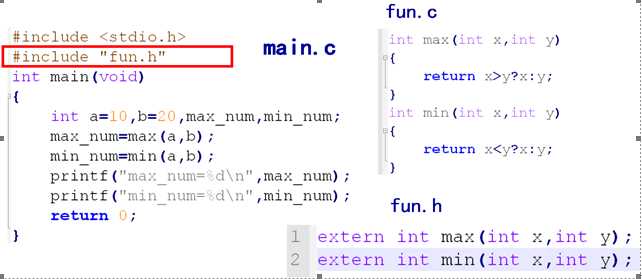
如果使用用户自己定义的函数,而该函数与调用它的函数(即主调函数)不在同一文件中,或者函数定义的位置在主调函数之后,则必须在调用此函数之前对被调用的函数作声明。
所谓函数声明,就是在函数尚在未定义的情况下,事先将该函数的有关信息通知编译系统,相当于告诉编译器,函数在后面定义,以便使编译能正常进行。
注意:一个函数只能被定义一次,但可以声明多次。
#include <stdio.h>
int max(int x, int y); // 函数的声明,分号不能省略
// int max(int, int); // 另一种方式
int main()
{
int a = 10, b = 25, num_max = 0;
num_max = max(a, b); // 函数的调用
printf("num_max = %d\n", num_max);
return 0;
}
// 函数的定义
int max(int x, int y)
{
return x > y ? x : y;
}
函数定义和声明的区别:
1)定义是指对函数功能的确立,包括指定函数名、函数类型、形参及其类型、函数体等,它是一个完整的、独立的函数单位。
2)声明的作用则是把函数的名字、函数类型以及形参的个数、类型和顺序(注意,不包括函数体)通知编译系统,以便在对包含函数调用的语句进行编译时,据此对其进行对照检查(例如函数名是否正确,实参与形参的类型和个数是否一致)。
在main函数中调用exit和return结果是一样的,但在子函数中调用return只是代表子函数终止了,在子函数中调用exit,那么程序终止。
#include <stdio.h>
#include <stdlib.h>
void fun()
{
printf("fun\n");
//return;
exit(0);
}
int main()
{
fun();
while (1);
return 0;
}
当一个项目比较大时,往往都是分文件,这时候有可能不小心把同一个头文件 include 多次,或者头文件嵌套包含。
a.h 中包含 b.h :
#include "b.h"
b.h 中包含 a.h:
#include "a.h"
main.c 中使用其中头文件:
#include "a.h"
int main()
{
return 0;
}
编译上面的例子,会出现如下错误:
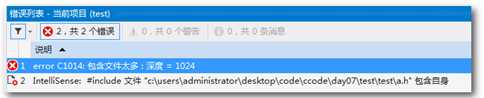
为了避免同一个文件被include多次,C/C++中有两种方式,一种是 #ifndef 方式,一种是 #pragma once 方式。
方法一:
#ifndef __SOMEFILE_H__ #define __SOMEFILE_H__ // 声明语句 #endif
方法二:
#pragma once // 声明语句
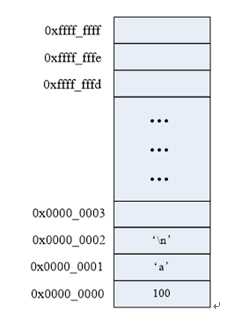
内存含义:
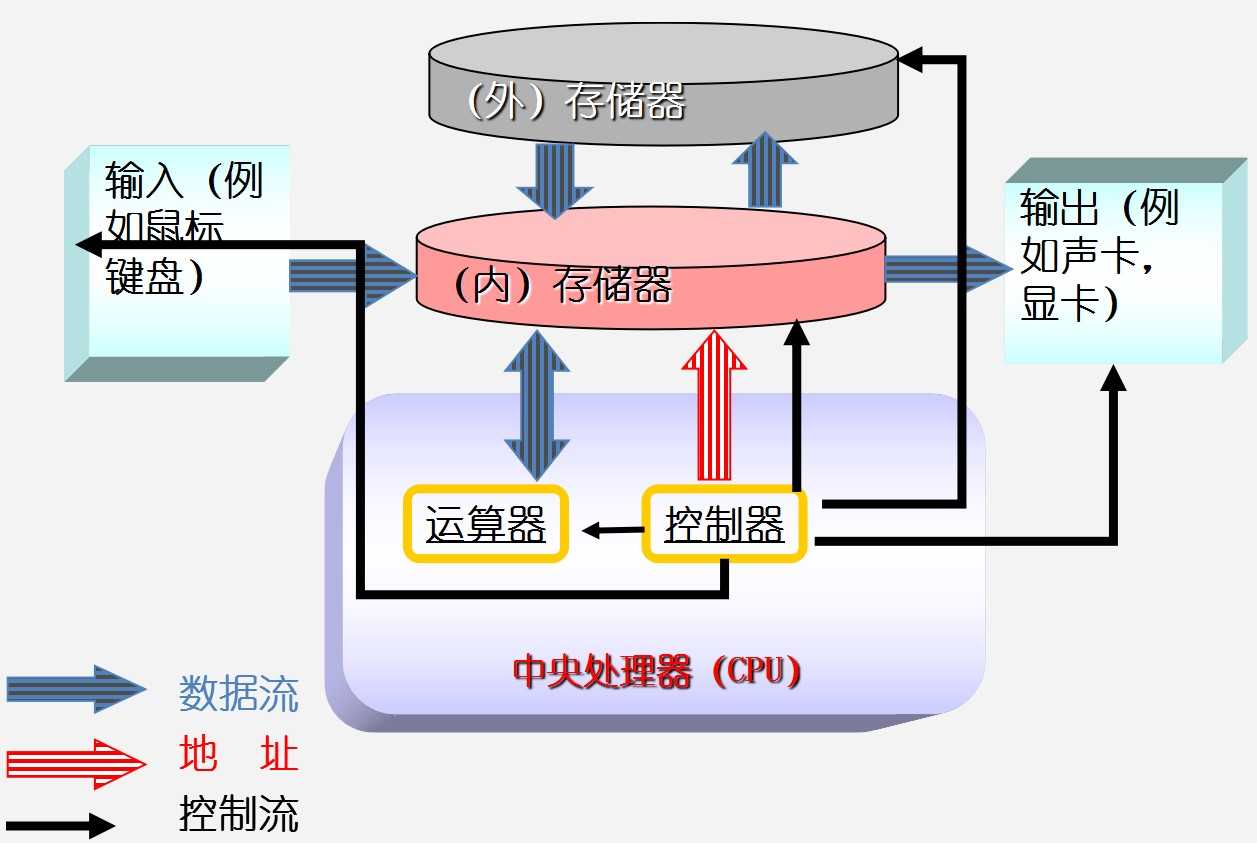
内存是沟通CPU与硬盘的桥梁:
有关内存的两个概念:物理存储器和存储地址空间。
物理存储器:实际存在的具体存储器芯片。
存储地址空间:对存储器编码的范围。我们在软件上常说的内存是指这一层含义。
内存中的每一个数据都会分配相应的地址:
#include <stdio.h>
int main()
{
int a = 0;
char b = 100;
printf("%p, %p\n", &a, &b); //打印a, b的地址
//int *代表是一种数据类型,int*指针类型,p才是变量名
//定义了一个指针类型的变量,可以指向一个int类型变量的地址
int *p;
p = &a;//将a的地址赋值给变量p,p也是一个变量,值是一个内存地址编号
printf("%d\n", *p);//p指向了a的地址,*p就是a的值
char *p1 = &b;
printf("%c\n", *p1);//*p1指向了b的地址,*p1就是b的值
return 0;
}
注意:&可以取得一个变量在内存中的地址。但是,不能取寄存器变量,因为寄存器变量不在内存里,而在CPU里面,所以是没有地址的。
int a = 0;
int b = 11;
int *p = &a;
*p = 100;
printf("a = %d, *p = %d\n", a, *p);
p = &b;
*p = 22;
printf("b = %d, *p = %d\n", b, *p);
int *p1;
int **p2;
char *p3;
char **p4;
printf("sizeof(p1) = %d\n", sizeof(p1));
printf("sizeof(p2) = %d\n", sizeof(p2));
printf("sizeof(p3) = %d\n", sizeof(p3));
printf("sizeof(p4) = %d\n", sizeof(p4));
printf("sizeof(double *) = %d\n", sizeof(double *));
指针变量也是变量,是变量就可以任意赋值,不要越界即可(32位为4字节,64位为8字节),但是,任意数值赋值给指针变量没有意义,因为这样的指针就成了野指针,此指针指向的区域是未知(操作系统不允许操作此指针指向的内存区域)。所以,野指针不会直接引发错误,操作野指针指向的内存区域才会出问题。
int a = 100;
int *p;
p = a; //把a的值赋值给指针变量p,p为野指针, ok,不会有问题,但没有意义
p = 0x12345678; //给指针变量p赋值,p为野指针, ok,不会有问题,但没有意义
*p = 1000; //操作野指针指向未知区域,内存出问题,err
但是,野指针和有效指针变量保存的都是数值,为了标志此指针变量没有指向任何变量(空闲可用),C语言中,可以把NULL赋值给此指针,这样就标志此指针为空指针,没有任何指针。
int *p = NULL;
NULL是一个值为0的宏常量:
#define NULL ((void *)0)
void *指针可以指向任意变量的内存空间:
void *p = NULL;
int a = 10;
p = (void *)&a; //指向变量时,最好转换为void *
//使用指针变量指向的内存时,转换为int *
*( (int *)p ) = 11;
printf("a = %d\n", a);
int a = 100;
int b = 200;
//指向常量的指针
//修饰*,指针指向内存区域不能修改,指针指向可以变
const int *p1 = &a; //等价于int const *p1 = &a;
//*p1 = 111; //err
p1 = &b; //ok
//指针常量
//修饰p1,指针指向不能变,指针指向的内存可以修改
int * const p2 = &a;
//p2 = &b; //err
*p2 = 222; //ok
数组名字是数组的首元素地址,但它是一个常量:
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
printf("a = %p\n", a);
printf("&a[0] = %p\n", &a[0]);
//a = 10; //err, 数组名只是常量,不能修改
#include <stdio.h>
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int i = 0;
int n = sizeof(a) / sizeof(a[0]);
for (i = 0; i < n; i++)
{
//printf("%d, ", a[i]);
printf("%d, ", *(a+i));
}
printf("\n");
int *p = a; //定义一个指针变量保存a的地址
for (i = 0; i < n; i++)
{
p[i] = 2 * i;
}
for (i = 0; i < n; i++)
{
printf("%d, ", *(p + i));
}
printf("\n");
return 0;
}
1)加法运算
#include <stdio.h>
int main()
{
int a;
int *p = &a;
printf("%d\n", p);
p += 2;//移动了2个int
