| 字符组 | 具体含义 | 记忆方式 |
|---|---|---|
| \d | 表示 [0-9]。表示是一位数字。 | 其英文是 digit(数字) |
| \D | 表示 [^0-9]。表示除数字外的任意字符。 | |
| \w | 表示 [0-9a-zA-Z_]。表示数字、大小写字母和下划线。 | w 是 word 的简写,也称单词字符。 |
| \W | 表示 [^0-9a-zA-Z_]。非单词字符。 | |
| \s | 表示 [ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页 符。 | s 是 space 的首字母,空白符的单词是 white space。 |
| \S | 表示 [^ \t\v\n\r\f]。 非空白符。 | |
| . | 表示 [^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符 除外。 | 想想省略号 ... 中的每个点,都可以理解成占位符,表示任何类似的东西。 |
| [\d\D]/[\w\W]/[\s\S]/[^] | 任意字符 |
| 字符组 | 具体含义 | 记忆方式 |
|---|---|---|
| {m, } | 至少出现m次 | |
| {m} | 等价于{m, m}, 出现m次 | |
| ? | 等价于{0, 1}, 出现或者不出现 | 问号的意思: 有么? |
| + | 等价于{1, }, 表示至少出现一次 | 加号是追加的意思,表示必须现有一个,然后才考虑追加 |
| * | 等价于{0, }, 出现任意次, 有可能不出现 | 看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来 |
| 字符组 | 具体含义 | 记忆方式 |
|---|---|---|
| g | 匹配全局 | 单词是global |
| i | 忽略字母大小写 | 单词是ignoreCase |
| m | 多行匹配, 只影响 ^ 和 $,二者变成行的概念,即行开头和行结尾 | 单词是multiline |
| 字符组 | 具体含义 | 记忆方式 |
|---|---|---|
| ^ | (脱字符)匹配开头 | |
| $ | (美元符号)匹配结尾 | |
| \b | 单词边界 | \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置 |
| \B | 非单词边界 | |
| (?=p) | "p"的子模式, "p" 前面的位置 | positive lookahead(正向先行断言) |
| (?!p) | 非"p"前的位置 | negative lookahead(负向先行断言) |
/^|$/g: 匹配列/^|$/gm: 匹配行, m是既有修饰符
(?<=p): positive lookbehind(正向后行断言)(?<!p): negative lookbehind(负向后行断言)
1234567890
/(?=\d{3}$)/g
(?=p): 正向先行断言/(?=(\d{3})+$)/g
+: 量词, 多个/(?!^)(?=(\d{3})+$)/g
(?!^): 负向先行断言/\B(?=(?:\d{3})+(?!\d))/g
123456789 123456789
/(?!\b)(?=(\d{3})+\b)/g,即/(\B)(?=(\d{3})+\b)/g^和$要替换成\bfunction format (num) { return num.toFixed(2).replace(/\B(?=(\d{3})+\b)/g, ",").replace(/^/, "$$ "); }; console.log( format(1888) ); // => "$ 1,888.00"/^[0-9a-zA-Z]{6, 12}$//(?=.*[0-9])//((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9a-zA-Z]{6,12}$/
{6,12}中间不能有空格/(?!^[0-9]{6,12}$)(^[0-9a-zA-Z]{6,12})/正则: /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)(^[0-9a-zA-Z]{6,12}$)/
| 词法 | 含义 | 记忆方式 |
|---|---|---|
| (?=.[A-Z]) / (?=.?[A-Z]) / (.*[A-Z]) | 至少包含一个大写字母 |
‘ababa abbb ababab‘.match(/(ab)+/g)(p1|p2)
示例
var regex = /^I love (JavaScript|Regular Expression)$/ console.log(regex.test("I love JavaScript")) // true console.log(regex.test("I love Regular Expression")) // true
/^d{4}-d{2}-d{2}$//^(d{4})-(d{2})-(d{2})$/‘2017-06-12‘.match(/(\d{4})-(\d{2})-(\d{2})/)["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12", groups: undefined]
g之后, 返回的是一个数组
