第一章 监督学习
如果你是在windows环境下,建议直接使用anaconda,这里里面集成了一些常用的Python库。
如果是在其他环境下,就更方便了,保证这下面几个已经安装就好了。
NumPy: http://docs.scipy.org/doc/numpy-1.10.1/user/install.html
scikit-learn: http://scikit-learn.org/stable/install.html
matplotlib: http://matplotlib.org/1.4.2/users/installing.html
其实在机器学习的整个过程中,数据预处理的过程是最麻烦和繁琐的,同样对后面的结果也会产生很大的影响。一定要重视!!!
import numpy as np
from sklearn import preprocessing
data = np.array([[3, -1.5, 2, -5.4], [0, 4, -0.3, 2.1], [1, 3.3, -1.9, -4.3]])
dataarray([[ 3. , -1.5, 2. , -5.4],
[ 0. , 4. , -0.3, 2.1],
[ 1. , 3.3, -1.9, -4.3]])data_standardized = preprocessing.scale(data)
print("Mean = ", data_standardized.mean(axis = 0))
print("Std deviation = ", data_standardized.std(axis = 0))
data_standardizedMean = [ 5.55111512e-17 -1.11022302e-16 -7.40148683e-17 -7.40148683e-17]
Std deviation = [1. 1. 1. 1.]array([[ 1.33630621, -1.40451644, 1.29110641, -0.86687558],
[-1.06904497, 0.84543708, -0.14577008, 1.40111286],
[-0.26726124, 0.55907936, -1.14533633, -0.53423728]])data_scaler = preprocessing.MinMaxScaler(feature_range = (0, 1))
data_scaled = data_scaler.fit_transform(data)
data_scaledarray([[1. , 0. , 1. , 0. ],
[0. , 1. , 0.41025641, 1. ],
[0.33333333, 0.87272727, 0. , 0.14666667]])data_normalized = preprocessing.normalize(data, norm = 'l1')
data_normalizedarray([[ 0.25210084, -0.12605042, 0.16806723, -0.45378151],
[ 0. , 0.625 , -0.046875 , 0.328125 ],
[ 0.0952381 , 0.31428571, -0.18095238, -0.40952381]])data_binarized = preprocessing.Binarizer(threshold = 2).transform(data)
data_binarizedarray([[1., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 1., 0., 0.]])encoder = preprocessing.OneHotEncoder()
# 给数据进去,根据每列数据得到编码值
encoder.fit([
[0, 2, 1, 12],
[1, 3, 5, 3],
[2, 3, 2, 12],
[1, 2, 4, 3]
])
encoded_vector = encoder.transform([ [2, 3, 5, 3] ]).toarray()
encoded_vectorarray([[0., 0., 1., 0., 1., 0., 0., 0., 1., 1., 0.]])import numpy as np
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
input_classes = ['audi', 'ford', 'audi', 'toyota', 'ford', 'bmw']
label_encoder.fit(input_classes)
for i, item in enumerate(label_encoder.classes_):
print(item, '-->', i)audi --> 0
bmw --> 1
ford --> 2
toyota --> 3labels = ['toyota', 'ford', 'audi']
encoded_labels = label_encoder.transform(labels)
print("labels = ", labels)
print("encoded_labels = ", encoded_labels)labels = ['toyota', 'ford', 'audi']
encoded_labels = [3 2 0]逆向操作,根据数字得到原始的字串
encoded_labels = [2, 1, 0, 3, 1]
decoded_labels = label_encoder.inverse_transform(encoded_labels)
print("encoded_labels = ", encoded_labels)
print("decoded_labels = ", decoded_labels)encoded_labels = [2, 1, 0, 3, 1]
decoded_labels = ['ford' 'bmw' 'audi' 'toyota' 'bmw']import sys
import numpy as npfilename = "data_singlevar.txt"
X = []
y = []
with open(filename, 'r') as f:
for line in f.readlines():
xt, yt = [float(i) for i in line.split(',')]
X.append(xt)
y.append(yt)num_training = int(0.8 * len(X))
num_test = len(X) - num_training
# train data
X_train = np.array(X[:num_training]).reshape((num_training, 1))
y_train = np.array(y[:num_training])
# test_data
X_test = np.array(X[num_training:]).reshape((num_test, 1))
y_test = np.array(y[num_training:])from sklearn import linear_model
# 创建线性回归对象
linear_regressor = linear_model.LinearRegression()
# 用训练数据集训练样本
linear_regressor.fit(X_train, y_train)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)import matplotlib.pyplot as plt
# 在jupyter中直接显示图形
#%matplotlib inline y_train_pred = linear_regressor.predict(X_train)
plt.figure()
plt.scatter(X_train, y_train, color = 'green')
plt.plot(X_train, y_train_pred, color='red', linewidth=4)
plt.title('Training data')
plt.show()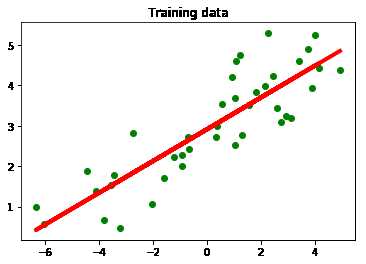
y_train_predarray([4.850913 , 2.29390029, 1.16834408, 0.5369345 , 2.43508504,
1.52130596, 3.05472923, 1.64288172, 3.4273001 , 3.76457478,
4.06655328, 2.552739 , 2.5566608 , 3.39984751, 3.52534506,
1.28991984, 4.38421897, 4.54109091, 3.04296383, 4.25087781,
3.80379277, 3.93321212, 3.32925513, 3.32141154, 3.9881173 ,
2.63509677, 1.83504985, 3.1292434 , 1.56052395, 3.34102053,
3.88222874, 0.42320234, 3.63123363, 2.64686217, 1.4114956 ,
2.11741935, 4.14106745, 3.27434995, 4.49010753, 4.43912415])y_test_pred = linear_regressor.predict(X_test)
plt.scatter(X_test, y_test, color = 'green')
plt.plot(X_test, y_test_pred, color = 'red', linewidth = 2)
plt.title('Test Data')Text(0.5, 1.0, 'Test Data')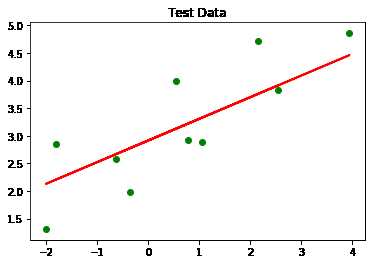
import sklearn.metrics as sm
print("Mean absolute error = ", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error = ", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error = ", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explained variance score = ", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print ("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))Mean absolute error = 0.54
Mean squared error = 0.38
Median absolute error = 0.54
Explained variance score = 0.68
R2 score = 0.68import pickle as pickle
output_model_file = 'saved_model.pkl'
with open(output_model_file, 'wb') as f:
pickle.dump(linear_regressor, f)with open(output_model_file, 'rb') as f:
model_linregr = pickle.load(f)
y_test_pred_new = model_linregr.predict(X_test)
print("", round(sm.mean_absolute_error(y_test, y_test_pred_new), 2)) 0.54原文:https://www.cnblogs.com/zou107/p/11703229.html