printf("%d\n", p);
char b = 0;
char *p1 = &b;
printf("%d\n", p1);
p1 += 2;//移动了2个char
printf("%d\n", p1);
return 0;
}
通过改变指针指向操作数组元素:
#include <stdio.h>
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int i = 0;
int n = sizeof(a) / sizeof(a[0]);
int *p = a;
for (i = 0; i < n; i++)
{
printf("%d, ", *p);
p++;
}
printf("\n");
return 0;
}
2) 减法运算
示例1:
#include <stdio.h>
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int i = 0;
int n = sizeof(a) / sizeof(a[0]);
int *p = a+n-1;
for (i = 0; i < n; i++)
{
printf("%d, ", *p);
p--;
}
printf("\n");
return 0;
}
示例2:
#include <stdio.h>
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int *p2 = &a[2]; //第2个元素地址
int *p1 = &a[1]; //第1个元素地址
printf("p1 = %p, p2 = %p\n", p1, p2);
int n1 = p2 - p1; //n1 = 1
int n2 = (int)p2 - (int)p1; //n2 = 4
printf("n1 = %d, n2 = %d\n", n1, n2);
return 0;
}
指针数组,它是数组,数组的每个元素都是指针类型。
#include <stdio.h>
int main()
{
//指针数组
int *p[3];
int a = 1;
int b = 2;
int c = 3;
int i = 0;
p[0] = &a;
p[1] = &b;
p[2] = &c;
for (i = 0; i < sizeof(p) / sizeof(p[0]); i++ )
{
printf("%d, ", *(p[i]));
}
printf("\n");
return 0;
}
int a = 10;
int *p = &a; //一级指针
*p = 100; //*p就是a
int **q = &p;
//*q就是p
//**q就是a
int ***t = &q;
//*t就是q
//**t就是p
//***t就是a
#include <stdio.h>
void swap1(int x, int y)
{
int tmp;
tmp = x;
x = y;
y = tmp;
printf("x = %d, y = %d\n", x, y);
}
void swap2(int *x, int *y)
{
int tmp;
tmp = *x;
*x = *y;
*y = tmp;
}
int main()
{
int a = 3;
int b = 5;
swap1(a, b); //值传递
printf("a = %d, b = %d\n", a, b);
a = 3;
b = 5;
swap2(&a, &b); //地址传递
printf("a2 = %d, b2 = %d\n", a, b);
return 0;
}
数组名做函数参数,函数的形参会退化为指针:
#include <stdio.h>
//void printArrary(int a[10], int n)
//void printArrary(int a[], int n)
void printArrary(int *a, int n)
{
int i = 0;
for (i = 0; i < n; i++)
{
printf("%d, ", a[i]);
}
printf("\n");
}
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int n = sizeof(a) / sizeof(a[0]);
//数组名做函数参数
printArrary(a, n);
return 0;
}
#include <stdio.h>
int a = 10
int *getA()
{
return &a;
}
int main()
{
*( getA() ) = 111;
printf("a = %d\n", a);
return 0;
}
#include <stdio.h>
int main()
{
char str[] = "hello world";
char *p = str;
*p = ‘m‘;
p++;
*p = ‘i‘;
printf("%s\n", str);
p = "mike jiang";
printf("%s\n", p);
char *q = "test";
printf("%s\n", q);
return 0;
}
#include <stdio.h>
void mystrcat(char *dest, const char *src)
{
int len1 = 0;
int len2 = 0;
while (dest[len1])
{
len1++;
}
while (src[len2])
{
len2++;
}
int i;
for (i = 0; i < len2; i++)
{
dest[len1 + i] = src[i];
}
}
int main()
{
char dst[100] = "hello mike";
char src[] = "123456";
mystrcat(dst, src);
printf("dst = %s\n", dst);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
//const修饰一个变量为只读
const int a = 10;
//a = 100; //err
//指针变量, 指针指向的内存, 2个不同概念
char buf[] = "aklgjdlsgjlkds";
//从左往右看,跳过类型,看修饰哪个字符
//如果是*, 说明指针指向的内存不能改变
//如果是指针变量,说明指针的指向不能改变,指针的值不能修改
const char *p = buf;
// 等价于上面 char const *p1 = buf;
//p[1] = ‘2‘; //err
p = "agdlsjaglkdsajgl"; //ok
char * const p2 = buf;
p2[1] = ‘3‘;
//p2 = "salkjgldsjaglk"; //err
//p3为只读,指向不能变,指向的内存也不能变
const char * const p3 = buf;
return 0;
}
int main(int argc, char *argv[]);
#include <stdio.h>
//argc: 传参数的个数(包含可执行程序)
//argv:指针数组,指向输入的参数
int main(int argc, char *argv[])
{
//指针数组,它是数组,每个元素都是指针
char *a[] = { "aaaaaaa", "bbbbbbbbbb", "ccccccc" };
int i = 0;
printf("argc = %d\n", argc);
for (i = 0; i < argc; i++)
{
printf("%s\n", argv[i]);
}
return 0;
}
1) strstr中的while和do-while模型
利用strstr标准库函数找出一个字符串中substr出现的个数。
a) while模型
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *p = "11abcd111122abcd333abcd3322abcd3333322qqq";
int n = 0;
while ((p = strstr(p, "abcd")) != NULL)
{
//能进来,肯定有匹配的子串
//重新设置起点位置
p = p + strlen("abcd");