‘1s1‘.match(/\d/g) => ["1", "1"]null/(\d{4})-(\d{2})-(\d{2})/.exec(‘2017-06-12‘)test/match/exec)之后, 可以通过RegExp的$0~$9获取yyyy-mm-dd为dd/mm/yyyy
$方法‘2019-09-23‘.replace(/(\d{4})-(\d{2})-(\d{2})/, ‘$2/$3/$1‘)RegExp.$+function方法‘2019-09-23‘.replace(/(\d{4})-(\d{2})-(\d{2})/, function() { return `${RegExp.$2}/${RegExp.$3}/${RegExp.$1}` })function方法
‘2019-09-23‘.replace(/(\d{4})-(\d{2})-(\d{2})/, function(match, year, month, day) { return `${month}/${day}/${year}` })
\12019-09-24, 2019/09/24, 2019.09.24
/\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/2019/09-24同样能匹配/\d{4}(-|\/|\.)\d{2}(\1)\d{2}/\2是第二个分组引用, 依次类推// ["1231231233", "123", "1", "23", "3", index: 0, input: "1231231233", groups: undefined] 1231231233‘.match(/^((\d)(\d(\d)))\1\2\3\4$/)/^((\d)(\d(\d)))$/.test(‘123‘) // true/^(\d)$/.test(‘1‘) // true/^(\d(\d))$/.test(‘23‘) // true/^(\d)$/.test(‘3‘) // true, 同第二个一样/\1/.test(‘\1‘) // true‘12345‘.match(/(\d)+/) // ["12345", "5", index: 0, input: "12345", groups: undefined]/(\d)+ \1/.test(‘12345 5‘) // true(?:p)非捕获匹配到的值不会保存起来
举例
‘ababa abbb ababab‘.match(/(?:ab)+/g) // ["abab", "ab", "ababab"] var regex = /^I love (?:JavaScript|Regular Expression)$/ regex.test("I love JavaScript") // true regex.test("I love Regular Expression") // true
‘ hello ‘.trim() // ‘hello‘‘ hello ‘.replace(/^\s+|\s+$/g, ‘‘)惰性匹配*?, 匹配所有字符串, 提取相应数据
‘ hello ‘.replace(/^\s*(.*?)\s*$/, ‘$1‘) // ‘hello‘
function titleize (str) { return str.toLowerCase().replace(/(?:^|\s)\w/g, function (c) { return c.toUpperCase(); }); } // My Name Is Epeli console.log( titleize(‘my name is epeli‘) )\s: 制表符空格等, 用来匹配name这样的数据var camelize = function(str) { return str.replace(/[-_\s]+(.)?/g, function(match, c){ return c ? c.toUpperCase() : ‘‘ }) } console.log(camelize(‘-moz-transform‘))match: 匹配到的字符串p1,p2,...: 代表第n个括号匹配到的字符串offset: 匹配到字符串在原字符串的偏移量string: 被匹配的原字符串NamedCaptureGroup: 命名捕获组匹配的对象[-_\s]: 连字符、下划线和空白符?: 应对单词结尾不是单词字符, 例如‘-moz-transform ‘var dasherize = function(str) { return str.replace(/([A-Z])/g, ‘-$1‘).replace(/[-_\s]+/g, ‘-‘).toLowerCase() } console.log(dasherize(‘MozTTransform‘))或者使用function
var sperateLine = function(str) { return str.replace(/[A-Z]{1}/g, function(match) { return match ? `-${match.toLowerCase()}` : ‘‘ }) } console.log(sperateLine(‘MozTTransform‘))
