Object Detection
Bounding box(最小外截距项)和category label
Difference with the other task:
- single task: classification <---> classification and localization
- multi-task: object detection <---> instance segmentation
contest
imagenet large scale visual recognition challenge
URL: http://image-net.org/challenges/LSVRC/2017/index
- 2013-2017, 200 category, multi-category and bounding box each image
- image classification
- scene classification
- object localization
- scene parsing
PASCAL VOC
URL: http://host.robots.ox.ac.uk/pascal/VOC/
eject Detection
Bounding box(最小外截距项)和category label
Difference with the other task:
- single task: classification <---> classification and localization
- multi-task: object detection <---> instance segmentation
contest
imagenet large scale visual recognition challenge
URL: http://image-net.org/challenges/LSVRC/2017/index
- 2013-2017, 200 category, multi-category and bounding box each image
- image classification
- scene classification
- object localization
- scene parsing
PASCAL VOC
URL: http://host.robots.ox.ac.uk/pascal/VOC/
- evolution:R-CNN --> SPP-Net --> Fast R-CNN --> Faster R-CNN --> YOLO --> SSD -->R-FCN
R-CNN
- Region proposal: devisity boxing with different position and size
- Classification: CNN classificator, heavy calculation
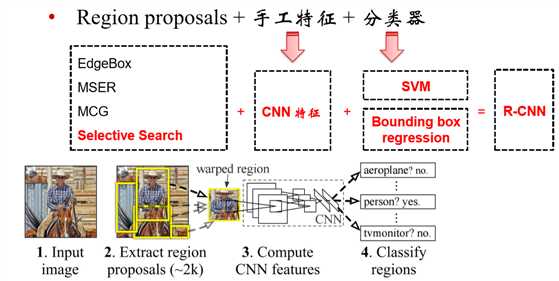
$ $
R-CNN model
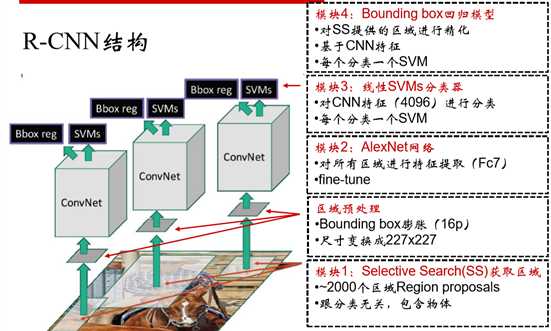 $ $
R-CNN in models
$ $
R-CNN in models
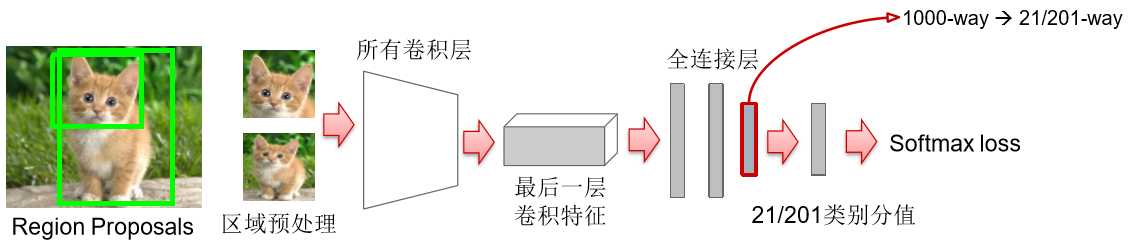
- pre-train a imageNet CNN model --> Model1
- fine-tune proposal regions with SS(selective search) -->Model2
-- Log loss
-- softmax layer --> (N+1) way
-- 32 positive samples (N classes): IoU with Ground truth > 0.5
-- 96 negative samples (1 classes): IoU < 0.5
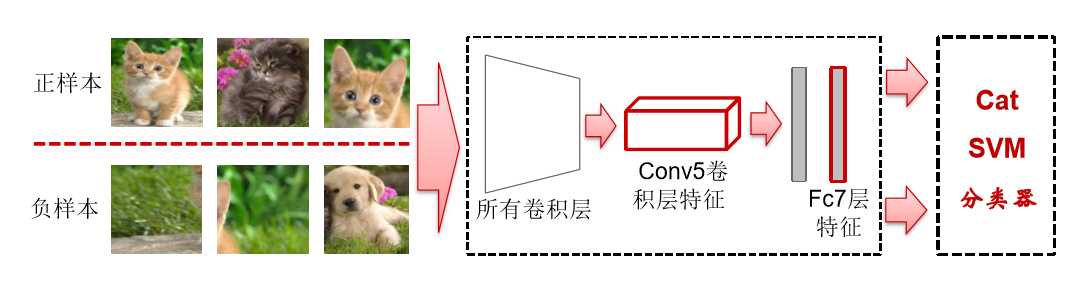
- based on Model2, on its Fc7 train linear SVM classificator --> Model3
-- Hinge loss
-- each class with a SVM classficator (N classes)
-- postive samples: all Ground-truth areas
-- negative samples: IoU < 0.3 of SS of SS areas
- with Model2, on Fc7, train Bounding box regression model
-- improve bounding box accuracy
