Embeddings from Language Models 引入了一种新的单词表示方式,该表示方式的建模目标是:对单词的复杂特征建模(如:语法特征、语义特征),以及能适应不同的上下文(如:多义词)。
ELMo 词向量是由双向神经网络语言模型的内部多层向量的线性加权组成。
LSTM 高层状态向量捕获了上下文相关的语义信息,可以用于语义消岐等任务。 结果表明:越高层的状态向量,越能够捕获语义信息。
LSTM 底层状态向量捕获了语法信息,可以用于词性标注等任务。结果表明:越低层的状态向量,越能够捕获语法信息。
ELMo 词向量与传统的词向量(如:word2vec )不同。在ELMo 中每个单词的词向量不再是固定的,而是单词所在的句子的函数,由单词所在的上下文决定。因此ELMo 词向量可以解决多义词问题。
给定一个句子:$\{word_{w1},...,word_{W_N}\}$,其中$w_i$属于$\{1,2,...,V\}$,N为句子的长度,用$(w_1,...,w_N)$表示该句子,则生成该句子的概率为:
![]()
可以用一个L层的前向 LSTM 模型来实现该概率。其中:
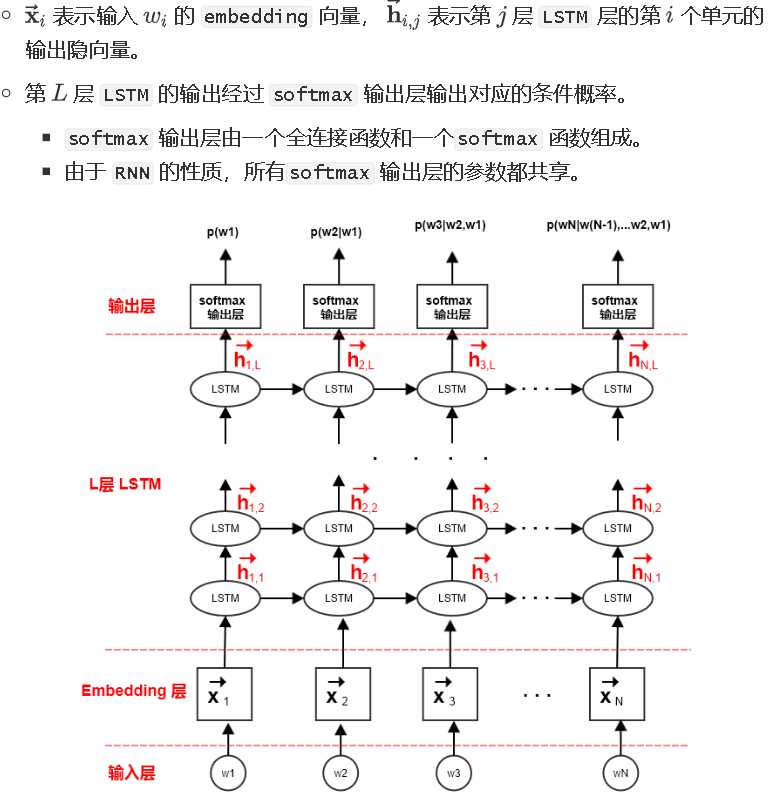
ELMo 模型采用双向神经网络语言模型,它由一个前向LSTM 网络和一个逆向 LSTM 网络组成。ELMo 最大化句子的对数前向生成概率和对数逆向生成概率。
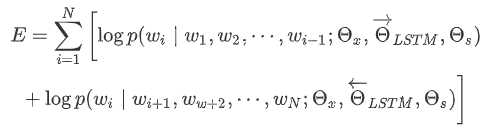

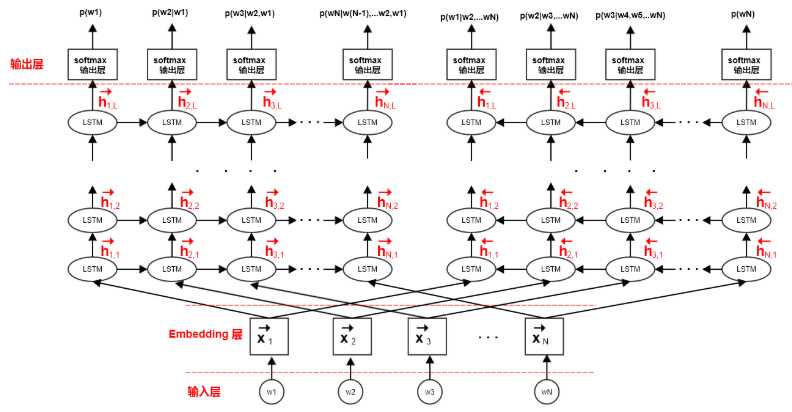
首先训练无监督的 ELMo 模型,获取每个单词的 个中间表示。然后在监督学习任务中,训练这 个向量的线性组合,方法为:

实验表明:在 ELMo 中添加 dropout 是有增益的。另外在损失函数中添加 正则化能使得训练到的ELMo权重倾向于接近所有ELMo权重的均值。
参考文献:
【1】词的表达 --- huaxiaozhuan
原文:https://www.cnblogs.com/nxf-rabbit75/p/11635547.html