首先,我们先看学c/c++时候学到的程序内存布局
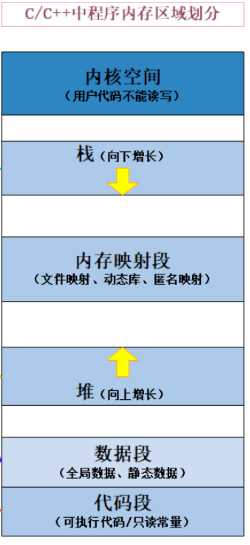
准确地说,程序地址空间其实就是进程的地址空间,实际就是pcb中的mm_struct。

接下来,我们用fork()演示一下进程的地址空间。
//父子进程数据独有demo
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<unistd.h> 4 5 int g_val = 10; 6 int main() 7 { 8 int pid=fork(); 9 if(pid < 0) 10 { 11 return -1; 12 }else if(pid == 0) 13 { 14 //child 15 g_val = 100; 16 printf("child val: %d--%p\n",g_val,&g_val); 17 } 18 else 19 { 20 //parent 21 sleep(1); 22 printf("parent val:%d--%p\n",g_val,&g_val); 23 } 24 return 0; 25 }
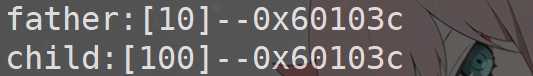
很容易看出,父子进程的地址是一样的,但是变量的值却不一样。
由此能推出 : 我们所看到的地址并不是真实的物理地址。
Linux下,我们称作为虚拟地址。
说明进程访问的地址都是虚拟地址,物理地址我们用户是看不到的,由操作系统负责物理地址和虚拟地址的转换。
通过上面测试,我们肯定要问,为什么要使用虚拟地址呢?
1.增加内存访问控制 --- 计算机界有一句名言: "计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决",如果让程序员自己直接控制内存的访问与操作,那么是人就会犯错,不如交给操作系统管理内存,大大减轻了程序员的负担。
2.提高内存利用率 --- 直接使用物理内存,很容易造成空闲的内存碎片,操作系统用通过分页式内存管理提高了物理内存的利用。
3.保证进程独立性 --- 有了虚拟地址,进程都可以拥有自己的一套虚拟地址,能让程序员更好地编码。
既然虚拟地址这么好用,那来看看它的实现原理吧!
在Linux下,OS使用的是分页式内存管理
内存分页:
为什么要有分页 --- 物理地址和虚拟地址的分离,给进程带来了安全和便利,但是他们之间的转换如果是按字节一一对应记录的,那么要消耗的额外资源就太多了,于是,分页出现了。
分页是什么 --- 以更大尺寸的单位页来管理内存,这个单位页负责物理地址与虚拟地址的映射关系,Linux中通常每页大小为4KB。下面是我Linux下测出的大小。
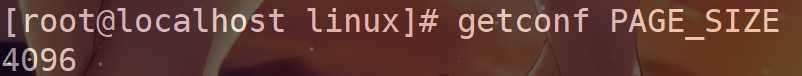
分页的原理 --- 因为物理页和虚拟页内地址肯定是连续的,所以页内数据可以按顺序一一对应。
因为页表大小都是一样的,所以页内数据的末尾地址都是相同的(二进制下后12位都为1),我们把这个地址称之为偏移量。
偏移量实际上表达了该字节在页内的位置。
地址的前一部分则是页编号,后一部分是页内偏移。
操作系统只需要记录页编号的对应关系。
虚拟页编号在页表中找到对应的物理页表编号,再计算出页内偏移,就可得到实际物理地址。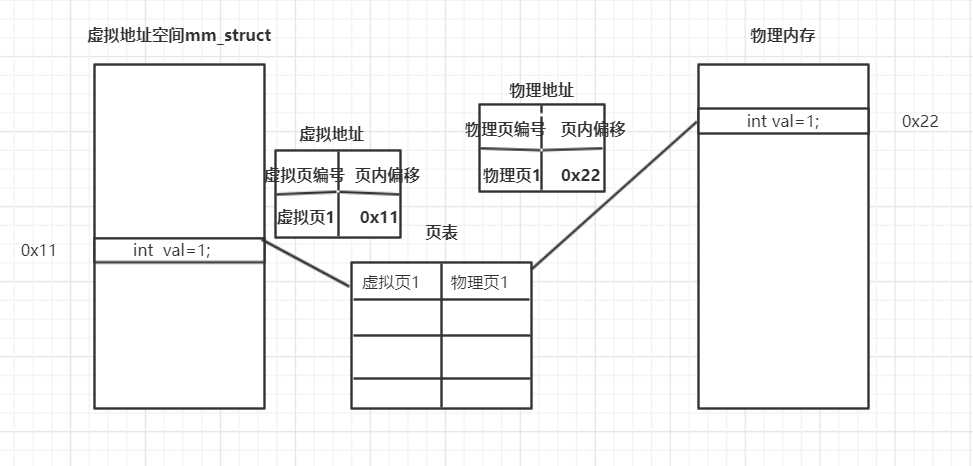
分页优化: 多级分页表 --- 分页让我们将逻辑地址和物理地址分离,能更好的进行内存管理。
我们知道进程都会有一套虚拟内存地址(mm_struct),那么其中肯定包含了分页表保存所有分页,为了保证查询效率,分页表会保存于内存中。
并且,堆栈上有很多空间都是进程预留的,意味着如果使用连续分页表,很多条目都没有真正用到。
因此,Linux中的分页表,采用了多层的数据结构。多层的分页表能够减少所需的空间。
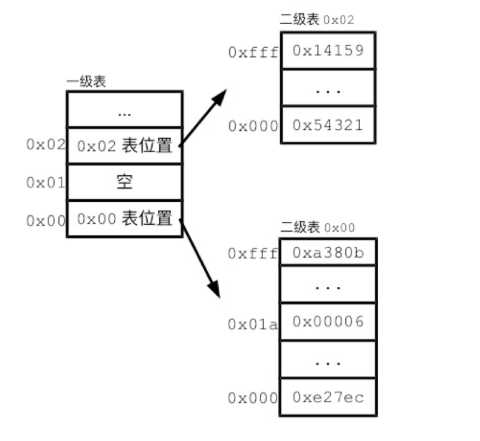
用上图的二级表结构举个例子,页编号被分为两级:
一级表: 一级页编号保存地址的前8位(十六进制2位),一级表负责映射该地址下的二级表地址。
二级表: 二级表编号保存地址的后12位(十六进制3位),二级表负责映射该地址下的物理地址。
上面我们了解到,连续的分页表可以直接通过虚拟页编号找到物理页编号,而二级分页表,我们要先拿出虚拟页编号前8位编号在一级表中找到对应的二级表,再拿出虚拟页编号后12位在二级表找到对应的物理地址。就像身份证号,每个地区的前6位都是一样的,如果要查某人的身份证号,先查地区,再查人,能大大减少查找量,如上图0x01为空,说明这个地区没人,那么相应的二级表也不需要存在。这样,二级表所占数据就会比连续单页表少多了。
二级表还有一个优点: 因为是多层结构,所以不必像单层表一样占据一整块内存,而是可以存于不同位置,提高内存利用率。

原文:https://www.cnblogs.com/Duikerdd/p/11670292.html