-- a regression model for each class (N class)
--- bounding box in SS regression:P --> G
--- input:
----- bounding box \({P^i, G^i}_{i=1,...,N}\)
----- center: \((x, y)\), width and height:\((w, h)\)
----- $ P^i=(P^i_x, P^i_y, P^i_w, P^i_h), P^i=(P^i_x, P^i_y, P^i_w, P^i_h)$
----- feature for Conv5 of CNN: \(\phi_5(P)\)
--- IoU for P > 0.6
--- Squared loss:
----- \({{\rm{W}}_*} =\mathop {\arg \min }\limits_{{{{\rm{\hat w}}}_*}} {( {t_o^i - {{{\rm{\hat w}}}_o}{\phi_5}( {{P^i}} )} )^2} + \lambda ||{{\rm{\hat w}}_*}||^2\)
----- where \(t_x = (G_x-P_x)/{P_w}, t_y = (G_y-P_y)/{P_y}, t_w = log(G_w/{P_w}), t_h= log(G_h/{P_h})\)
--- test process:
----- \({\hat G}_x = P_x d_x(P)+P_x, {\hat G}_y = P_y d_y(P)+P_y, {\hat G}_w = P_w exp(d_w(P)), d_*(P) = {\rm}^{\rm T}_* \phi_5 (P)\)
explain for cost function: Ref
- R-CNN test
-- SS (fast model) get about 2000 proposal areas/images
-- resize(expand and scaling) them into size of 227*227
-- Model2 to get 2 feature map: proposal areas subset and regressed Bbox
--- for each class
1). Fc7 feature --> SVM classificator --> class score
2). with IoU > 0.5, get non-redundant area subset
- reorder all areas in decrease order with the score
- remove redundant areas: IoU > 0.5 with the area of highest score
- save the highest score area, the left areas to candidate set
3). conv5 --> Bounding box regression model --> regressed Bbox
4). with regressed Bboxs fine tune ares subset
- performance evaluation
- mAp@5 (mean Average Precision)
-- calculate AP for each class, then get mean value
- AP is the area of Precision-Recall Curve
- precision: TP/(TP+FP)
- recall: TP/(TP+FN)
** True positive area: IoU >=0.5 with ground Truth
** False positive area: IoU < 0.5
** False negative area: unmarked Gound truth area:
** IoU = Intersection over Unit = (AnB)/(AUB)
- defect:
- too much time for training process
-- fine-tune (18) + feature extraction (63) + SUM/Box training (3)
- too much time for test: a VGG16 47S
- complex and multi-training processes
[Tadeas] Image Detection
原文:https://www.cnblogs.com/tadeas/p/11669158.html