var escapeHTML = function(str) { var escapeChars = { ‘<‘: ‘lt‘, ‘>‘: ‘gt‘, ‘"‘: ‘quot‘, ‘&‘: ‘amp‘, ‘\‘‘: ‘#39‘ } return str.replace(new RegExp(`[${Object.keys(escapeChars).join(‘‘)}]`, ‘g‘), function(match) { return `&${escapeChars[match]};` }) } console.log(escapeHTML(‘<div>hello, \‘world\‘</div>‘))var unescapeHTML = function(str) { var htmlEntities = { ‘lt‘: ‘<‘, ‘gt‘: ‘>‘, ‘quot‘: ‘"‘, ‘amp‘: ‘&‘, ‘#39‘: ‘\‘‘ } return str.replace(new RegExp(`\&([^;]+);`, ‘g‘), function(match, key) { console.log(match, key) return (key in htmlEntities) ? htmlEntities[key] : match }) } console.log(unescapeHTML(‘<div>hello, 'world'</div>‘))/\&([^;]+);/g中^
^本身,使用\^
/<([^>]+)>[\d\D]*<\/\1>//<([^>]+)>[\d\D]*<\/\1>/.test(‘<title>wrong!</p>‘) // false/ab{1,3}c/.test(‘abbbc‘)/ab{1,3}c/.test(‘abbc‘)// .*任意字符出现任意次, 会匹配到abc"de, 匹配完之后发现还有"正则, 然后会回溯,只匹配到abc /".*"/.test(‘"abc"de‘) // 更改建议, 匹配非"的字符任意次, 碰到"就终止匹配, 减少回溯, 提高效率 /"[^"]*"/.test(‘"abc"de‘)百度百科
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发 所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从 另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、 不断“回溯”寻找解的方法,就称作“回溯法”。
// ["12345", "123", "45", index: 0, input: "12345", groups: undefined] ‘12345‘.match(/(\d{1,3})(\d{1,3})/)// ["1234", "1", "234", index: 0, input: "12345", groups: undefined] ‘12345‘.match(/(\d{1,3}?)(\d{1,3})/)// ["12345", index: 0, input: "12345", groups: undefined] ‘12345‘.match(/^\d{1,3}?\d{1,3}$/)// ["can", index: 0, input: "candy", groups: undefined] ‘candy‘.match(/can|candy/)// ["candy", index: 0, input: "candy", groups: undefined] ‘candy‘.match(/^(?:can|candy)$/)流行原因: 编译快, 有趣?
/a/匹配字符‘a‘; 转义: /\n/匹配换行符, \.匹配小数点 |/[0-9]/表示匹配一个数字, 简写形式/\d/; [^0-9]表示匹配一个非数字, 简写形式/\D/ |/a{1,3}/表示a字符连续出现1~3次; /a+/表示a出现至少一次 |^表示匹配位置的开头, \b表示匹配单词边界, (?=\d)表示数字的前面 |(ab)+表示ab两个字符连续出现多次, 也可以使用非捕获组(?:ab)+ |abc|bcd表示匹配‘abc‘或者‘bcd‘字符子串; \2表示引用第2个分组 |操作符(从上至下)
| 操作符描述 | 操作符 | 优先级 |
| - | - | - |
| 转义符 | \ | 1 |
| 括号和方括号 | (...)、(?:...)、(?=...)、(?!...)、[...] | 2 |
| 量词限定符 | {m}、{m,n}、{m,}、?、*、+ | 3 |
| 位置和序列 | ^、$、\元字符、一般字符 | 4 |
| 管道符(竖杠) | | | 5 |
/ab?(c|de*)+|fg//^abc|bcd$/
/^(abc|bcd)$/
‘a‘,‘b‘,‘c‘任选其一, 字符串长度是3的倍数
错误示例: /^[abc]{3}+$/
会报错, 说
+前没有什么可重复的
/([abc]{3})+/
/\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,/.test(‘^$.*+?|\\/[]{}=!:-,‘)// true ‘^$.*+?|\\/[]{}=!:-,‘ === ‘\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,‘
[、]、 ^、 -。因此在会引起歧义的地方进行转义, 例如^, 否则会把整个字符组看成反义字符组‘^$.*+?|\\/[]{}=!:-,‘.match(/[\^$.*+?|\\/\[\]{}=!:\-,]/g)‘[abc]‘和{3,5}/\[abc]/.test(‘[abc]‘) /\{3,5}/.test(‘{3,5}‘) /{,3}/.test(‘{,3}‘)
=, !, :, -, ,不在特殊结构, 不需要转义/\(123\)/^, $, ., *, +, ?, |, \, /等字符, 只要不在字符组内, 都需要转义/^(\d{15}|\d{17}[\dxX])$//^((0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])$/