n++;
if (*p == 0) //如果到结束符
{
break;
}
}
printf("n = %d\n", n);
return 0;
}
b) do-while模型
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *p = "11abcd111122abcd333abcd3322abcd3333322qqq";
int n = 0;
do
{
p = strstr(p, "abcd");
if (p != NULL)
{
n++; //累计个数
//重新设置查找的起点
p = p + strlen("abcd");
}
else //如果没有匹配的字符串,跳出循环
{
break;
}
} while (*p != 0); //如果没有到结尾
printf("n = %d\n", n);
return 0;
}
2) 两头堵模型
求非空字符串元素的个数:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int fun(char *p, int *n)
{
if (p == NULL || n == NULL)
{
return -1;
}
int begin = 0;
int end = strlen(p) - 1;
//从左边开始
//如果当前字符为空,而且没有结束
while (p[begin] == ‘ ‘ && p[begin] != 0)
{
begin++; //位置从右移动一位
}
//从右往左移动
while (p[end] == ‘ ‘ && end > 0)
{
end--; //往左移动
}
if (end == 0)
{
return -2;
}
//非空元素个数
*n = end - begin + 1;
return 0;
}
int main(void)
{
char *p = " abcddsgadsgefg ";
int ret = 0;
int n = 0;
ret = fun(p, &n);
if (ret != 0)
{
return ret;
}
printf("非空字符串元素个数:%d\n", n);
return 0;
}
3) 字符串反转模型(逆置)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int inverse(char *p)
{
if (p == NULL)
{
return -1;
}
char *str = p;
int begin = 0;
int end = strlen(str) - 1;
char tmp;
while (begin < end)
{
//交换元素
tmp = str[begin];
str[begin] = str[end];
str[end] = tmp;
begin++; //往右移动位置
end--; //往左移动位置
}
return 0;
}
int main(void)
{
//char *str = "abcdefg"; //文件常量区,内容不允许修改
char str[] = "abcdef";
int ret = inverse(str);
if (ret != 0)
{
return ret;
}
printf("str ========== %s\n", str);
return 0;
}
|
定义 |
说明 |
|
int i |
定义整形变量 |
|
int *p |
定义一个指向int的指针变量 |
|
int a[10] |
定义一个有10个元素的数组,每个元素类型为int |
|
int *p[10] |
定义一个有10个元素的数组,每个元素类型为int* |
|
int func() |
定义一个函数,返回值为int型 |
|
int *func() |
定义一个函数,返回值为int *型 |
|
int **p |
定义一个指向int的指针的指针,二级指针 |
C语言变量的作用域分为:
局部变量也叫auto自动变量(auto可写可不写),一般情况下代码块{}内部定义的变量都是自动变量,它有如下特点:
#include <stdio.h>
void test()
{
//auto写不写是一样的
//auto只能出现在{}内部
auto int b = 10;
}
int main(void)
{
//b = 100; //err, 在main作用域中没有b
if (1)
{
//在复合语句中定义,只在复合语句中有效
int a = 10;
printf("a = %d\n", a);
}
//a = 10; //err离开if()的复合语句,a已经不存在
return 0;
}
8.1.2 静态(static)局部变量
#include <stdio.h>
void fun1()
{
int i = 0;
i++;
printf("i = %d\n", i);
}
void fun2()
{
//静态局部变量,没有赋值,系统赋值为0,而且只会初始化一次
static int a;
a++;
printf("a = %d\n", a);
}
int main(void)
{
fun1();
fun1();
fun2();
fun2();
return 0;
}
extern int a;声明一个变量,这个变量在别的文件中已经定义了,这里只是声明,而不是定义。
在C语言中函数默认都是全局的,使用关键字static可以将函数声明为静态,函数定义为static就意味着这个函数只能在定义这个函数的文件中使用,在其他文件中不能调用,即使在其他文件中声明这个函数都没用。
对于不同文件中的staitc函数名字可以相同。
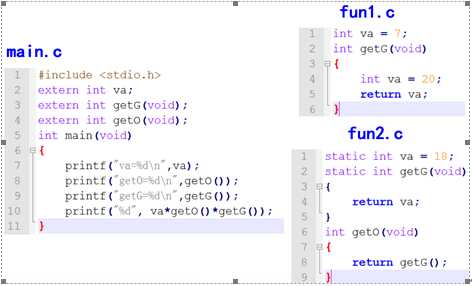
注意:
|
类型 |
作用域 |
生命周期 |
|
auto变量 |
一对{}内 |
当前函数 |
|
static局部变量 |
一对{}内 |
整个程序运行期 |
|
extern变量 |
整个程序 |
整个程序运行期 |
|
static全局变量 |
当前文件 |
整个程序运行期 |
|
extern函数 |
整个程序 |
整个程序运行期 |
|
static函数 |
当前文件 |
整个程序运行期 |
|
register变量 |
一对{}内 |
当前函数 |
C代码经过预处理、编译、汇编、链接4步后生成一个可执行程序。
在 Linux 下,程序是一个普通的可执行文件,以下列出一个二进制可执行文件的基本情况:
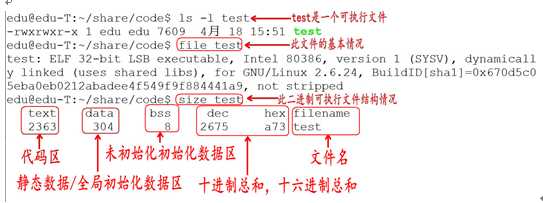
通过上图可以得知,在没有运行程序前,也就是说程序没有加载到内存前,可执行程序内部已经分好3段信息,分别为代码区(text)、数据区(data)和未初始化数据区(bss)3 个部分(有些人直接把data和bss合起来叫做静态区或全局区)。
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
程序在加载到内存前,代码区和全局区(data和bss)的大小就是固定的,程序运行期间不能改变。然后,运行可执行程序,系统把程序加载到内存,除了根据可执行程序的信息分出代码区(text)、数据区(data)和未初始化数据区(bss)之外,还额外增加了栈区、堆区。
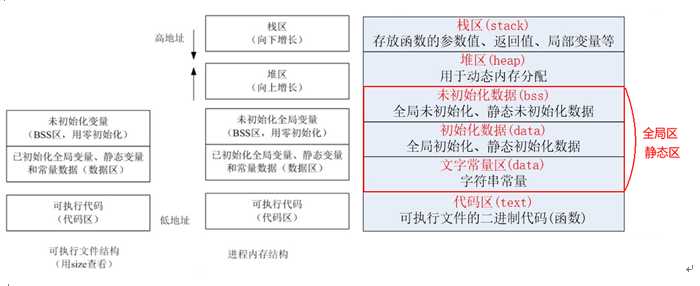
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
|
类型 |
作用域 |
生命周期 |
存储位置 |
|
auto变量 |
一对{}内 |
当前函数 |
栈区 |
|
static局部变量 |
一对{}内 |
整个程序运行期 |
初始化在data段,未初始化在BSS段 |
|
extern变量 |
整个程序 |
整个程序运行期 |
初始化在data段,未初始化在BSS段 |
|
static全局变量 |
当前文件 |
整个程序运行期 |
初始化在data段,未初始化在BSS段 |
|
extern函数 |
整个程序 |
整个程序运行期 |
代码区 |
|
static函数 |
当前文件 |
整个程序运行期 |
代码区 |
|
register变量 |
一对{}内 |
当前函数 |
运行时存储在CPU寄存器 |
|
字符串常量 |
当前文件 |
整个程序运行期 |
data段 |
#include <stdio.h>
#include <stdlib.h>
int e;
