单库时,系统中很多列表和详情页所需数据可以简单通过SQL join关联表查询;然而多库情况下,数据可能分布在不同的节点/实例上,不能跨库使用join,此时join带来的问题就很棘手了。

我们在开发过程中,连接数据库一个连接也是只能连一个数据库这个是常规操作,例如
db1 = pymysql.connect("11.22.33.44", "yerik", "mimajiubiekanla", "shujukuming1", port=3306)如果我们要查询另一个数据库呢?不就要,再建立一个连接嘛
db2 = pymysql.connect("55.66.77.88", "yerik", "mimajiubiekanla", "shujukuming2", port=3306)这个怎么可能用join操作,可能有读者想要杠一下,说,可以通过xx操作在代码层面进行开发,但是,这样的代码可读性有多强?另外就代码审查来说,也不会让你这么写,万一某一天你甩锅离职了,这天花乱坠的代码,谁受得了?
不过嘛,办法总比困难多的——视图。利用视图,我们可以非常简单的实现这样的跨库查询的需求。我们知道所谓视图,其实就是存储的查询语句,当调用的时候,产生结果集,视图充当的是虚拟表的角色。因此:
一开始我也是被我这个想法惊讶到了,总觉得跨库建视图太过于惊悚了,毕竟实践是检验真理的唯一标准嘛,随手就在navicat上面建立一个视图,之后运行
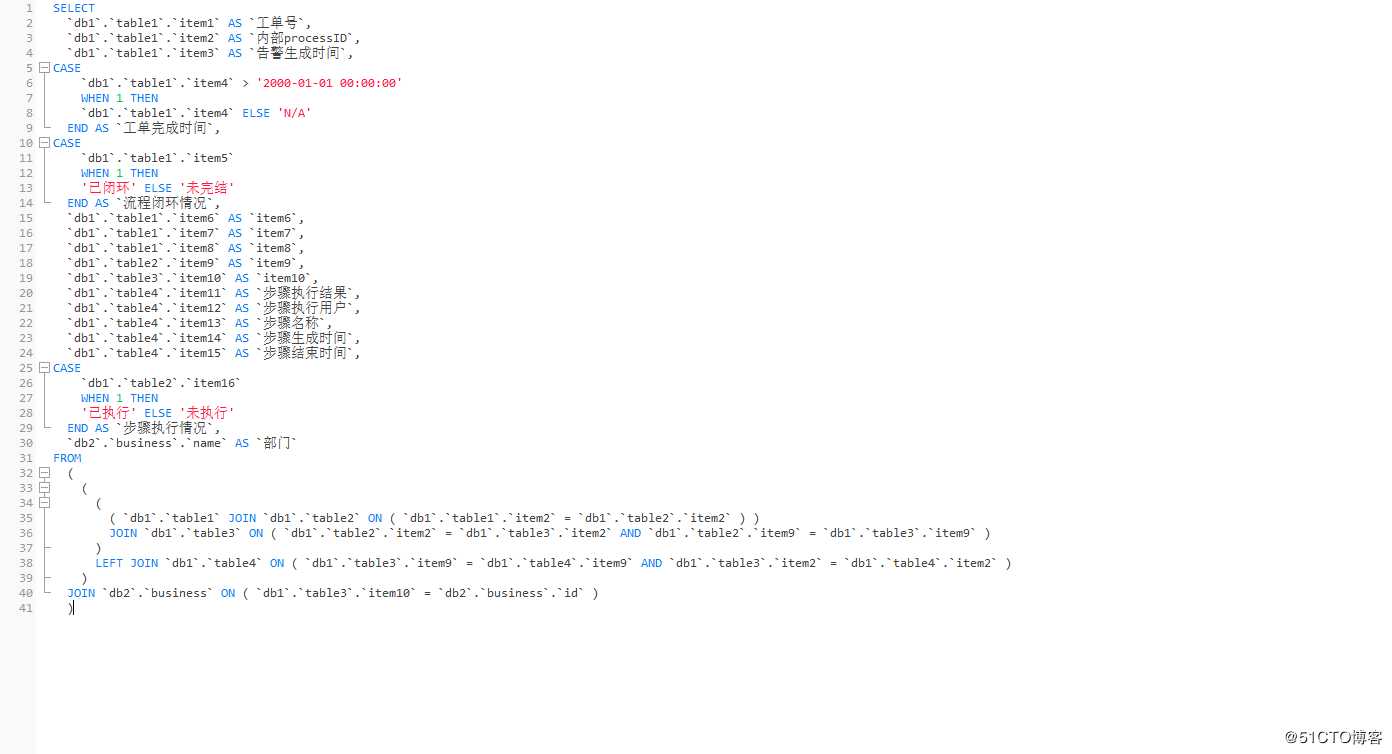
非常神奇~~那问题这样就解决啦,还是一条SQL语句就可以解决问题了
通过这个思路,其实可以继续推广:跨表联查,建个视图,跨库联查,建个视图。建就完事了。另外这个操作其实还需要考虑数据同步的问题,因为是多库联查,如果数据不一致会是灾难的,这个具体问题要具体分析,加锁或者配置同步策略这些都是常规方案,由于我没有这个需求,就不展开讨论啦。
这个案例对我来说很有感触
原文:https://blog.51cto.com/yerikyu/2443401