((...)\.){3}(...)3位数.3位数.3位数.3位数0{0,2}\d: 匹配0~9 // 或 00~09 // 或 000~0090?\d{2}: 匹配10~99 // 或 010~0991\d{2}: 匹配100~1992[0-4]\d: 匹配200~24925[0-5]: 匹配250~255
‘1010010001...‘var string = ‘2017-07-01‘ // 正则 var reg = /^(\d{4})-(\d{2})-(\d{2})/ console.log(string.match(reg)) // js api var stringArray = string.split(‘-‘) console.log(stringArray)var string = ‘?id=xx&act=search‘ // 正则 console.log(string.search(/\?/)) // js api console.log(string.indexOf(‘?‘))var string = ‘JavaScript‘ // 正则 var reg = /.{4}(.+)/ console.log(string.match(reg)[1]) // js api console.log(string.substring(4))/(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/var regex1 = /^[0-9a-zA-Z]{6,12}$/ var regex2 = /^[0-9]$/ var regex3 = /^[a-z]$/ var regex4 = /^[A-Z]$/ function checkPassword = function(string) { if (!regex1.test(string) return false if (regex2.test(string)) return false if (regex3.test(string)) return false if (regex4.test(string)) return false return true }055188888888、0551-88888888、(0551)88888888+86)
/0\d{2,3}//[1-9]\d{6,7}/055188888888, 正则: /^0\d{2,3}[1-9]\d{6,7}$/0551-88888888, 正则: /^0\d{2,3}-[1-9]\d{6,7}$/(0551)88888888, 正则: /^\(0\d{2,3}\)[1-9]\d{6,7}$/^/0\d{2,3}[1-9]\d{6,7}|0\d{2,3}-[1-9]\d{6,7}|\(0\d{2,3}\)[1-9]\d{6,7}$//^(0\d{2,3}|0\d{2,3}-|\(0\d{2,3}\))[1-9]\d{6,7}$//^(0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/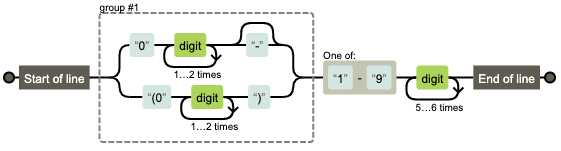
/^(0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/.test(‘055188888888‘) /^(0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/.test(‘0551-88888888‘) /^(0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/.test(‘(0551)88888888‘) /^(0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/.test(‘051-8888888‘)1.23、+1.23、-1.23、10、+10、-10、.2、+.2、-.2[+-]\d+\.\d+1.23、+1.23、-1.23正则: /^[+-]?\d+\.\d+$/10、+10、-10正则: /^[+-]?\d+$/.2、+.2、-.2正则: /^[+-]?\.\d+$//^[+-]?(\d+\.\d+|\d+|\.\d+)$/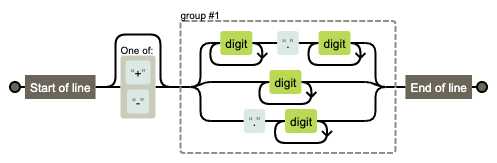
另外一种写法: /^[+-]?(\d+)?(\.)?\d+$/
涉及到可维护性和可读性
编译
引擎报错与否在这个阶段
尝试匹配
可以优化的阶段
匹配失败,从下一位开始继续第3步
可以优化的阶段
运行代码示例
var regex = /\d+/g; // 0 ["123", index: 0, input: "123abc34def", groups: undefined] console.log( regex.lastIndex, regex.exec("123abc34def") ); // 3 ["34", index: 6, input: "123abc34def", groups: undefined] console.log( regex.lastIndex, regex.exec("123abc34def") ); // 8 null console.log( regex.lastIndex, regex.exec("123abc34def") ); // 0 ["123", index: 0, input: "123abc34def", groups: undefined] console.log( regex.lastIndex, regex.exec("123abc34def") );