static int f;
int g = 10;
static int h = 10;
int main()
{
int a;
int b = 10;
static int c;
static int d = 10;
char *i = "test";
char *k = NULL;
printf("&a\t %p\t //局部未初始化变量\n", &a);
printf("&b\t %p\t //局部初始化变量\n", &b);
printf("&c\t %p\t //静态局部未初始化变量\n", &c);
printf("&d\t %p\t //静态局部初始化变量\n", &d);
printf("&e\t %p\t //全局未初始化变量\n", &e);
printf("&f\t %p\t //全局静态未初始化变量\n", &f);
printf("&g\t %p\t //全局初始化变量\n", &g);
printf("&h\t %p\t //全局静态初始化变量\n", &h);
printf("i\t %p\t //只读数据(文字常量区)\n", i);
k = (char *)malloc(10);
printf("k\t %p\t //动态分配的内存\n", k);
return 0;
}
1) memset()
#include <string.h>
void *memset(void *s, intc, size_tn);
功能:将s的内存区域的前n个字节以参数c填入
参数:
s:需要操作内存s的首地址
c:填充的字符,c虽然参数为int,但必须是unsigned char , 范围为0~255
n:指定需要设置的大小
返回值:s的首地址
int a[10];
memset(a, 0, sizeof(a));
memset(a, 97, sizeof(a));
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%c\n", a[i]);
}
2) memcpy()
#include <string.h>
void *memcpy(void *dest, constvoid *src, size_tn);
功能:拷贝src所指的内存内容的前n个字节到dest所值的内存地址上。
参数:
dest:目的内存首地址
src:源内存首地址,注意:dest和src所指的内存空间不可重叠
n:需要拷贝的字节数
返回值:dest的首地址
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int b[10];
memcpy(b, a, sizeof(a));
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d, ", b[i]);
}
printf("\n");
//memcpy(&a[3], a, 5 * sizeof(int)); //err, 内存重叠
3) memmove()
memmove()功能用法和memcpy()一样,区别在于:dest和src所指的内存空间重叠时,memmove()仍然能处理,不过执行效率比memcpy()低些。
4) memcmp()
#include <string.h>
intmemcmp(constvoid *s1, constvoid *s2, size_tn);
功能:比较s1和s2所指向内存区域的前n个字节
参数:
s1:内存首地址1
s2:内存首地址2
n:需比较的前n个字节
返回值:
相等:=0
大于:>0
小于:<0
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int b[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int flag = memcmp(a, b, sizeof(a));
printf("flag = %d\n", flag);
1)malloc()
#include <stdlib.h>
void *malloc(size_tsize);
功能:在内存的动态存储区(堆区)中分配一块长度为size字节的连续区域,用来存放类型说明符指定的类型。分配的内存空间内容不确定,一般使用memset初始化。
参数:
size:需要分配内存大小(单位:字节)
返回值:
成功:分配空间的起始地址
失败:NULL
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
int count, *array, n;
printf("请输入要申请数组的个数:\n");
scanf("%d", &n);
array = (int *)malloc(n * sizeof (int));
if (array == NULL)
{
printf("申请空间失败!\n");
return -1;
}
//将申请到空间清0
memset(array, 0, sizeof(int)*n);
for (count = 0; count < n; count++) /*给数组赋值*/
array[count] = count;
for (count = 0; count < n; count++) /*打印数组元素*/
printf("%2d", array[count]);
free(array);
return 0;
}
2)free()
#include <stdlib.h>
voidfree(void *ptr);
功能:释放ptr所指向的一块内存空间,ptr是一个任意类型的指针变量,指向被释放区域的首地址。对同一内存空间多次释放会出错。
参数:
ptr:需要释放空间的首地址,被释放区应是由malloc函数所分配的区域。
返回值:无
1) 返回栈区地址
#include <stdio.h>
int a = 10;
int *fun()
{
return &a;//函数调用完毕,a释放
}
int main(int argc, char *argv[])
{
int *p = NULL;
p = fun();
*p = 100; //操作野指针指向的内存,err
return 0;
}
2) 返回data区地址
#include <stdio.h>
int *fun()
{
static int a = 10;
return &a; //函数调用完毕,a不释放
}
int main(int argc, char *argv[])
{
int *p = NULL;
p = fun();
*p = 100; //ok
printf("*p = %d\n", *p);
return 0;
}
3) 值传递1
#include <stdio.h>
#include <stdlib.h>
void fun(int *tmp)
{
tmp = (int *)malloc(sizeof(int));
*tmp = 100;
}
int main(int argc, char *argv[])
{
int *p = NULL;
fun(p); //值传递,形参修改不会影响实参
printf("*p = %d\n", *p);//err,操作空指针指向的内存
return 0;
}
4) 值传递2
#include <stdio.h>
#include <stdlib.h>
void fun(int *tmp)
{
*tmp = 100;
}
int main(int argc, char *argv[])
{
int *p = NULL;
p = (int *)malloc(sizeof(int));
fun(p); //值传递
printf("*p = %d\n", *p); //ok,*p为100
return 0;
}
5) 返回堆区地址
#include <stdio.h>
#include <stdlib.h>
int *fun()
{
int *tmp = NULL;
tmp = (int *)malloc(sizeof(int));
*tmp = 100;
return tmp;//返回堆区地址,函数调用完毕,不释放
}
int main(int argc, char *argv[])
{
int *p = NULL;
p = fun();
printf("*p = %d\n", *p);//ok
//堆区空间,使用完毕,手动释放
if (p != NULL)
{
free(p);
p = NULL;
}
return 0;
