1.源代码目录
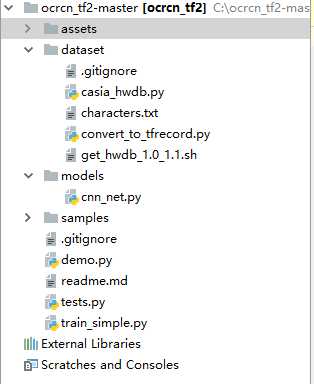
(1)assets:部分训练样本与输出结果;
(2)dataset:手写中文汉字的数据集,以及对数据进行处理的操作;
(3)models:训练样本所定义的cnn模型;
(4)samples:项目的主要代码,训练数据;
(5)train_simple:训练公开数据库中手写单子;
(6)tests:文件为空,作者编写应该有点问题。
2.列举哪些做法符合代码规范和风格一般要求
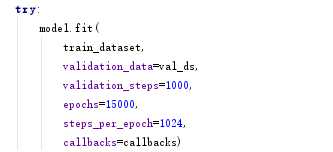
函数命名能较直观的看出函数的功能,如use_keras_fit,可以看出是使用keras进行拟合训练。
各个变量的命名比较符合阅读的习惯,如steps_per_epoch每次迭代的步长,整体的命名都是这样,很清晰。让人可以从函数名读出其作用,方便学习,大部分函数命名采取下划线连接相关词的形式。这也是我们编码时应当学会的,尽量避免使用指向不明的变量、函数名,这样也有利于后来的人阅读,维护代码。
3.列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进
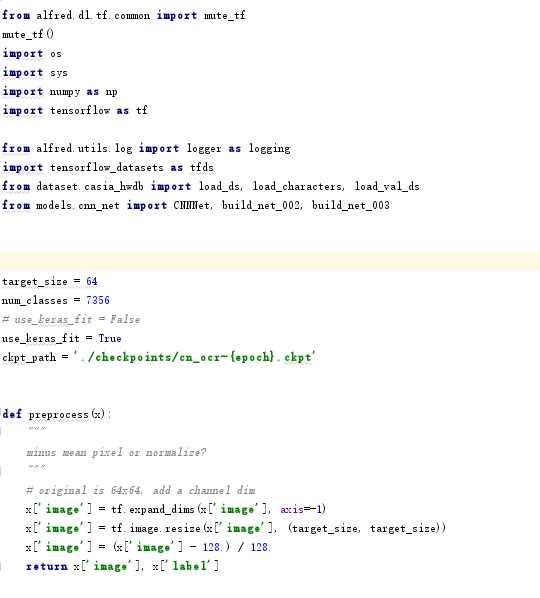
项目里有tests.py文件,但是是空的,而且整体的代码没有注释,有些地方会让人读起来十分困惑。
虽然命名比较直观,但是有些细节的地方还是打上注释比较好,让人一眼就可以看懂。
4.总结同类编程语言或项目在代码规范和风格的一般要求
1、编码
如无特殊情况, 文件一律使用 UTF-8 编码
如无特殊情况, 文件头部必须加入#--coding:utf-8--标识
2、代码格式
2.1、缩进
统一使用 4 个空格进行缩进
2.2、行宽
每行代码尽量不超过 80 个字符(在特殊情况下可以略微超过 80 ,但最长不得超过 120)
理由:
这在查看 side-by-side 的 diff 时很有帮助
方便在控制台下查看代码
太长可能是设计有缺陷
2.3、引号
简单说,自然语言使用双引号,机器标示使用单引号,因此 代码里 多数应该使用 单引号
自然语言 使用双引号 “…”
例如错误信息;很多情况还是 unicode,使用u”你好世界”
机器标识 使用单引号 ‘…’
例如 dict 里的 key
正则表达式 使用原生的双引号 r”…”
文档字符串 (docstring) 使用三个双引号 “”“……”“”
模块级函数和类定义之间空两行;
类成员函数之间空一行;
原文:https://www.cnblogs.com/jiahuich/p/11668414.html