一、Github与源代码
https://github.com/wuchengttt/hello-world
源代码
主函数
int main() { //检测是否存在这两个文件,如果没有就新建 FILE *fp; fp = fopen("Exercises.txt", "w+"); fclose(fp); fp = fopen("Answers.txt", "w+"); fclose(fp); int range = 0; printf("请输入产生几以内的数字:"); scanf_s("%d", &range); printf("\n请输入产生多少个运算表达式:"); scanf_s("%d", &num); int right1 = 0; int wrong1 = 0; char(*result)[LENGTH] = (char(*)[LENGTH])malloc(sizeof(char)*LENGTH*num); int i; for (i = 1; i <= num; i++) {//随机生成四个数字 //char expArr[2];//定义生成的题目 int a = (int)(random(range));//分子 int b = (int)(random(range));//分母 int c = (int)(random(range));//另一个分子 int d = (int)(random(range));//另一个分母 int fuhao;//运算符 fuhao = (int)(random(4)); product_exp(a, b, c, d, fuhao, i, *result + i);//进入处理函数 } free(result); printf("\n回答完成请按回车"); getchar(); getchar(); check1(); system("pause"); return 0; }
主函数创建txt文本,并且调用生成表达式函数,最后可以进行答案检查
整数型转字符型函数
void myitoa(int num_i, char *str) { int j = 0, i = 0; char number[10] = { ‘0‘,‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘ }; char temp[10] = { 0 }; while (num_i != 0) { temp[i] = number[num_i % 10]; i++; num_i = num_i / 10; } temp[i] = ‘\0‘; i = i - 1; while (i >= 0) { str[j] = temp[i]; j++; i--; } str[j] = ‘\0‘; //printf("%s", str); }
随机数函数
int random(int a) {//随机数 int b; b = rand() % a + 1; return b; }
生成算术函数
void product_exp(int a, int b, int c, int d, int fuhao, int y, char *result) { int fenzi; int fenmu; char*ab = biaodashi(a, b); char*cd = biaodashi(c, d); FILE *fp; FILE *fp1; fp = fopen("Exercises.txt", "a"); fp1 = fopen("Answers.txt", "a"); if (b != 0 && d != 0) { switch (fuhao) { case 1: fenzi = a * d + b * c; fenmu = b * d; fprintf(fp, "%d:%s + ", y, biaodashi(a, b)); fprintf(fp, "%s = \n", biaodashi(c, d)); fprintf(fp1, "%d:%s\n", y, yuefen(fenzi, fenmu)); break; case 2: if (a*d - b * c >= 0) { fenzi = a * d - b * c; fenmu = b * d; fprintf(fp, "%d:%s - ", y, biaodashi(a, b)); fprintf(fp, "%s = \n", biaodashi(c, d)); fprintf(fp1, "%d:%s\n", y, yuefen(fenzi, fenmu)); } else { fenzi = b * c - a * d; fenmu = b * d; fprintf(fp, "%d:%s - ", y, biaodashi(c, d)); fprintf(fp, "%s = \n", biaodashi(a, b)); fprintf(fp1, "%d:%s\n", y, yuefen(fenzi, fenmu)); } break; case 3: fenzi = a * c; fenmu = b * d; fprintf(fp, "%d:%s × ", y, biaodashi(a, b)); fprintf(fp, "%s = \n", biaodashi(c, d)); fprintf(fp1, "%d:%s\n", y, yuefen(fenzi, fenmu)); break; case 4: if (c != 0) { fenzi = a * d; fenmu = b * c; fprintf(fp, "%d:%s ÷ ", y, biaodashi(a, b)); fprintf(fp, "%s = \n", biaodashi(c, d)); fprintf(fp1, "%d:%s\n", y, yuefen(fenzi, fenmu)); break; } else break; default: break; } fclose(fp); fclose(fp1); } }
约分函数
char* yuefen(int a, int b) { static char str[10] = { 0 }; for (int k = 0; k < 10; k++) //for循环初始化 { str[k] = 0; } int y = 1; char c_z[LENGTH] = { 0 }; for (int i = a; i >= 1; i--) { if (a%i == 0 && b%i == 0) { y = i; break; } } int z = a / y; int m = b / y; if (a == 0) { str[0] = ‘0‘; return str; } if (m == 1) { myitoa(z, c_z); strcat(str, c_z); return str; } else return biaodashi(z, m); }
对算术结果进行约分后放入答案文本中
表达式规范函数
char* biaodashi(int a, int b) { static char str[LENGTH] = { 0 }; for (int k = 0; k < LENGTH; k++) //for循环初始化 { str[k] = 0; } char c_a[LENGTH] = { 0 }; char c_c[LENGTH] = { 0 }; char c_b[LENGTH] = { 0 }; char c_d[LENGTH] = { 0 }; myitoa(a, c_a); //int转为char myitoa(b, c_b); if (a >= b) { int c; c = a / b; int d; d = a % b; myitoa(c, c_c); myitoa(d, c_d); { if (d == 0) { strcat(str, c_c); return str; } strcat(str, c_c); strcat(str, "\‘"); strcat(str, c_d); strcat(str, "\/"); strcat(str, c_b); return str; } } strcat(str, c_a); strcat(str, "\/"); strcat(str, c_b); return str; }
检查答案函数:
int check1() { FILE *fp0; fp0 = fopen("Grade.txt", "w+"); FILE *fp; FILE *fp1; int i = 0, j = 0, t = 0, w = 0, r = 0, l = 0, h = 0; int * rightcount = (int*)malloc((num + 2) * sizeof(int)); memset(rightcount, -1, sizeof(rightcount)); int * wrongcount = (int*)malloc((num + 2) * sizeof(int)); memset(wrongcount, -1, sizeof(wrongcount)); char StrLine[10] = {}; //每个答案最大读取的字符数 char StrLine1[10] = {}; if ((fp = fopen("Exercises.txt", "r")) == NULL) //判断文件是否存在及可读 { printf("Exercises.txt error!"); return -1; } if ((fp1 = fopen("Answers.txt", "r")) == NULL) //判断文件是否存在及可读 { printf("Answers.txt error!"); return -1; } char ch_Q = 0; char ch_A = 0; for (t = 1; t <= num; t++) {//一行 ch_Q = fgetc(fp); if (ch_Q != EOF) { while (ch_Q != ‘\n‘) {//题目 if (ch_Q == ‘=‘) { ch_Q = fgetc(fp); for (i = 0; ch_Q != ‘\n‘; i++) { ch_Q = fgetc(fp); StrLine[i] = ch_Q; } StrLine[i] = ‘\0‘; ch_A = fgetc(fp1); if (ch_A != EOF) while (ch_A != ‘\n‘) { if (ch_A == ‘:‘) {//答案 for (j = 0; ch_A != ‘\n‘; j++) { ch_A = fgetc(fp1); StrLine1[j] = ch_A; } StrLine1[j] = ‘\0‘; } else ch_A = fgetc(fp1); } } else ch_Q = fgetc(fp); } } for (int a = 0; StrLine1[a] != ‘\n‘; a++) { if (StrLine[a] != StrLine1[a]) { w++; wrongcount[l] = t;//记录错的题号 l++; wrongcount[l] = ‘\0‘; break; } else { if (StrLine[a + 1] == ‘\n‘ && StrLine1[a + 1] == ‘\n‘) { r++; rightcount[h] = t; //记录对的题号 h++; rightcount[h] = ‘\0‘; break; } } } } fprintf(fp0, "Correct: %d (", r); for (int g = 0; rightcount[g] != ‘\0‘; g++) fprintf(fp0, "%d ", rightcount[g]); fprintf(fp0, ")\n"); fprintf(fp0, "Wrong: %d (", w); for (int g = 0; wrongcount[g] != ‘\0‘; g++) fprintf(fp0, "%d ", wrongcount[g]); fprintf(fp0, ")\n"); fclose(fp0); fclose(fp); fclose(fp1); //关闭文件 free(rightcount); free(wrongcount); return 0; }
二、PSP
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
25 |
|
· Estimate |
· 估计这个任务需要多少时间 |
30
|
25 |
|
Development |
开发 |
2310 |
2140 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
240 |
200 |
|
· Design Spec |
· 生成设计文档 |
120 |
60 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
360 |
60 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
20 |
|
· Design |
· 具体设计 |
120 |
120 |
|
· Coding |
· 具体编码 |
720 |
960 |
|
· Code Review |
· 代码复审 |
360 |