当使用
test和exec时, 正则有g时, 起始位置是从lastIndex开始的
/".*"/.test(‘123"abc"456‘): 回溯有4次/".*?"/.test(‘123"abc"456‘): 回溯有2次
*?/"[^"]*"/.test(‘123"abc"456‘): 无回溯使用非捕获分组
不需要使用分组引用和反向引用时
/^[+-]?(\d+\.\d+|\d+|\.\d+)$/=>/^[+-]?(?:\d+\.\d+|\d+|\.\d+)$//a+/ => /aa*/提取公共分支部分
可减少匹配过程中的重复
/^abc|^bcd/ => /^(abc|bcd)//this|that/ => /th(?:is|at)//red|read/ => /rea?d/: 可读性降低提取公共部分
,分隔的字符串// ["html", "js", "css"] ‘html,js,css‘.split(/,/)// ["2019", "10", "11"] ‘2019/10/11‘.split(/\D/) ‘2019.10.11‘.split(/\D/) ‘2019-10-11‘.split(/\D/)‘2019-10-11‘.search(/^(\d{4})\D(\d{2})\D(\d{2})$/) // 2019 10 11 console.log(RegExp.$1, RegExp.$2, RegExp.$3)// ["2019-10-11", "2019", "10", "11", index: 0, input: "2019-10-11", groups: undefined] ‘2019-10-11‘.match(/^(\d{4})\D(\d{2})\D(\d{2})$/)var date = [] ‘2019-10-11‘.replace(/^(\d{4})\D(\d{2})\D(\d{2})$/, function(year, month, day) { date.push(year, month, day) }) // ["2019-10-11", "2019", "10"] console.log(date)/^(\d{4})\D(\d{2})\D(\d{2})$/.test(‘2019-10-11‘) // 2019 10 11 console.log(RegExp.$1, RegExp.$2, RegExp.$3)/^(\d{4})\D(\d{2})\D(\d{2})$/.exec(‘2019-10-11‘) // 2019 10 11 console.log(RegExp.$1, RegExp.$2, RegExp.$3)var tody = new Date(‘2019-10-11‘.replace(/-/g, ‘/‘)) // Fri Oct 11 2019 00:00:00 GMT+0800 (China Standard Time) console.log(tody)search和match会把字符串转成正则// 0 ‘2019.10.11‘.search(‘.‘) // ["2", index: 0, input: "2019.10.11", groups: undefined] ‘2019.10.11‘.match(‘.‘) // 4 ‘2019.10.11‘.search(‘\\.‘) // [".", index: 4, input: "2019.10.11", groups: undefined] ‘2019.10.11‘.match(‘\\.‘) // 4 ‘2019.10.11‘.search(/\./) // [".", index: 4, input: "2019.10.11", groups: undefined] ‘2019.10.11‘.match(/\./) // "2019/10.11" ‘2019.10.11‘.replace(‘.‘, ‘/‘)match返回的格式问题: 与是否有修饰符g有关// ["2019", "2019", index: 0, input: "2019.10.11", groups: undefined] console.log(‘2019.10.11‘.match(/\b(\d+)\b/)) // ["2019", "10", "11"] console.log(‘2019.10.11‘.match(/\b(\d+)\b/g))exec比match更强大: match使用g之后, 没有关键信息index, exec可以解决这个问题, 并且接着上一次继续匹配var string = "2019.10.11"; var regex2 = /\b(\d+)\b/g; // ["2019", "2019", index: 0, input: "2019.10.11", groups: undefined] console.log( regex2.exec(string) ); // 4 console.log( regex2.lastIndex); // ["10", "10", index: 5, input: "2019.10.11", groups: undefined] console.log( regex2.exec(string) ); // 7 console.log( regex2.lastIndex); // ["11", "11", index: 8, input: "2019.10.11", groups: undefined] console.log( regex2.exec(string) ); // 10 console.log( regex2.lastIndex); // null console.log( regex2.exec(string) ); // 0 console.log( regex2.lastIndex);