}
数组:描述一组具有相同类型数据的有序集合,用于处理大量相同类型的数据运算。
有时我们需要将不同类型的数据组合成一个有机的整体,如:一个学生有学号/姓名/性别/年龄/地址等属性。显然单独定义以上变量比较繁琐,数据不便于管理。
C语言中给出了另一种构造数据类型——结构体。

定义结构体变量的方式:
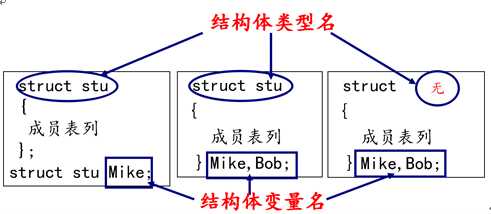
结构体类型和结构体变量关系:
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
//先定义类型,再定义变量(常用)
struct stu s1 = { "mike", 18 };
//定义类型同时定义变量
struct stu2
{
char name[50];
int age;
}s2 = { "lily", 22 };
struct
{
char name[50];
int age;
}s3 = { "yuri", 25 };
#include<stdio.h>
#include<string.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
int main()
{
struct stu s1;
//如果是普通变量,通过点运算符操作结构体成员
strcpy(s1.name, "abc");
s1.age = 18;
printf("s1.name = %s, s1.age = %d\n", s1.name, s1.age);
//如果是指针变量,通过->操作结构体成员
strcpy((&s1)->name, "test");
(&s1)->age = 22;
printf("(&s1)->name = %s, (&s1)->age = %d\n", (&s1)->name, (&s1)->age);
return 0;
}
#include <stdio.h>
//统计学生成绩
struct stu
{
int num;
char name[20];
char sex;
float score;
};
int main()
{
//定义一个含有5个元素的结构体数组并将其初始化
struct stu boy[5] = {
{ 101, "Li ping", ‘M‘, 45 },
{ 102, "Zhang ping", ‘M‘, 62.5 },
{ 103, "He fang", ‘F‘, 92.5 },
{ 104, "Cheng ling", ‘F‘, 87 },
{ 105, "Wang ming", ‘M‘, 58 }};
int i = 0;
int c = 0;
float ave, s = 0;
for (i = 0; i < 5; i++)
{
s += boy[i].score; //计算总分
if (boy[i].score < 60)
{
c += 1; //统计不及格人的分数
}
}
printf("s=%f\n", s);//打印总分数
ave = s / 5; //计算平均分数
printf("average=%f\ncount=%d\n\n", ave, c); //打印平均分与不及格人数
for (i = 0; i < 5; i++)
{
printf(" name=%s, score=%f\n", boy[i].name, boy[i].score);
// printf(" name=%s, score=%f\n", (boy+i)->name, (boy+i)->score);
}
return 0;
}
#include <stdio.h>
struct person
{
char name[20];
char sex;
};
struct stu
{
int id;
struct person info;
};
int main()
{
struct stu s[2] = { 1, "lily", ‘F‘, 2, "yuri", ‘M‘ };
int i = 0;
for (i = 0; i < 2; i++)
{
printf("id = %d\tinfo.name=%s\tinfo.sex=%c\n", s[i].id, s[i].info.name, s[i].info.sex);
}
return 0;
}
#include<stdio.h>
#include<string.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
int main()
{
struct stu s1;
//如果是普通变量,通过点运算符操作结构体成员
strcpy(s1.name, "abc");
s1.age = 18;
printf("s1.name = %s, s1.age = %d\n", s1.name, s1.age);
//相同类型的两个结构体变量,可以相互赋值
//把s1成员变量的值拷贝给s2成员变量的内存
//s1和s2只是成员变量的值一样而已,它们还是没有关系的两个变量
struct stu s2 = s1;
//memcpy(&s2, &s1, sizeof(s1));
printf("s2.name = %s, s2.age = %d\n", s2.name, s2.age);
return 0;
}
1)指向普通结构体变量的指针
#include<stdio.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
int main()
{
struct stu s1 = { "lily", 18 };
//如果是指针变量,通过->操作结构体成员
struct stu *p = &s1;
printf("p->name = %s, p->age=%d\n", p->name, p->age);
printf("(*p).name = %s, (*p).age=%d\n", (*p).name, (*p).age);
return 0;
}
#include<stdio.h>
#include <string.h>
#include <stdlib.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
int main()
{
struct stu *p = NULL;
p = (struct stu *)malloc(sizeof(struct stu));
//如果是指针变量,通过->操作结构体成员
strcpy(p->name, "test");
p->age = 22;
printf("p->name = %s, p->age=%d\n", p->name, p->age);
printf("(*p).name = %s, (*p).age=%d\n", (*p).name, (*p).age);
free(p);
p = NULL;
return 0;
}
3)结构体套一级指针
#include<stdio.h>
#include <string.h>
#include <stdlib.h>
//结构体类型的定义
struct stu
{
char *name; //一级指针
int age;
};
int main()
{
struct stu *p = NULL;
p = (struct stu *)malloc(sizeof(struct stu));
p->name = malloc(strlen("test") + 1);
strcpy(p->name, "test");
p->age = 22;
printf("p->name = %s, p->age=%d\n", p->name, p->age);
printf("(*p).name = %s, (*p).age=%d\n", (*p).name, (*p).age);
if (p->name != NULL)
{
free(p->name);
p->name = NULL;
}
if (p != NULL)
{
free(p);
p = NULL;
}
return 0;
}
1)结构体普通变量做函数参数
#include<stdio.h>
#include <string.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
//函数参数为结构体普通变量
void set_stu(struct stu tmp)
{
strcpy(tmp.name, "mike");
