这两天发现一个视频网站有我想要的视频资源(https://m.jlszyy.org/play/2873-0-0.html),想爬取,发现没那么简单。

里面是一个blob视频地址:
1 <video ... src="blob:https://jiexi.wysgtx.com/6764e0e3-2c88-44a4-bfea-341c32fb1697"></video>
不是直接一个mp4视频,没办法通过这个地址得到视频。
经过一天的琢磨,各种查资料,总算找到办法了。下面是分析和解决过程。
【分析】
F12进到调试模式,点击Network,选择XHR,然后强制刷新网页,看到底加载了啥:
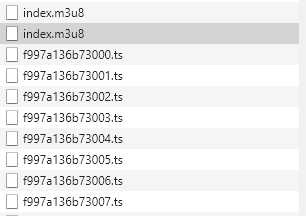
重点关注前两个index.m3u8。前后两个m3u8的response内容分别是:

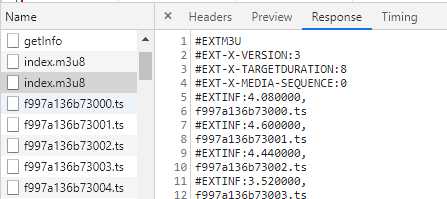
可见,第一个index.m3u8存储了第二个m3u8的地址,而第二个m3u8则存储了ts媒体分片的地址。
什么是m3u8,什么是ts媒体分片,参考[1],这里不展开介绍。
目前只需要知道:将这些分片按顺序拼接到一起,就是我要的一个完整视频,这就够了。
最快的办法是,把每个视频的第二个m3u8(就是存储了所有ts分片地址的那个m3u8)地址复制出来,利用ffmpeg下载。
在CentOS环境下,利用下面这个命令成功下载到了视频。(参考[2])以下载第23集为例:
1 ffmpeg -i https://sina.com-h-sina.com/20180906/18237_09096b18/800k/hls/index.m3u8 023.mp4
如果只是要下载视频,那么到此就结束了,文章下面也不用看了。(Windows平台有一个 M3U8 Downloader工具,也是基于ffmpeg实现的,用法更简单,参考[3])
----------------------------- [ 华丽的分割线 ] -----------------------------
一开始我并没有正确使用这个ffmpeg(错用了第一个m3u8的地址),没下载到视频,所以放弃了这个好用的工具,转而自己撸代码去爬取......
从Headers可以获得m3u8的网址。

我的思路是,收集整部剧(36集)每个视频第一个m3u8的地址,然后解析并爬取第二个m3u8,接着就能爬取所有ts文件了。(36个url地址应该可以脚本爬取,不用手动收集,这是这个思路可优化的地方。当然,我没做这个优化。)
不废话,直接贴出可运行的python代码(最终版本:解析m3u8,多进程下载):
1 from multiprocessing import Pool 2 import requests 3 import re 4 import os 5 6 ## 36个url 7 url_list=[ 8 ‘https://sina.com-h-sina.com/20180906/18215_c0fc8873/‘ , 9 ‘https://sina.com-h-sina.com/20180906/18216_80a7de01/‘ , 10 ‘https://sina.com-h-sina.com/20180906/18217_365c8b79/‘ , 11 ‘https://sina.com-h-sina.com/20180906/18218_f02026af/‘ , 12 ‘https://sina.com-h-sina.com/20180906/18219_7aca4012/‘ , 13 ‘https://sina.com-h-sina.com/20180906/18220_ed8429ba/‘ , 14 ‘https://cdn.youku-letv.net/20181130/11218_5aec4df0/‘ , 15 ‘https://cdn.youku-letv.net/20181130/11217_64a3d965/‘ , 16 ‘https://sina.com-h-sina.com/20180906/18223_5f07955a/‘ , 17 ‘https://sina.com-h-sina.com/20180906/18224_0f7d62f7/‘ , 18 ‘https://sina.com-h-sina.com/20180906/18225_70b7a36b/‘ , 19 ‘https://sina.com-h-sina.com/20180906/18226_e51fc698/‘ , 20 ‘https://sina.com-h-sina.com/20180906/18227_66271ec7/‘ , 21 ‘https://sina.com-h-sina.com/20180906/18228_026dee76/‘ , 22 ‘https://sina.com-h-sina.com/20180906/18229_371750e8/‘ , 23 ‘https://sina.com-h-sina.com/20180906/18230_997b5e5f/‘ , 24 ‘https://sina.com-h-sina.com/20180906/18231_88b8a296/‘ , 25 ‘https://sina.com-h-sina.com/20180906/18232_f20b2ca2/‘ , 26 ‘https://sina.com-h-sina.com/20180906/18233_3352578d/‘ , 27 ‘https://sina.com-h-sina.com/20180906/18234_347f6882/‘ , 28 ‘https://sina.com-h-sina.com/20180906/18235_44565aa7/‘ , 29 ‘https://cdn.youku-letv.net/20181130/11203_138f5930/‘ , 30 ‘https://sina.com-h-sina.com/20180906/18237_09096b18/‘ , 31 ‘https://sina.com-h-sina.com/20180906/18238_154e2c99/‘ , 32 ‘https://sina.com-h-sina.com/20180906/18239_e9fe736e/‘ , 33 ‘https://cdn.youku-letv.net/20181130/11199_aaf119a6/‘ , 34 ‘https://sina.com-h-sina.com/20180906/18241_e8d0a446/‘ , 35 ‘https://sina.com-h-sina.com/20180906/18242_ccfe1975/‘ , 36 ‘https://sina.com-h-sina.com/20180906/18243_316cafde/‘ , 37 ‘https://sina.com-h-sina.com/20180906/18244_c67bb56b/‘ , 38 ‘https://sina.com-h-sina.com/20180906/18245_f7707700/‘ , 39 ‘https://sina.com-h-sina.com/20180906/18246_01688d4e/‘ , 40 ‘https://sina.com-h-sina.com/20180906/18247_8bfc042c/‘ , 41 ‘https://sina.com-h-sina.com/20180906/18248_e85bfdc0/‘ , 42 ‘https://sina.com-h-sina.com/20180906/18249_b750a51f/‘ , 43 ‘https://cdn.youku-letv.net/20181130/11189_acdfba0e/‘ 44 ] 45 46 ## [注意]正阳门下的视频的第一个m3u8是指向另一个m3u8,并不是直接指向ts媒体分片 47 index=‘index.m3u8‘ 48 savefile_path=‘E://Downloads//ZhengYangMenXia//‘ 49 50 51 52 def download_task(n): 53 i = int(n) 54 print(‘task %d start!‘ % i) 55 # os.mkdir(savefile_path+str(i)+‘//‘) ## 创建文件夹。如果手动创建了文件夹,那就注释掉这一句 56 data=requests.get(url_list[i]+index) 57 58 lines=str.split(data.text, ‘\n‘) ## 字符串处理。从第一层m3u8里面取得真正的m3u8地址 59 m3u8=lines[2] 60 pattern="index.m3u8" 61 m3u8_directory=re.sub(pattern,"", m3u8) ## 取文件夹路径,后面会用到 62 63 data = requests.get(url_list[i] + m3u8) 64 ‘‘‘ 65 # 保存m3u8文件。此处注释掉,m3u8的内容就不存了。 66 file=open(savefile_path+str(i)+‘//‘+index, ‘w‘) 67 file.write(data.text) 68 file.close() 69 ‘‘‘ 70 lines=str.split(data.text,‘\n‘) 71 pattern=r".*ts" 72 # 保存ts文件(注意,是二进制的) 73 video = open(savefile_path + ‘//‘ + ‘正阳门下-‘ + str(i).zfill(3) + ‘.mp4‘, ‘wb‘) 74 for j in range(0,len(lines)): 75 if re.match(pattern,lines[j]): 76 print("Task %d Downloading %s..." % (i, lines[j])) 77 data = requests.get(url_list[i]+m3u8_directory+lines[j]) 78 video.write(data.content) 79 video.close() 80 print(‘Task %d done!‘ % i) 81 82 83 84 if __name__==‘__main__‘: ## 多进程程序,一定要有main函数。 85 pool=Pool(4) ## 4进程下载 86 for i in range(0,len(url_list)): 87 pool.apply_async(download_task, args=(i,)) 88 print(‘Task %d has been submited‘ % i) 89 print(‘Waiting for all subprocesses done...‘) 90 pool.close() 91 pool.join() 92 print(‘All subprocesses done.‘)
这份代码是这么写成的:
【1】收集数据,体现为一个url列表:
1 ## 36个url 2 url_list=[ 3 ‘https://sina.com-h-sina.com/20180906/18215_c0fc8873/‘ , 4 ‘https://sina.com-h-sina.com/20180906/18216_80a7de01/‘ , 5 ‘https://sina.com-h-sina.com/20180906/18217_365c8b79/‘ , 6 ‘https://sina.com-h-sina.com/20180906/18218_f02026af/‘ , 7 ‘https://sina.com-h-sina.com/20180906/18219_7aca4012/‘ , 8 ‘https://sina.com-h-sina.com/20180906/18220_ed8429ba/‘ , 9 ‘https://cdn.youku-letv.net/20181130/11218_5aec4df0/‘ , 10 ‘https://cdn.youku-letv.net/20181130/11217_64a3d965/‘ , 11 ‘https://sina.com-h-sina.com/20180906/18223_5f07955a/‘ , 12 ‘https://sina.com-h-sina.com/20180906/18224_0f7d62f7/‘ , 13 ‘https://sina.com-h-sina.com/20180906/18225_70b7a36b/‘ , 14 ‘https://sina.com-h-sina.com/20180906/18226_e51fc698/‘ , 15 ‘https://sina.com-h-sina.com/20180906/18227_66271ec7/‘ , 16 ‘https://sina.com-h-sina.com/20180906/18228_026dee76/‘ , 17 ‘https://sina.com-h-sina.com/20180906/18229_371750e8/‘ , 18 ‘https://sina.com-h-sina.com/20180906/18230_997b5e5f/‘ , 19 ‘https://sina.com-h-sina.com/20180906/18231_88b8a296/‘ , 20 ‘https://sina.com-h-sina.com/20180906/18232_f20b2ca2/‘ , 21 ‘https://sina.com-h-sina.com/20180906/18233_3352578d/‘ , 22 ‘https://sina.com-h-sina.com/20180906/18234_347f6882/‘ , 23 ‘https://sina.com-h-sina.com/20180906/18235_44565aa7/‘ , 24 ‘https://cdn.youku-letv.net/20181130/11203_138f5930/‘ , 25 ‘https://sina.com-h-sina.com/20180906/18237_09096b18/‘ , 26 ‘https://sina.com-h-sina.com/20180906/18238_154e2c99/‘ , 27 ‘https://sina.com-h-sina.com/20180906/18239_e9fe736e/‘ , 28 ‘https://cdn.youku-letv.net/20181130/11199_aaf119a6/‘ , 29 ‘https://sina.com-h-sina.com/20180906/18241_e8d0a446/‘ , 30 ‘https://sina.com-h-sina.com/20180906/18242_ccfe1975/‘ , 31 ‘https://sina.com-h-sina.com/20180906/18243_316cafde/‘ , 32 ‘https://sina.com-h-sina.com/20180906/18244_c67bb56b/‘ , 33 ‘https://sina.com-h-sina.com/20180906/18245_f7707700/‘ , 34 ‘https://sina.com-h-sina.com/20180906/18246_01688d4e/‘ , 35 ‘https://sina.com-h-sina.com/20180906/18247_8bfc042c/‘ , 36 ‘https://sina.com-h-sina.com/20180906/18248_e85bfdc0/‘ , 37 ‘https://sina.com-h-sina.com/20180906/18249_b750a51f/‘ , 38 ‘https://cdn.youku-letv.net/20181130/11189_acdfba0e/‘ 39 ]
【2】先试验性地将一集下载下来(也就是这一步确认了:只要将ts文件下载下来拼接到一起,就能得到一个完整视频)
1 # coding=utf8 2 import requests 3 4 url=‘https://sina.com-h-sina.com/20180906/18215_c0fc8873/800k/hls/f997a136b73‘ 5 6 for i in range(0,675): 7 f = open("E:/Downloads/tmp/%03d.ts" % i, ‘wb‘) 8 data = requests.get(url + str(i).zfill(3) + ‘.ts‘) 9 f.write(data.content) 10 f.close() 11 print(‘ts %03d OK‘ % i)
【3】遍历列表,爬取每个视频的第一个m3u8,然后解析出第二个m3u8的地址,接着爬取第二个m3u8,最后解析并爬取所有ts。
这也是我写的第一个版本
1 import requests 2 import re 3 import os 4 5 url_list=[ 6 ‘https://sina.com-h-sina.com/20180906/18215_c0fc8873/‘ , 7 ‘https://sina.com-h-sina.com/20180906/18216_80a7de01/‘ , 8 ‘https://sina.com-h-sina.com/20180906/18217_365c8b79/‘ , 9 ‘https://sina.com-h-sina.com/20180906/18218_f02026af/‘ , 10 ‘https://sina.com-h-sina.com/20180906/18219_7aca4012/‘ , 11 ‘https://sina.com-h-sina.com/20180906/18220_ed8429ba/‘ , 12 ‘https://cdn.youku-letv.net/20181130/11218_5aec4df0/‘ , 13 ‘https://cdn.youku-letv.net/20181130/11217_64a3d965/‘ , 14 ‘https://sina.com-h-sina.com/20180906/18223_5f07955a/‘ , 15 ‘https://sina.com-h-sina.com/20180906/18224_0f7d62f7/‘ , 16 ‘https://sina.com-h-sina.com/20180906/18225_70b7a36b/‘ , 17 ‘https://sina.com-h-sina.com/20180906/18226_e51fc698/‘ , 18 ‘https://sina.com-h-sina.com/20180906/18227_66271ec7/‘ , 19 ‘https://sina.com-h-sina.com/20180906/18228_026dee76/‘ , 20 ‘https://sina.com-h-sina.com/20180906/18229_371750e8/‘ , 21 ‘https://sina.com-h-sina.com/20180906/18230_997b5e5f/‘ , 22 ‘https://sina.com-h-sina.com/20180906/18231_88b8a296/‘ , 23 ‘https://sina.com-h-sina.com/20180906/18232_f20b2ca2/‘ , 24 ‘https://sina.com-h-sina.com/20180906/18233_3352578d/‘ , 25 ‘https://sina.com-h-sina.com/20180906/18234_347f6882/‘ , 26 ‘https://sina.com-h-sina.com/20180906/18235_44565aa7/‘ , 27 ‘https://cdn.youku-letv.net/20181130/11203_138f5930/‘ , 28 ‘https://sina.com-h-sina.com/20180906/18237_09096b18/‘ , 29 ‘https://sina.com-h-sina.com/20180906/18238_154e2c99/‘ , 30 ‘https://sina.com-h-sina.com/20180906/18239_e9fe736e/‘ , 31 ‘https://cdn.youku-letv.net/20181130/11199_aaf119a6/‘ , 32 ‘https://sina.com-h-sina.com/20180906/18241_e8d0a446/‘ , 33 ‘https://sina.com-h-sina.com/20180906/18242_ccfe1975/‘ , 34 ‘https://sina.com-h-sina.com/20180906/18243_316cafde/‘ , 35 ‘https://sina.com-h-sina.com/20180906/18244_c67bb56b/‘ , 36 ‘https://sina.com-h-sina.com/20180906/18245_f7707700/‘ , 37 ‘https://sina.com-h-sina.com/20180906/18246_01688d4e/‘ , 38 ‘https://sina.com-h-sina.com/20180906/18247_8bfc042c/‘ , 39 ‘https://sina.com-h-sina.com/20180906/18248_e85bfdc0/‘ , 40 ‘https://sina.com-h-sina.com/20180906/18249_b750a51f/‘ , 41 ‘https://cdn.youku-letv.net/20181130/11189_acdfba0e/‘ 42 ] 43 ## [注意]正阳门下的视频的第一个m3u8是指向另一个m3u8,并不是直接指向ts媒体分片 44 index=‘index.m3u8‘ 45 savefile_path=‘E://Downloads//ZhengYangMenXia//‘ 46 47 for i in range(0,len(url_list)): 48 # os.mkdir(savefile_path+str(i)+‘//‘) ## 创建文件夹。如果手动创建了文件夹,那就注释掉这一句 49 data=requests.get(url_list[i]+index) 50 51 lines=str.split(data.text, ‘\n‘) ## 字符串处理。从第一层m3u8里面取得真正的m3u8地址 52 m3u8=lines[2] 53 pattern="index.m3u8" 54 m3u8_directory=re.sub(pattern,"", m3u8) ## 取文件夹路径,后面会用到 55 56 data = requests.get(url_list[i] + m3u8) 57 ‘‘‘ 58 # 保存m3u8文件。注释掉,就不存了。 59 file=open(savefile_path+str(i)+‘//‘+index, ‘w‘) 60 file.write(data.text) 61 file.close() 62 ‘‘‘ 63 lines=str.split(data.text,‘\n‘) 64 pattern=r".*ts" 65 # 保存ts文件(注意,是二进制的) 66 video = open(savefile_path + str(i) + ‘//‘ + ‘正阳门下-‘ + str(i).zfill(3) + ‘.mp4‘, ‘wb‘) 67 for j in range(0,len(lines)): 68 if re.match(pattern,lines[j]): 69 print("Downloading %s..." % lines[j]) 70 data = requests.get(url_list[i]+m3u8_directory+lines[j]) 71 video.write(data.content) 72 video.close()
【4】单进程下载不够快,改成多进程吧。于是有了上面贴出来的第一份可运行代码。(参考[5])
【参考】
[1] m3u8的维基百科介绍:https://wikipedia.hk.wjbk.site/baike-M3U
[2] Linux平台,通过 ffmpeg命令下载视频:https://dzt666.cn/index.php/archives/203/
[3] Windows平台,通过 M3U8 Downloader 下载:https://blog.csdn.net/yjclsx/article/details/88948860
[4] m3u8和ts媒体分片的介绍:https://www.jianshu.com/p/4f6db32fc76a
[5] python多进程:https://www.liaoxuefeng.com/wiki/1016959663602400/1017628290184064
[6] 带来一点启发的参考资料:https://blog.csdn.net/angry_mills/article/details/82705595
原文:https://www.cnblogs.com/i-am-normal/p/11624225.html