对使用exec用法优化
示例中
lastIndex表示下次匹配的开始位置
var string = '2019.10.11'
var regex = /\b(\d+)\b/g
var result
while (result = regex.exec(string)) {
console.log(result, regex.lastIndex)
}g对exec和test的影响
lastIndex属性始终不变var regex = /a/g ‘a‘.search(regex) // 0 console.log(regex.lastIndex) ‘ab‘.search(regex) // 0 console.log(regex.lastIndex)exec和test方法, 当正则含有g, 每次匹配都会更改lastIndex; 不含g, 则不会改变lastIndexvar regex = /a/g // true 1 console.log( regex.test(‘a‘), regex.lastIndex ) // true 3 console.log( regex.test(‘abac‘), regex.lastIndex ) // false 0 console.log( regex.test(‘abacd‘), regex.lastIndex )test整体匹配时需要^和$
test是看目标字符串中是否有子串符合条件
// true
/123/.test('a123b')
// false
/^123$/.test('a123b')
// true
/^123$/.test('123')split相关事项
// ["js", "css"] ‘js,css,html‘.split(/,/, 2)// ["js", ",", "css", ",", "html"] ‘js,css,html‘.split(/(,)/)replace很强大
第二个参数是字符串时, 有如下含义
| 属性 | 描述 |
| - | - |
| $1,$2,...,$99 | 匹配第1~99个分组里捕获到的文本 |
| $& | 匹配到的子串文本 |
| $` | 匹配到的子串左边的文本 |
| $‘ | 匹配到的子串右边的文本 |
| $$ | 美元符号 |
2,3,5变成5=2+3// "5=2+3" ‘2,3,5‘.replace(/(\d+),(\d+),(\d+)/, ‘$3=$1+$2‘)2,3,5变成222,333,555‘2,3,5‘.replace(/(\d+)/g, ‘$&$&$&‘)2+3=5变成2+3=2+3=5=5// "2+3=2+3=5=5" ‘2+3=5‘.replace(/(=)/, "$&$`$&$‘$&")第二个参数是函数时
replace此时拿到的信息比exec多
// ["1234", "1", "4", 0, "1234 2345 3456"]
// ["2345", "2", "5", 5, "1234 2345 3456"]
// ["3456", "3", "6", 10, "1234 2345 3456"]
"1234 2345 3456".replace(/(\d)\d{2}(\d)/g, function (match, $1, $2, index, input) {
// $1是每组数字的开始
// $2是每组数字的结束
console.log([match, $1, $2, index, input]);
})使用构造函数需要注意的问题
不推荐使用, 会写很多的
\
// ["2017-06-27", "2017.06.27", "2017/06/27"]
'2017-06-27 2017.06.27 2017/06/27'.match(/\d{4}(-|\.|\/)\d{2}\1\d{2}/g)
// ["2017-06-27", "2017.06.27", "2017/06/27"]
'2017-06-27 2017.06.27 2017/06/27'.match(new RegExp('\\d{4}(-|\\.|\\/)\\d{2}\\1\\d{2}', 'g'))修饰符
| 修饰符 | 描述 | 单词 |
| - | - | - |
| /g/ | 全局匹配(找到所有的) | global |
| /i/ | 忽略字母大小写 | ignoreCase |
| /m/ | 多行匹配, 只影响^和$, 二者变成行概念(行开头、行结尾) | multiline |
var regex = /\w/img // true console.log(regex.global) // true console.log(regex.ignoreCase) // true console.log(regex.multiline)source属性
对象属性, 除了
global,ignoreCase,multiline,lastIndex还有source属性; 用来构建动态正则, 或确认真正的正则
var className = "high";
// => (^|\s)high(\s|$)
// => 即字符串"(^|\\s)high(\\s|$)"
var regex = new RegExp("(^|\\s)" + className + "(\\s|$)"); console.log( regex.source )