tmp.age = 18;
printf("tmp.name = %s, tmp.age = %d\n", tmp.name, tmp.age);
}
int main()
{
struct stu s = { 0 };
set_stu(s); //值传递
printf("s.name = %s, s.age = %d\n", s.name, s.age);
return 0;
}
2)结构体指针变量做函数参数
#include<stdio.h>
#include <string.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
//函数参数为结构体指针变量
void set_stu_pro(struct stu *tmp)
{
strcpy(tmp->name, "mike");
tmp->age = 18;
}
int main()
{
struct stu s = { 0 };
set_stu_pro(&s); //地址传递
printf("s.name = %s, s.age = %d\n", s.name, s.age);
return 0;
}
3)结构体数组名做函数参数
#include<stdio.h>
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
//void set_stu_pro(struct stu tmp[100], int n)
//void set_stu_pro(struct stu tmp[], int n)
void set_stu_pro(struct stu *tmp, int n)
{
int i = 0;
for (i = 0; i < n; i++)
{
sprintf(tmp->name, "name%d%d%d", i, i, i);
tmp->age = 20 + i;
tmp++;
}
}
int main()
{
struct stu s[3] = { 0 };
int i = 0;
int n = sizeof(s) / sizeof(s[0]);
set_stu_pro(s, n); //数组名传递
for (i = 0; i < n; i++)
{
printf("%s, %d\n", s[i].name, s[i].age);
}
return 0;
}
4)const修饰结构体指针形参变量
//结构体类型的定义
struct stu
{
char name[50];
int age;
};
void fun1(struct stu * const p)
{
//p = NULL; //err
p->age = 10; //ok
}
//void fun2(struct stu const* p)
void fun2(const struct stu * p)
{
p = NULL; //ok
//p->age = 10; //err
}
void fun3(const struct stu * const p)
{
//p = NULL; //err
//p->age = 10; //err
}
#include <stdio.h>
//共用体也叫联合体
union Test
{
unsigned char a;
unsigned int b;
unsigned short c;
};
int main()
{
//定义共用体变量
union Test tmp;
//1、所有成员的首地址是一样的
printf("%p, %p, %p\n", &(tmp.a), &(tmp.b), &(tmp.c));
//2、共用体大小为最大成员类型的大小
printf("%lu\n", sizeof(union Test));
//3、一个成员赋值,会影响另外的成员
//左边是高位,右边是低位
//低位放低地址,高位放高地址
tmp.b = 0x44332211;
printf("%x\n", tmp.a); //11
printf("%x\n", tmp.c); //2211
tmp.a = 0x00;
printf("short: %x\n", tmp.c); //2200
printf("int: %x\n", tmp.b); //44332200
return 0;
}
枚举:将变量的值一一列举出来,变量的值只限于列举出来的值的范围内。
枚举类型定义:
enum 枚举名
{
枚举值表
};
#include <stdio.h>
enum weekday
{
sun = 2, mon, tue, wed, thu, fri, sat
} ;
enum bool
{
flase, true
};
int main()
{
enum weekday a, b, c;
a = sun;
b = mon;
c = tue;
printf("%d,%d,%d\n", a, b, c);
enum bool flag;
flag = true;
if (flag == 1)
{
printf("flag为真\n");
}
return 0;
}
typedef为C语言的关键字,作用是为一种数据类型(基本类型或自定义数据类型)定义一个新名字,不能创建新类型。
#include <stdio.h>
typedef int INT;
typedef char BYTE;
typedef BYTE T_BYTE;
typedef unsigned char UBYTE;
typedef struct type
{
UBYTE a;
INT b;
T_BYTE c;
}TYPE, *PTYPE;
int main()
{
TYPE t;
t.a = 254;
t.b = 10;
t.c = ‘c‘;
PTYPE p = &t;
printf("%u, %d, %c\n", p->a, p->b, p->c);
return 0;
}
指一组相关数据的有序集合,通常存储在外部介质(如磁盘)上,使用时才调入内存。
在操作系统中把每一个与主机相连的输入、输出设备看作是一个文件,把它们的输入、输出等同于对磁盘文件的读和写。
计算机的存储在物理上是二进制的,所以物理上所有的磁盘文件本质上都是一样的:以字节为单位进行顺序存储。

从用户或者操作系统使用的角度(逻辑上)把文件分为:
1)文本文件
2)二进制文件
在C语言中用一个指针变量指向一个文件,这个指针称为文件指针。
typedef struct
{
short level; //缓冲区"满"或者"空"的程度
unsigned flags; //文件状态标志
char fd; //文件描述符
unsigned char hold; //如无缓冲区不读取字符
short bsize; //缓冲区的大小
unsigned char *buffer;//数据缓冲区的位置
unsigned ar; //指针,当前的指向
unsigned istemp; //临时文件,指示器
short token; //用于有效性的检查
}FILE;
FILE是系统使用typedef定义出来的有关文件信息的一种结构体类型,结构中含有文件名、文件状态和文件当前位置等信息。
声明FILE结构体类型的信息包含在头文件“stdio.h”中,一般设置一个指向FILE类型变量的指针变量,然后通过它来引用这些FILE类型变量。通过文件指针就可对它所指的文件进行各种操作。
C语言中有三个特殊的文件指针由系统默认打开,用户无需定义即可直接使用:
任何文件使用之前必须打开:
#include <stdio.h>
FILE * fopen(constchar * filename, constchar * mode);
功能:打开文件
参数:
filename:需要打开的文件名,根据需要加上路径
mode:打开文件的模式设置
返回值:
成功:文件指针
失败:NULL
第一个参数的几种形式:
FILE *fp_passwd = NULL;
//相对路径:
//打开当前目录passdw文件:源文件(源程序)所在目录
FILE *fp_passwd = fopen("passwd.txt", "r");
//打开当前目录(test)下passwd.txt文件
fp_passwd = fopen(". / test / passwd.txt", "r");
//打开当前目录上一级目录(相对当前目录)passwd.txt文件
fp_passwd = fopen(".. / passwd.txt", "r");
//绝对路径:
//打开C盘test目录下一个叫passwd.txt文件
fp_passwd = fopen("c://test//passwd.txt","r");
第二个参数的几种形式(打开文件的方式):
|
打开模式 |
含义 |
|
r或rb |
以只读方式打开一个文本文件(不创建文件,若文件不存在则报错) |
|
w或wb |
以写方式打开文件(如果文件存在则清空文件,文件不存在则创建一个文件) |
|
a或ab |
以追加方式打开文件,在末尾添加内容,若文件不存在则创建文件 |
|
r+或rb+ |
以可读、可写的方式打开文件(不创建新文件) |
|
w+或wb+ |
以可读、可写的方式打开文件(如果文件存在则清空文件,文件不存在则创建一个文件) |
|
a+或ab+ |
以添加方式打开文件,打开文件并在末尾更改文件,若文件不存在则创建文件 |
注意:
n 当读取文件的时候,系统会将所有的 "\r\n" 转换成 "\n"
n 当写入文件的时候,系统会将 "\n" 转换成 "\r\n" 写入
n 以"二进制"方式打开文件,则读\写都不会进行这样的转换
int main(void)
{
FILE *fp = NULL;
// "\\"这样的路径形式,只能在windows使用
// "/"这样的路径形式,windows和linux平台下都可用,建议使用这种
// 路径可以是相对路径,也可是绝对路径
fp = fopen("../test", "w");
//fp = fopen("..\\test", "w");
if (fp == NULL) //返回空,说明打开失败
{
//perror()是标准出错打印函数,能打印调用库函数出错原因
perror("open");
return -1;
}
return 0;
}
任何文件在使用后应该关闭:
#include <stdio.h>
int fclose(FILE * stream);
功能:关闭先前fopen()打开的文件。此动作让缓冲区的数据写入文件中,并释放系统所提供的文件资源。
参数:
stream:文件指针
返回值:
成功:0
失败:-1
FILE * fp = NULL;
fp = fopen("abc.txt", "r");
fclose(fp);
#include <stdio.h>
int fputc(int ch, FILE * stream);
功能:将ch转换为unsigned char后写入stream指定的文件中
参数:
ch:需要写入文件的字符
stream:文件指针
返回值:
成功:成功写入文件的字符
失败:返回-1
char buf[] = "this is a test for fputc";
int i = 0;
int n = strlen(buf);
for (i = 0; i < n; i++)
{
//往文件fp写入字符buf[i]
int ch = fputc(buf[i], fp);
printf("ch = %c\n", ch);
}
在C语言中,EOF表示文件结束符(end of file)。在while循环中以EOF作为文件结束标志,这种以EOF作为文件结束标志的文件,必须是文本文件。在文本文件中,数据都是以字符的ASCII代码值的形式存放。我们知道,ASCII代码值的范围是0~127,不可能出现-1,因此可以用EOF作为文件结束标志。
#define EOF (-1)
当把数据以二进制形式存放到文件中时,就会有-1值的出现,因此不能采用EOF作为二进制文件的结束标志。为解决这一个问题,ANSI C提供一个feof函数,用来判断文件是否结束。feof函数既可用以判断二进制文件又可用以判断文本文件。
#include <stdio.h>
int feof(FILE * stream);
功能:检测是否读取到了文件结尾。判断的是最后一次“读操作的内容”,不是当前位置内容(上一个内容)。
参数:
stream:文件指针
返回值:
非0值:已经到文件结尾
0:没有到文件结尾
#include <stdio.h>
int fgetc(FILE * stream);
功能:从stream指定的文件中读取一个字符
参数:
stream:文件指针
返回值:
成功:返回读取到的字符
失败:-1
char ch;
#if 0
while ((ch = fgetc(fp)) != EOF)
{
printf("%c", ch);
}
printf("\n");
#endif
while (!feof(fp)) //文件没有结束,则执行循环
{
ch = fgetc(fp);
printf("%c", ch);
}
printf("\n");

#include <stdio.h>
int fputs(constchar * str, FILE * stream);
功能:将str所指定的字符串写入到stream指定的文件中,字符串结束符 ‘\0‘ 不写入文件。
参数:
str:字符串
stream:文件指针
返回值:
成功:0
失败:-1
char *buf[] = { "123456\n", "bbbbbbbbbb\n", "ccccccccccc\n" };
int i = 0;
int n = 3;
for (i = 0; i < n; i++)
{
int len = fputs(buf[i], fp);
printf("len = %d\n", len);
}
#include <stdio.h>
char * fgets(char * str, int size, FILE * stream);
功能:从stream指定的文件内读入字符,保存到str所指定的内存空间,直到出现换行字符、读到文件结尾或是已读了size - 1个字符为止,最后会自动加上字符 ‘\0‘ 作为字符串结束。
参数:
str:字符串
size:指定最大读取字符串的长度(size - 1)
stream:文件指针
返回值:
成功:成功读取的字符串
读到文件尾或出错: NULL
char buf[100] = 0;
while (!feof(fp)) //文件没有结束
{
memset(buf, 0, sizeof(buf));
char *p = fgets(buf, sizeof(buf), fp);
if (p != NULL)
{
printf("buf = %s", buf);
}
}
有个文件大小不确定,每行内容都是一个四则运算表达式,还没有算出结果,写一个程序,自动算出其结果后修改文件。
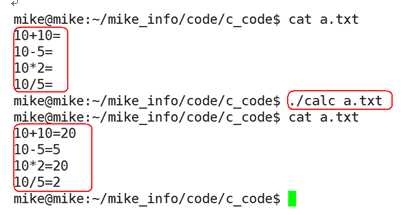
#include <stdio.h>
int fprintf(FILE * stream, constchar * format, ...);
功能:根据参数format字符串来转换并格式化数据,然后将结果输出到stream指定的文件中,指定出现字符串结束符 ‘\0‘ 为止。
参数:
stream:已经打开的文件
format:字符串格式,用法和printf()一样
返回值:
成功:实际写入文件的字符个数
失败:-1
fprintf(fp, "%d %d %d\n", 1, 2, 3);
#include <stdio.h>
int fscanf(FILE * stream, constchar * format, ...);
功能:从stream指定的文件读取字符串,并根据参数format字符串来转换并格式化数据。
参数:
stream:已经打开的文件
format:字符串格式,用法和scanf()一样
返回值:
成功:参数数目,成功转换的值的个数
失败: - 1
int a = 0;
int b = 0;
int c = 0;
fscanf(fp, "%d %d %d\n", &a, &b, &c);
printf("a = %d, b = %d, c = %d\n", a, b, c);
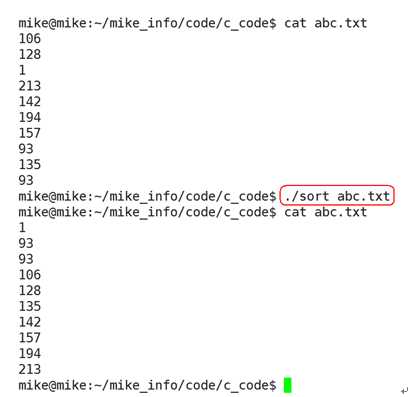
#include <stdio.h>
size_t fwrite(constvoid *ptr, size_t size, size_t nmemb, FILE *stream);
功能:以数据块的方式给文件写入内容
参数:
ptr:准备写入文件数据的地址
size: size_t 为 unsigned int类型,此参数指定写入文件内容的块数据大小
nmemb:写入文件的块数,写入文件数据总大小为:size * nmemb
stream:已经打开的文件指针
返回值:
成功:实际成功写入文件数据的块数目,此值和nmemb相等
失败:0
typedef struct Stu
{
char name[50];
int id;
}Stu;
Stu s[3];
int i = 0;
for (i = 0; i < 3; i++)
{
sprintf(s[i].name, "stu%d%d%d", i, i, i);
s[i].id = i + 1;
}
int ret = fwrite(s, sizeof(Stu), 3, fp);
printf("ret = %d\n", ret);
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
功能:以数据块的方式从文件中读取内容
参数:
ptr:存放读取出来数据的内存空间
size: size_t 为 unsigned int类型,此参数指定读取文件内容的块数据大小
nmemb:读取文件的块数,读取文件数据总大小为:size * nmemb
stream:已经打开的文件指针
返回值:
成功:实际成功读取到内容的块数,如果此值比nmemb小,但大于0,说明读到文件的结尾。
失败:0
typedef struct Stu
{
char name[50];
int id;
}Stu;
Stu s[3];
int ret = fread(s, sizeof(Stu), 3, fp);
printf("ret = %d\n", ret);
int i = 0;
for (i = 0; i < 3; i++)
{
printf("s = %s, %d\n", s[i].name, s[i].id);
}
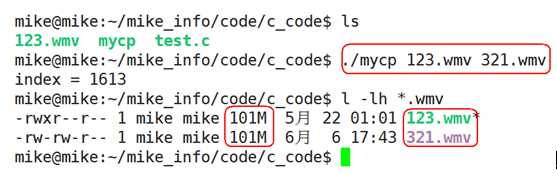
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
功能:移动文件流(文件光标)的读写位置。
参数:
stream:已经打开的文件指针
offset:根据whence来移动的位移数(偏移量),可以是正数,也可以负数,如果正数,则相对于whence往右移动,如果是负数,则相对于whence往左移动。如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过了文件末尾,再次写入时将增大文件尺寸。
whence:其取值如下:
SEEK_SET:从文件开头移动offset个字节
SEEK_CUR:从当前位置移动offset个字节
SEEK_END:从文件末尾移动offset个字节
返回值:
成功:0
失败:-1
#include <stdio.h>
long ftell(FILE *stream);
功能:获取文件流(文件光标)的读写位置。
参数:
stream:已经打开的文件指针
返回值:
成功:当前文件流(文件光标)的读写位置
失败:-1
#include <stdio.h>
void rewind(FILE *stream);
功能:把文件流(文件光标)的读写位置移动到文件开头。
参数:
stream:已经打开的文件指针
返回值:
无返回值
typedef struct Stu
{
char name[50];
int id;
}Stu;
//假如已经往文件写入3个结构体
//fwrite(s, sizeof(Stu), 3, fp);
Stu s[3];
Stu tmp;
int ret = 0;
//文件光标读写位置从开头往右移动2个结构体的位置
fseek(fp, 2 * sizeof(Stu), SEEK_SET);
//读第3个结构体
ret = fread(&tmp, sizeof(Stu), 1, fp);
if (ret == 1)
{
printf("[tmp]%s, %d\n", tmp.name, tmp.id);
}
//把文件光标移动到文件开头
//fseek(fp, 0, SEEK_SET);
rewind(fp);
ret = fread(s, sizeof(Stu), 3, fp);
printf("ret = %d\n", ret);
int i = 0;
for (i = 0; i < 3; i++)
{
printf("s === %s, %d\n", s[i].name, s[i].id);
}
判断文本文件是Linux格式还是Windows格式:
#include<stdio.h>
int main(int argc, char **args)
{
if (argc < 2)
return 0;
FILE *p = fopen(args[1], "rb");
if (!p)
return 0;
char a[1024] = { 0 };
fgets(a, sizeof(a), p);
int len = 0;
while (a[len])
{
if (a[len] == ‘\n‘)
{
if (a[len - 1] == ‘\r‘)
{
printf("windows file\n");
}
else
{
printf("linux file\n");
}
}
len++;
}
fclose(p);
return 0;
}
#include <sys/types.h>
#include <sys/stat.h>
intstat(constchar *path, structstat *buf);
功能:获取文件状态信息
参数:
path:文件名
buf:保存文件信息的结构体
返回值:
成功:0
失败-1
struct stat {
dev_t st_dev; //文件的设备编号
ino_t st_ino; //节点
mode_t st_mode; //文件的类型和存取的权限
nlink_t st_nlink; //连到该文件的硬连接数目,刚建立的文件值为1
uid_t st_uid; //用户ID
gid_t st_gid; //组ID
dev_t st_rdev; //(设备类型)若此文件为设备文件,则为其设备编号
off_t st_size; //文件字节数(文件大小)
unsigned long st_blksize; //块大小(文件系统的I/O 缓冲区大小)
unsigned long st_blocks; //块数
time_t st_atime; //最后一次访问时间
time_t st_mtime; //最后一次修改时间
time_t st_ctime; //最后一次改变时间(指属性)
};
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
int main(int argc, char **args)
{
if (argc < 2)
return 0;
struct stat st = { 0 };
stat(args[1], &st);
int size = st.st_size;//得到结构体中的成员变量
printf("%d\n", size);
return 0;
}
#include <stdio.h>
intremove(constchar *pathname);
功能:删除文件
参数:
pathname:文件名
返回值:
成功:0
失败:-1
#include <stdio.h>
intrename(constchar *oldpath, constchar *newpath);
功能:把oldpath的文件名改为newpath
参数:
oldpath:旧文件名
newpath:新文件名
返回值:
成功:0
失败: - 1
ANSI C标准采用“缓冲文件系统”处理数据文件。
所谓缓冲文件系统是指系统自动地在内存区为程序中每一个正在使用的文件开辟一个文件缓冲区从内存向磁盘输出数据必须先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘去。
如果从磁盘向计算机读入数据,则一次从磁盘文件将一批数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(给程序变量) 。
10.8.2磁盘文件的存取
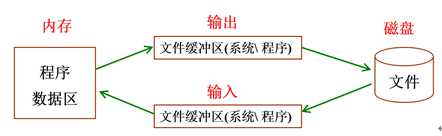
#include <stdio.h>
intfflush(FILE *stream);
功能:更新缓冲区,让缓冲区的数据立马写到文件中。
参数:
stream:文件指针
返回值:
成功:0
失败:-1
原文:https://www.cnblogs.com/qcdxw/p/11622828.html