360 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
360 |
360 |
|
Reporting |
报告 |
90 |
90 |
|
· Test Report |
· 测试报告 |
30 |
30 |
|
· Size Measurement |
· 计算工作量 |
30 |
30 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
合计 |
|
2430 |
2255 |
三、效能分析和覆盖率测试
使用vs2017自带的性能探测器进行i效能分析,如下图
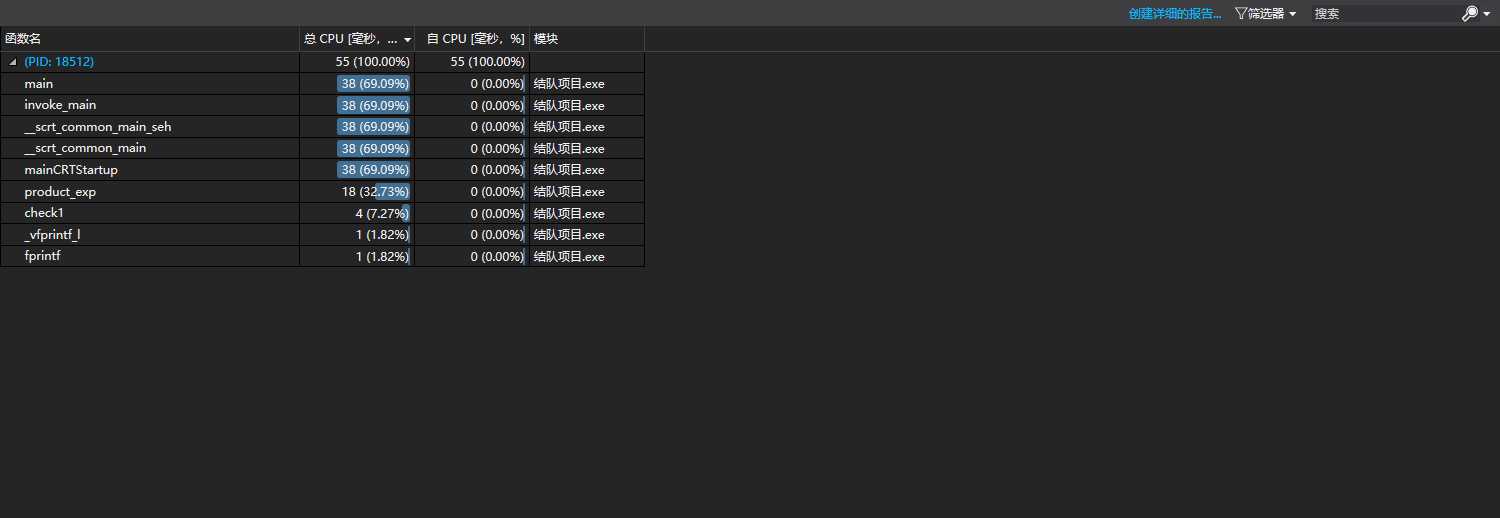
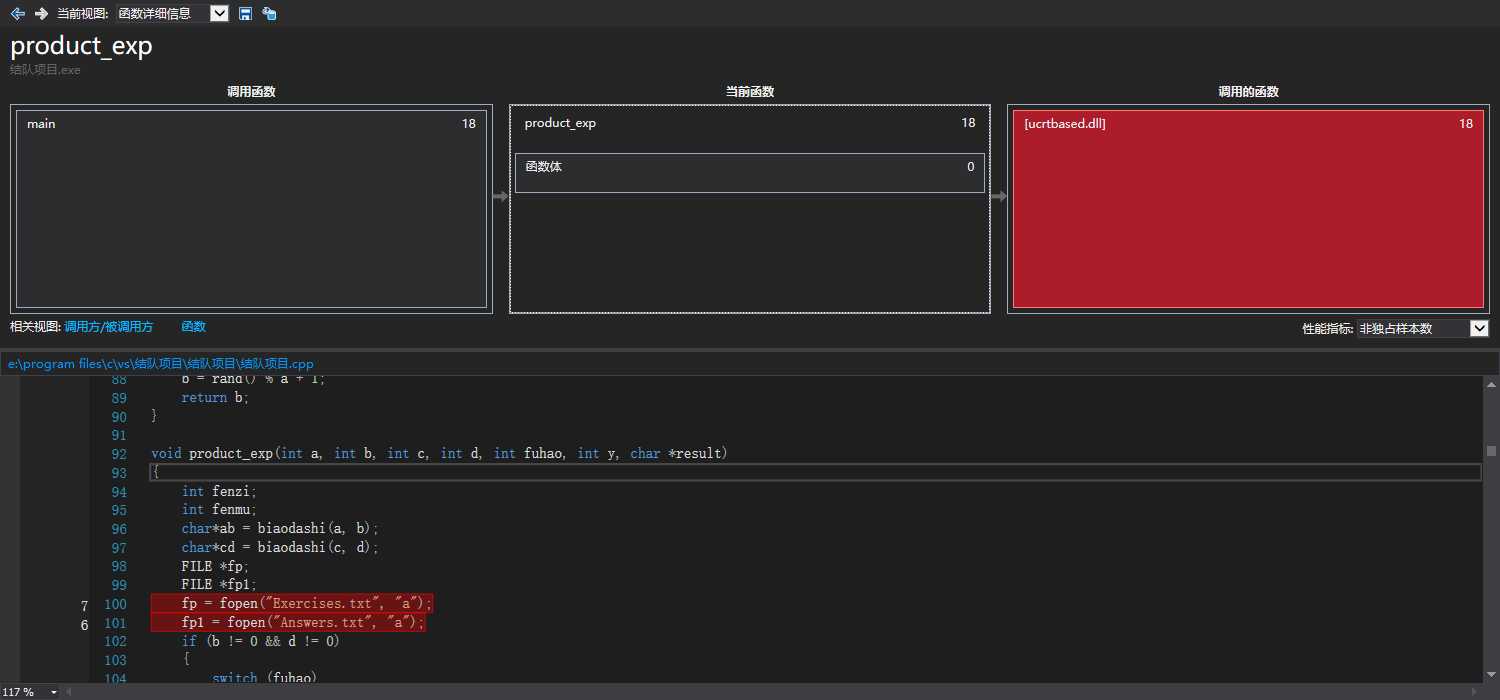
通过两张图,我们能发现,主函数占用了6成的时间,而子函数product_exp占用3成,检查函数不到一成,原因是我们含有一个生成表达式的函数cbiaodashi()和约分函数yuefen(),而这两个函数都在product_exp中进行的,所以占用时间多。
下图为代码覆盖率测试的结果,结果表明覆盖率为93%,原因是有一些判断意外情况的代码没有执行。

四、设计过程
设计之初,我们首先想到的问题是如何规范化所有数字以及符号,因为考虑到所有的分数有规定的格式要求,索性就将所有生成的数先写成分数,再做处理。为此我们需要一个专门的函数去处理随机生成的分子和分母,将他们以规定格式返回,这样就算是解决了数字的问题。随后我们经过测试发现函数输出出来的数字无法进行约分,因此我们又专门写了一个约分函数,以便确定运算出来的答案是最简,并写入answer.txt。设计时,我们的大体思路是统一将生成的题目放入Exercises.txt,同时将答案放入answer.txt,用户需要按照格式将答案写入Exercises.txt,写完后启用cheak函数来检查用户写入的答案,将对错情况单独写入一个新的Grade.txt中。在过程之中,我们遇到了主要问题应该是cheak函数的编写,我们两个人分别写了一个cheak函数,然后交换了思路,最后决定在谭艺的cheak函数中进行改动并采用。
五、代码说明
大体函数:

其中random函数用来产生随机数,biaodashi函数用来规范分数,yuefen函数用来对结果进行约分,product_exp函数用来产生表达式并且将表达式以及答案写入对应的txt文件中,cheak函数用来检查写入的答案,检查结果在对应的Grade.txt中。其中关键的代码应该算是cheak函数,我们将用户写入的答案放入一个数组中,并且将答案放入另一个数组,最后对比俩个数组,得到Grade.txt中的内容。在Exercises.txt中检测用户的答案对我们来说是一个比较有趣的点,我们用fgetc去检测每道题目的”=“号,以及”\n“号来确认我们数组中装的是用户写入的答案,而装正确答案的数组中我们用”:“号和”\n“号来检测。
具体代码在github中可以找到。
六、测试运行
以10以内的数字产10条式子,其中题号1、3、8、10是手动输入了正确答案,其他题目均不填。
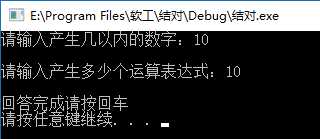



结果符合预期。
代码之所以能保证正确,是因为经过两人长时间的调试与检查。
七、项目小结
唐崇珂:本次结对项目中,我主要负责了product_exp,biaodashi,yuefen,myitoa函数的编写。因为本道题目中biaodashi函数为基本中的基本,所以在项目开始之初,我和谭艺就曾多次交换意见,查询资料后修改biaodashi函数,才能保证其得到正确的值,以及返回正确的类型,这次合作并没有太多分歧,而是彼此交换意见,然后再思考,再改动。这次的项目对我来说是一次全新的学习模式,我学会了很多有关合作,和编写代码的经验。
谭艺:在本次结对编程中,和唐崇珂合作让我受益匪浅,唐崇珂的能力在我之上,在我打代码的时候唐同学在我身旁监督和检查我的代码,并且给出很多优化的代码方案和想法,再此之前我打代码都是以自己的角度看待问题,容易陷入一个混乱的状态,导致代码也是混乱的,但是有唐崇珂同学在旁边协助的时候感觉一切都非常简单,并且享受这种合作的乐趣。遗憾的是我的实力不够,拖慢了进度,导致程序只能生成一个运算符,并且使用参数控制式子的大小和多少也没有完成,但是这次结对项目让我收获很多。

原文:https://www.cnblogs.com/wuchengttt/p/11688647.html