console.log(regex.test(' high '), regex.test('high'))构造函数属性
静态属性随着最后一次正则操作而变化, 除了
$1,...$9, 还有几个不太常用的(有兼容问题)
| 静态属性 | 描述 | 简写形式 |
|---|---|---|
RegExp.input |
最近一次目标字符串 | RegExp[‘$_‘] |
RegExp.lastMatch |
最近一次匹配的文本 | RegExp[‘$&‘] |
RegExp.lastParen |
最近一次捕获的文本 | RegExp[‘$+‘] |
RegExp.leftContext |
目标匹配lastMatch之前的文本 | RegExp[‘$‘] | |RegExp.rightContext` |
```
var regex = /([abc])(\d)/g
var string = ‘a1b2c3d4e5‘
string.match(regex)
// a1b2c3d4e5 a1b2c3d4e5
console.log(RegExp.input, RegExp[‘$_‘])
// c3 c3
console.log(RegExp.lastMatch, RegExp[‘$&‘])
// 3 3
console.log(RegExp.lastParen, RegExp[‘$+‘])
// a1b2 c3
console.log(RegExp.leftContext, RegExp[‘$&‘])
// d4e5 d4e5
console.log(RegExp.rightContext, RegExp["$‘"])
```
function getClassByName(className) { var elements = document.getElementByTagName(‘*‘) var regex = new RegExp(‘(^|\\s)‘ + className + ‘($|\\s)‘) var result = [] var elementsLength = elements.length for (var i = 0; i < elementsLength; i++) { var element = elements[i] if (regex.test(element.className)) { result.push(element) } } return result }var utils = {} ‘Boolean|Number|String|Function|Array|Date|RegExp|Object|Error‘.split(‘|‘).forEach(function(item) { utils[‘is‘ + item] = function(obj) { return {}.toString.call(obj) === ‘[object ‘+ item +‘]‘ } }) console.log(utils.isArray([1, 2, 3]))var readyRegex = /complete|loaded|interactive/ function ready(callback) { if (readyRegex.test(document.readyState) && document.body) { callback() } else { document.addEventListener(‘DomContentLoaded‘, function() { callback() }, false) } }function compress(source) { var keys = {} // [^=&]中的&不能去掉, 否则第二次会匹配成&b=2 // key不能为空, value有可能为空, 所以第一次是+, 第二次是* source.replace(/([^=&]+)=([^&])*/g, function(full, key, value) { keys[key] = (keys[key] ? keys[key] + ‘,‘ : ‘‘) + value }) var result = [] for (var key in keys) { result.push(key + ‘=‘ + keys[key]) } return result.join(‘&‘) } // a=1,3&b=2,4 console.log(compress(‘a=1&b=2&a=3&b=4‘))根据字符串生成正则
function createRegex(regex) { try { if (regex[0] === ‘/‘) { regex = regex.split(‘/‘) regex.shift() var flags = regex.pop() regex = regex.join(‘/‘) regex = new RegExp(regex, flags) } else { regex = new RegExp(regex, ‘g‘) } return { success: true, result: regex } } catch (e) { return { success: false, message: ‘无效的正则表达式‘ } } } // {success: true, result: /\d/gm} console.log(createRegex(‘/\\d/gm‘)) // {success: true, result: /\d/g} console.log(createRegex(‘/\\d/g‘))
原文:https://www.cnblogs.com/muzi131313/p/11676936.html