1.打开文件,得到文件句柄并赋值给一个变量
2.通过句柄对文件进行操作
3.关闭文件
r模式,默认模式,文件不存在则报错
w模式,文件不存在则创建,文件存在则覆盖
a模式,文件不存在则创建,文件存在则不会覆盖,写内容会以追加的方式写(写日志文件的时候常用),追加模式是一种特殊的写模式
b(rb,wb,ab)模式:不用加encoding:utf-8
f=open(‘c.txt‘,‘rb‘) # print(f.read()) print(f.read().decode()) f=open(‘d.txt‘,‘wb‘) f.write(‘啦啦啦‘.encode(‘utf-8‘)) f.close()
1.文件打开模式
文件句柄=open(‘文件路径‘,‘模式’)
打开文件时,需要指定文件路径和以什么方式打开文件。
打开文件的模式有:
# #只读模式f=open(r‘c.txt‘,encoding=‘utf-8‘)print(‘====>1‘,f.read())print(‘====>2‘,f.read())print(f.readable())print(f.readline(),end=‘‘)print(f.readline())print("="*20)print(f.read())print(f.readlines())f.close() #写模式:文件不存在则创建,文件存在则覆盖原有的f=open("new.py",‘w‘,encoding=‘utf-8‘)f.write(‘1111111111\n‘)f.writelines([‘2222\n‘,‘2222548\n‘,‘978646\n‘])f.close() # 追加模式:文件不存在则创建,文件存在不会覆盖,写内容是追加的方式写f=open(‘new.py‘,‘a‘,encoding=‘utf-8‘)f.write(‘nishishui\n‘)f.writelines([‘aa\n‘,‘bb\n‘])f.close()
"+" 表示可以同时读写某个文件
"b"表示以字节的方式操作
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
练习,利用b模式,编写一个cp工具,要求如下:
1. 既可以拷贝文本又可以拷贝视频,图片等文件
# b模式 f=open(‘1.jpg‘,‘rb‘) data=f.read() # print(data) f=open(‘2.jpg‘,‘wb‘) f.write(data) print(data)
1. with open(‘a.txt‘,‘w‘) as f:
pass
2.with open(‘a.txt‘,‘r‘) as read_f,open(‘b.txt‘,‘w‘) as write_f:
data=read_f.read()
write_f.write(data)
import os with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as read_f, open(‘a.txt.swap‘,‘w‘,encoding=‘utf-8‘) as write_f: for line in read_f: write_f.write(line) os.remove(‘a.txt‘) os.rename(‘.a.txt.swap‘,‘a.txt‘)
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
seek控制光标的移动,是以文件开头作为参照的。
tell当前光标的位置
2. truncate是截断文件,截断必须是写模式,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
import time with open(‘test.txt‘,‘rb‘) as f: f.seek(0,2) while True: line=f.readline() if line: print(line.decode(‘utf-8‘)) else: time.sleep(0.2)
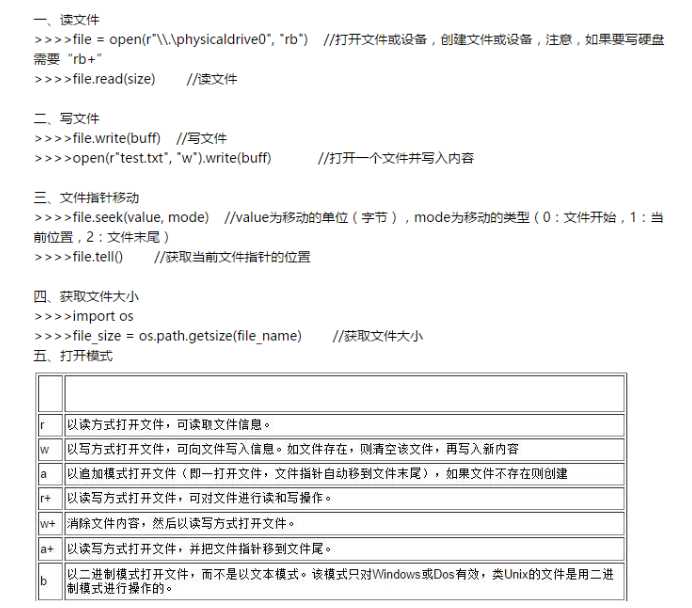
六、练习
# !/usr/bin/env python # -*- coding:utf-8 -*- file_object = open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) # 读取文件所有内容 data = file_object.read() print(data) # 从当前光标所在位置向后读取两个字符 data = file_object.read(2) print(data) #读取文件的所有内容到内存,并按照每一行进行分割到列表中。 data_list = file_object.readlines() print(data_list) #如果以后读取一个特别大的文件 for line in file_object: line = line.strip() print(line) file_object.close() # ########################################### 写操作 file_object = open(‘log.txt‘,mode=‘w‘,encoding=‘utf-8‘) # file_object.write(‘555\n‘) # file_object.write(‘高颖‘) # file_object.close() #练习1:请将user中的元素根据_链接,并写入‘al.txt的文件 user = [‘data‘,‘eric‘] data = ‘_‘.join(user) file_object = open(‘ak.txt‘,mode=‘w‘,encoding=‘utf-8‘) file_object.write(data) file_object.close() #练习2:请将user中的元素根据_链接,并写入到‘al.txt的文件中 user = [{‘name‘:‘alex‘,‘pwd‘:‘123‘}, {‘name‘:‘eric‘,‘pwd‘:‘oldboy‘}] file_object = open(‘a2.txt‘,mode=‘w‘,encoding=‘utf-8‘) for item in user: line = "%s|%s\n" %(item[‘name‘],item[‘pwd‘]) file_object.write(line) file_object.close() #练习3,请将a2.txt中的文件读取并添加到一个列表中[‘alex|123‘,‘eric|oldboy‘] file_obj = open(‘a2.txt‘,mode=‘r‘,encoding=‘utf-8‘) content = file_obj.read() file_obj.close() content=content.strip() data_list = content.split(‘\n‘) print(data_list) result = [] file_obj = open(‘a2.txt‘,mode=‘r‘,encoding=‘utf-8‘) for line in file_obj: line = line.strip() result.append(line) file_obj.close() # print(result)
原文:https://www.cnblogs.com/liuwenhua/p/11629855.html