特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
直接影响模型的预测结果

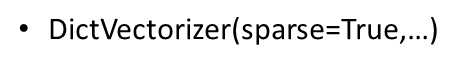

1 from sklearn.feature_extraction import DictVectorizer 2 3 4 5 def dict_vec(): 6 """ 7 字典数据,特征抽取 8 :return: None 9 """ 10 # 实例化 11 d = DictVectorizer(sparse=False) # 有无sparse参数返回的数据类型不一样 12 # 调用 fit_transform 13 data = d.fit_transform([{‘city‘: ‘北京‘, ‘temperature‘: 100}, {‘city‘: ‘上海‘, ‘temperature‘: 60}, {‘city‘: ‘深圳‘, ‘temperature‘: 80}]) 14 print(d.get_feature_names()) 15 print(data) 16 return None 17 18 # 字典数据抽取:把字典中一些类别数据,分别进行转换成特征 19 if __name__ == ‘__main__‘: 20 dict_vec()
输出结果:
[‘city=上海‘, ‘city=北京‘, ‘city=深圳‘, ‘temperature‘]
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 80.]]
原文:https://www.cnblogs.com/springionic/p/11637509.html